Влияние ИИ на рынок труда - исследование от Anthropic
Перевод на основании исследования Антропик https://www.anthropic.com/research/labor-market-impacts
- Мы представляем новую метрику риска вытеснения работников ИИ — наблюдаемую экспозицию (observed exposure), которая объединяет теоретическую способность больших языковых моделей (LLM) и данные о реальном использовании, придавая больший вес автоматизированным (а не вспомогательным) и связанным с работой сценариям применения.
- ИИ далёк от достижения своего теоретического потенциала: фактическое покрытие задач остаётся лишь малой долей от того, что теоретически возможно.
- Профессии с более высокой наблюдаемой экспозицией, согласно прогнозам Бюро статистики труда США (BLS), будут расти медленнее вплоть до 2034 года.
- Работники в наиболее экспонированных профессиях с большей вероятностью оказываются старше, женщинами, имеют более высокий уровень образования и более высокую заработную плату.
- Мы не обнаруживаем систематического роста безработицы среди высокоэкспонированных работников с конца 2022 года, однако находим косвенные свидетельства того, что найм молодых работников в экспонированных профессиях замедлился.
Введение
Быстрое распространение искусственного интеллекта порождает волну исследований, направленных на измерение и прогнозирование его воздействия на рынки труда. Однако исторический опыт предыдущих подходов даёт основания для сдержанности.
Например, одна из известных попыток измерить уязвимость рабочих мест к офшорингу определила, что примерно четверть рабочих мест в США находится в зоне риска, но спустя десятилетие большинство из этих рабочих мест продолжали демонстрировать здоровый рост занятости. Собственные прогнозы правительства по росту занятости, хотя и верны по направлению, добавили мало прогностической ценности сверх линейной экстраполяции прошлых трендов. Даже ретроспективно влияние крупных экономических потрясений на рынок труда часто остаётся неочевидным. Исследования, посвящённые влиянию промышленных роботов на занятость, приходят к противоположным выводам, а масштаб потерь рабочих мест, приписываемых «торговому шоку» со стороны Китая, продолжает оставаться предметом дискуссий.¹
В данной работе мы представляем новую концептуальную основу для понимания воздействия ИИ на рынок труда и тестируем её на ранних данных, обнаруживая ограниченные свидетельства того, что ИИ уже повлиял на занятость. Наша цель — разработать подход к измерению того, как ИИ влияет на занятость, и периодически возвращаться к этим анализам. Этот подход не охватит все каналы, через которые ИИ может трансформировать рынок труда, но, закладывая эту основу сейчас, до того как проявятся значимые эффекты, мы надеемся, что будущие результаты будут надёжнее выявлять экономические потрясения, чем постфактум-анализы.
Возможно, последствия внедрения ИИ окажутся неоспоримыми. Данная концептуальная рамка наиболее полезна именно тогда, когда эффекты неоднозначны — и может помочь выявить наиболее уязвимые рабочие места ещё до того, как вытеснение станет видимым.
Контрфактические сценарии
Каузальный вывод проще делать, когда эффекты велики и внезапны. Пандемия COVID-19 и сопутствующие политические меры вызвали экономические потрясения настолько резкие, что для ответа на многие вопросы не требовались сложные статистические подходы. Например, уровень безработицы резко подскочил в первые недели пандемии, что практически не оставляло места для альтернативных объяснений.
Однако воздействие ИИ может быть менее похоже на COVID и более похоже на влияние интернета или торговли с Китаем. Эффекты могут быть неочевидны сразу по агрегированным данным о безработице; такие факторы, как торговая политика и фаза делового цикла, могут затруднять интерпретацию трендов.
Один из распространённых подходов — сравнение результатов между работниками, фирмами или отраслями с большей или меньшей экспозицией к ИИ, чтобы изолировать эффект ИИ от смешивающих факторов.² Экспозиция обычно определяется на уровне задач: ИИ может проверять домашние задания, но не управлять классом, например, поэтому учителя считаются менее экспонированными, чем работники, чья работа целиком может выполняться удалённо.
Наша работа следует этому подходу, основанному на задачах, включая метрики теоретической способности ИИ и реального использования, прежде чем агрегировать данные до уровня профессий.³
Измерение экспозиции
Наш подход объединяет данные из трёх источников:
- База данных O*NET, которая перечисляет задачи, связанные с примерно 800 уникальными профессиями в США.
- Наши собственные данные об использовании (измеренные в рамках Индекса экономики Anthropic).
- Оценки экспозиции на уровне задач от Eloundou et al. (2023), которые измеряют, теоретически возможно ли для LLM выполнить задачу как минимум вдвое быстрее.
Метрика β от Eloundou et al. оценивает задачи по простой шкале: 1, если задача может быть ускорена вдвое исключительно с помощью LLM; 0,5, если для этого требуются дополнительные инструменты или программное обеспечение, построенное поверх LLM; и 0 в противном случае.⁴
Почему фактическое использование может отставать от теоретической возможности? Некоторые задачи, теоретически выполнимые, могут не проявляться в данных об использовании из-за ограничений моделей. Другие могут медленно распространяться из-за правовых ограничений, специфических требований к программному обеспечению, этапов человеческой верификации или иных барьеров. Например, Eloundou et al. отмечают задачу «Авторизовать повторную выдачу лекарств и предоставлять информацию о рецептах в аптеки» как полностью экспонированную (β=1). Мы не наблюдали, чтобы Claude выполнял эту задачу, хотя оценка представляется верной в том смысле, что теоретически LLM мог бы ускорить её выполнение.
Тем не менее, эти метрики теоретической способности и фактического использования сильно коррелируют. Как показано на Рисунке 1, 97% задач, наблюдаемых в предыдущих четырёх отчётах Экономического индекса, попадают в категории, оценённые Eloundou et al. как теоретически осуществимые (β=0,5 или β=1,0).
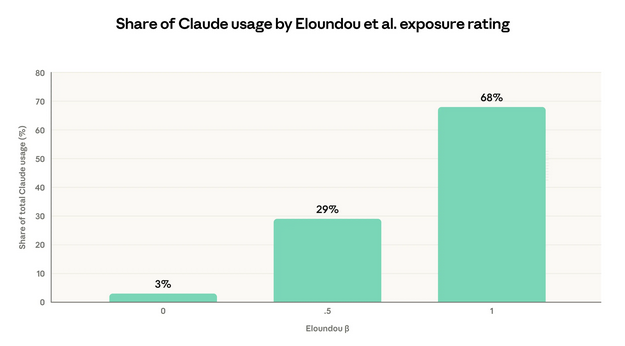 Рисунок 1: Доля использования Claude по рейтингу экспозиции задач от Eloundou et al.
Рисунок 1: Доля использования Claude по рейтингу экспозиции задач от Eloundou et al.
На этом рисунке показано распределение использования Claude по задачам O*NET, сгруппированным по их теоретической экспозиции к ИИ. Задачи, оценённые как β=1 (полностью осуществимые исключительно с помощью LLM), составляют 68% наблюдаемого использования Claude, тогда как задачи с β=0 (неосуществимые) составляют всего 3%. Данные об использовании Claude взяты из предыдущих четырёх отчётов Экономического индекса.
Новая метрика профессиональной экспозиции
Наша новая метрика — наблюдаемая экспозиция — призвана количественно оценить: из тех задач, которые LLM теоретически могут ускорить, какие реально используются в автоматизированном режиме в профессиональных условиях? Теоретическая способность охватывает значительно более широкий спектр задач. Отслеживая сужение этого разрыва, наблюдаемая экспозиция даёт представление об экономических изменениях по мере их проявления.
Наша метрика качественно отражает несколько аспектов использования ИИ, которые, как мы полагаем, предсказывают влияние на рабочие места. Экспозиция профессии выше, если:
- Её задачи теоретически выполнимы с помощью ИИ;
- Её задачи демонстрируют значительное использование в рамках Индекса экономики Anthropic⁵;
- Её задачи выполняются в контексте, связанном с работой;
- Она имеет относительно более высокую долю паттернов автоматизированного использования или реализации через API;
- Задачи, затронутые ИИ, составляют бо́льшую долю от общей роли⁶.
Математические детали приведены в Приложении. Мы считаем задачи, теоретически выполнимые с помощью LLM, «покрытыми», если они демонстрировали достаточное использование в рабочем контексте в трафике Claude. Затем мы корректируем оценку с учётом способа выполнения задачи: полностью автоматизированные реализации получают полный вес, тогда как вспомогательное использование — половинный вес. Наконец, метрики покрытия на уровне задач усредняются до уровня профессии с учётом доли времени, затрачиваемого на каждую задачу.
Рисунок 2 показывает наблюдаемую экспозицию (красным) в сравнении с β от Eloundou et al. (синим), иллюстрируя разницу между теоретическим потенциалом и фактическим использованием на нашей платформе, сгруппированным по широким профессиональным категориям. Мы рассчитываем это, сначала усредняя до уровня профессии с учётом нашей метрики доли времени, затем усредняя до уровня категории профессии с учётом общей занятости. Например, метрика β показывает потенциал проникновения LLM в большинство задач в категориях «Компьютеры и математика» (94%) и «Офис и администрирование» (90%).
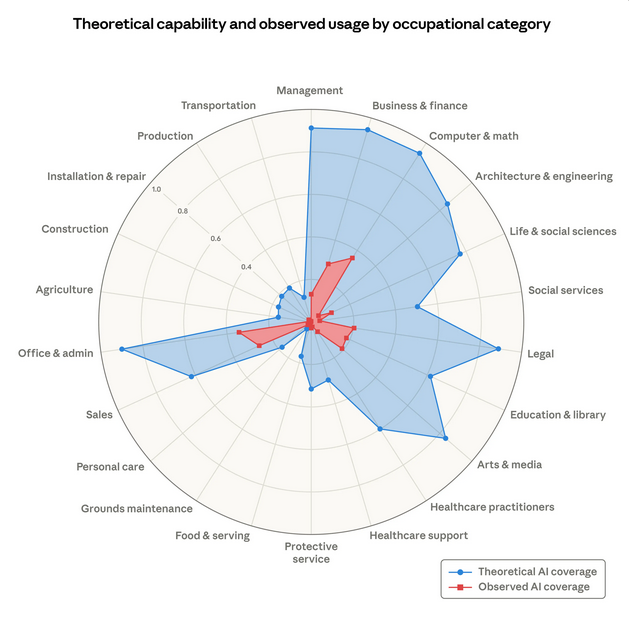 Рисунок 2: Теоретическая способность и наблюдаемая экспозиция по профессиональным категориям
Рисунок 2: Теоретическая способность и наблюдаемая экспозиция по профессиональным категориям
Доля рабочих задач, которые LLM теоретически могли бы выполнять (синяя область), и наша собственная метрика покрытия рабочих мест, выведенная из данных об использовании (красная область).
Красная область, отображающая использование LLM на основе Индекса экономики Anthropic, показывает, как люди используют Claude в профессиональных условиях. Покрытие демонстрирует, что ИИ далёк от реализации своего теоретического потенциала. Например, в настоящее время Claude покрывает лишь 33% всех задач в категории «Компьютеры и математика».
По мере развития возможностей, расширения внедрения и углубления развёртывания красная область будет расти, приближаясь к синей. Также остаётся значительная непокрытая область: многие задачи, разумеется, остаются за пределами досягаемости ИИ — от физических сельскохозяйственных работ, таких как обрезка деревьев и управление сельхозтехникой, до юридических задач, таких как представительство клиентов в суде.
Рисунок 3 показывает десять профессий, наиболее экспонированных согласно этой метрике. В соответствии с другими данными, демонстрирующими активное использование Claude для написания кода, на первом месте находятся Программисты с покрытием 75%, за ними следуют Специалисты по обслуживанию клиентов, чьи основные задачи мы всё чаще наблюдаем в трафике сторонних API. Наконец, Операторы ввода данных, чья основная задача — чтение исходных документов и ввод данных — демонстрирует значительную автоматизацию, имеют покрытие 67%.
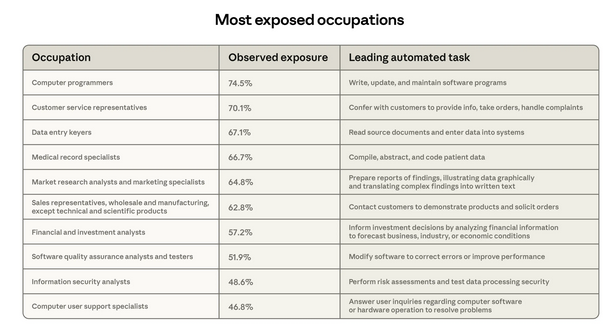 Рисунок 3: Наиболее экспонированные профессии
Рисунок 3: Наиболее экспонированные профессии
Десять наиболее экспонированных профессий согласно нашей метрике покрытия задач.
На нижнем конце спектра 30% работников имеют нулевое покрытие, поскольку их задачи появлялись в наших данных слишком редко, чтобы достичь минимального порога. В эту группу входят, например, повара, механики мотоциклов, спасатели, бармены, посудомойщики и гардеробщики.
Как экспозиция соотносится с прогнозируемым ростом занятости и характеристиками работников
Бюро статистики труда США (BLS) регулярно публикует прогнозы занятости; последний набор, опубликованный в 2025 году, охватывает прогнозируемые изменения занятости по каждой профессии с 2024 по 2034 год. На Рисунке 4 мы сравниваем нашу метрику покрытия на уровне рабочих мест с их прогнозами.
Регрессия на уровне профессий, взвешенная по текущей занятости, показывает, что прогнозы роста несколько слабее для рабочих мест с более высокой наблюдаемой экспозицией. На каждые 10 процентных пунктов увеличения покрытия прогноз роста BLS снижается на 0,6 процентных пункта. Это обеспечивает определённую валидацию: наши метрики согласуются с независимо полученными оценками аналитиков рынка труда, хотя связь и невелика. Интересно, что при использовании исключительно метрики Eloundou et al. такой корреляции не наблюдается.
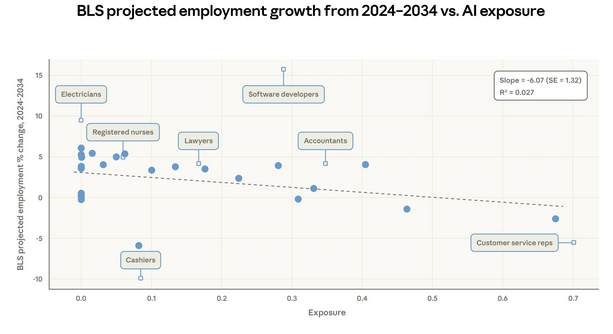 Рисунок 4: Прогнозируемый рост занятости BLS на 2024–2034 гг. в сравнении с наблюдаемой экспозицией
Рисунок 4: Прогнозируемый рост занятости BLS на 2024–2034 гг. в сравнении с наблюдаемой экспозицией
Бинированный точечный график с 25 равновеликими бинами. Каждая сплошная точка показывает среднюю наблюдаемую экспозицию и прогнозируемое изменение занятости для одного из бинов. Пунктирная линия показывает простую линейную регрессию, взвешенную по текущим уровням занятости. Маленькие ромбы отмечают отдельные примеры профессий для иллюстрации.
Рисунок 5 показывает характеристики работников в верхнем квартиле экспозиции и 30% работников с нулевой экспозицией за три месяца до выпуска ChatGPT — с августа по октябрь 2022 года — с использованием данных Текущего обследования населения (Current Population Survey).⁷ Группы существенно различаются. Более экспонированная группа на 16 процентных пунктов чаще состоит из женщин, на 11 процентных пунктов чаще — из белых, и почти в два раза чаще — из азиатов. В среднем они зарабатывают на 47% больше и имеют более высокий уровень образования. Например, люди с учёными степенями составляют 4,5% в неэкспонированной группе, но 17,4% в наиболее экспонированной — почти четырёхкратная разница.
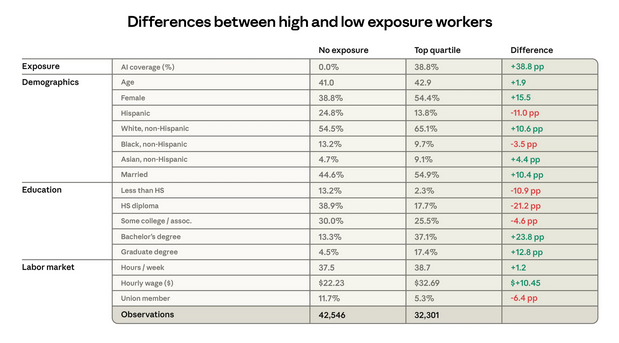 Рисунок 5: Различия между работниками с высокой и низкой экспозицией, Текущее обследование населения
Рисунок 5: Различия между работниками с высокой и низкой экспозицией, Текущее обследование населения
Приоритизация результатов
Имея эти метрики экспозиции, возникает вопрос: на что именно следует обращать внимание? Исследователи использовали различные подходы. Например, Gimbel et al. (2025) отслеживают изменения в профессиональной структуре с помощью Текущего обследования населения. Их аргумент состоит в том, что любая значимая реструктуризация экономики под влиянием ИИ проявилась бы в изменении распределения рабочих мест.¹ (Они обнаруживают, что на данный момент изменения были незначительными.) Brynjolfsson et al. (2025) анализируют уровни занятости с разбивкой по возрастным группам, используя данные компании по обработке платёжных ведомостей ADP, тогда как Acemoglu et al. (2022) и Hampole et al. (2025) используют данные о вакансиях от Burning Glass (ныне Lightcast) и Revelio соответственно.
Мы фокусируемся на безработице как на приоритетном результате, поскольку она наиболее непосредственно отражает потенциальный экономический ущерб — работник, который безработен, хочет найти работу, но ещё не сделал этого. В этом случае данные о вакансиях и занятости не обязательно сигнализируют о необходимости политических мер: снижение числа вакансий для высокоэкспонированной роли может компенсироваться ростом открытых позиций в смежной области. Наиболее вредные изменения на рынке труда, вызванные ИИ, аргументированно должны включать период роста безработицы, поскольку вытесняемые работники ищут альтернативы. Текущее обследование населения хорошо подходит для отслеживания этого, поскольку безработные респонденты сообщают о своей предыдущей работе и отрасли.
Первоначальные результаты
Далее мы изучаем тренды в безработице, сопоставляя наши метрики на уровне профессий с респондентами Текущего обследования населения.
Ключевой вопрос при интерпретации нашей метрики покрытия: каких работников следует считать «подвергшимися воздействию»? Следует ли ожидать изменений в занятости уже при 10% покрытии задач? Gans и Goldfarb (2025) показывают, что если модель O-ring лучше всего описывает рабочие места, эффекты занятости могут проявляться только тогда, когда все задачи в той или иной степени затронуты ИИ. Hampole et al. (2025) утверждают, что средняя экспозиция снижает спрос на труд, но концентрация экспозиции лишь в определённых задачах может противодействовать этому эффекту. А Autor и Thompson (2025) подчёркивают уровень экспертизы, требуемый для оставшихся задач.
Стремясь к простоте и учитывая, что нас в наибольшей степени беспокоят крупные воздействия, мы центрируем наш анализ на идее, что эффекты должны ощущаться сильнее всего в группах с наибольшей средней экспозицией. Мы сравниваем работников в верхнем квартиле покрытия задач, взвешенного по времени, с работниками в нижнем. Если возможности ИИ будут быстро развиваться, покрытие задач может стать высоким и для более низких процентилей, что сделало бы более полезным использование абсолютного порога. Однако мы исходим из предположения, что воздействие в первую очередь затронет наиболее экспонированных работников, и представляем результаты с варьированием порога, используемого для определения «лечения».
Верхняя панель Рисунка 6 показывает сырые тренды уровня безработицы с 2016 года для работников в верхнем квартиле экспозиции и неэкспонированной группы. Во время пандемии COVID менее экспонированные к ИИ работники — которые с большей вероятностью имеют работу, требующую личного присутствия, — столкнулись с гораздо более резким ростом безработицы. С тех пор тренды в обеих группах были в целом схожими. Нижняя панель измеряет размер разрыва между наиболее и наименее экспонированными работниками в рамках модели «разность разностей» (difference-in-differences), что согласуется с выводами по сырым данным. Среднее изменение разрыва с момента выпуска ChatGPT невелико и статистически незначимо, что свидетельствует о том, что уровень безработицы в более экспонированной группе несколько вырос, но эффект неотличим от нуля.⁸
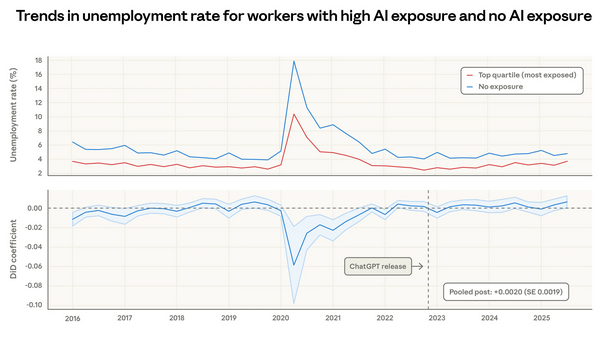 Рисунок 6: Тренды уровня безработицы для работников в верхнем квартиле наблюдаемой экспозиции и без экспозиции к ИИ, Текущее обследование населения
Рисунок 6: Тренды уровня безработицы для работников в верхнем квартиле наблюдаемой экспозиции и без экспозиции к ИИ, Текущее обследование населения
Верхняя панель показывает уровень безработицы для работников в верхнем квартиле экспозиции (красная линия) и 30% работников с нулевой экспозицией. Нижняя панель измеряет разрыв между этими двумя рядами в рамках модели «разность разностей».
Какие сценарии может выявить эта концептуальная рамка? Исходя из доверительного интервала объединённой оценки, дифференциальный рост безработицы порядка 1 процентного пункта был бы обнаружим (это изменится по мере поступления новых данных, поэтому это лишь ориентировочная оценка). Если бы все работники в пределах верхних 10% были уволены, это повысило бы уровень безработицы в группе верхнего квартиля с 3% до 43%, а совокупную безработицу — с 4% до 13%.
Меньший, но всё же вызывающий обеспокоенность эффект — сценарий, подобный «Великой рецессии для работников умственного труда». Во время Великой рецессии 2007–2009 годов уровень безработицы в США удвоился — с 5% до 10%. Такое удвоение в верхнем квартиле экспозиции повысило бы уровень безработицы в этой группе с 3% до 6%. Это также должно было бы отразиться в нашем анализе. Отметим, что наша базовая оценка основана на дифференциальных изменениях уровня безработицы в экспонированной группе по сравнению с менее экспонированной. Если бы безработица росла параллельно для всех работников, мы не стали бы приписывать это достижениям ИИ, которые всё ещё оставляют многие задачи незатронутыми.
Особую группу, вызывающую озабоченность, составляют молодые работники. Brynjolfsson et al. сообщают о снижении занятости в экспонированных профессиях на 6–16% среди работников в возрасте 22–25 лет. Они приписывают это снижение в первую очередь замедлению найма, а не росту увольнений.⁹
Мы обнаруживаем, что уровень безработицы среди молодых работников в экспонированных профессиях остаётся стабильным (см. Приложение). Однако замедление найма не обязательно проявляется в виде роста безработицы, поскольку многие молодые работники — это новички на рынке труда, не имеющие указанной профессии в данных CPS, и они могут покидать рабочую силу, а не регистрироваться как безработные. Чтобы напрямую проанализировать найм, мы используем панельную размерность CPS, подсчитывая процент молодых работников (22–25 лет), которые начинают новую работу в более или менее экспонированной профессии с течением времени. Рисунок 7 показывает месячный уровень трудоустройства (т.е. когда работник сообщает о работе, которой у него не было в предыдущем месяце) для молодых работников с разбивкой по тому, устраиваются ли они в высоко- или низкоэкспонированную профессию.
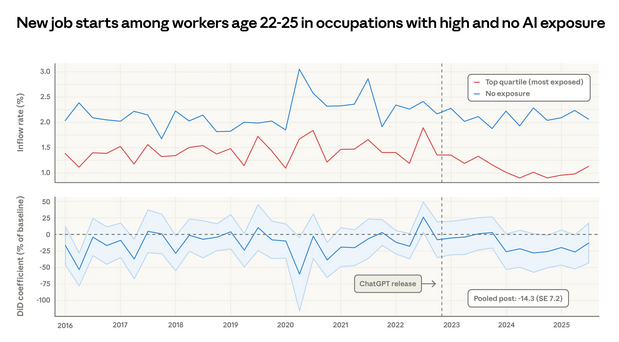 Рисунок 7: Начало новой работы среди работников в возрасте 22–25 лет в профессиях с высокой наблюдаемой экспозицией и без экспозиции к ИИ, Текущее обследование населения
Рисунок 7: Начало новой работы среди работников в возрасте 22–25 лет в профессиях с высокой наблюдаемой экспозицией и без экспозиции к ИИ, Текущее обследование населения
Верхняя панель показывает процент молодых работников, начинающих новую работу в профессиях с высокой и нулевой экспозицией. Нижняя панель измеряет разрыв между этими двумя рядами в рамках модели «разность разностей».
За исключением некоторых резких колебаний в 2020–2021 годах, эти ряды визуально расходятся в 2024 году: молодые работники относительно реже нанимаются в экспонированные профессии. Уровень трудоустройства в менее экспонированные профессии остаётся стабильным на уровне 2% в месяц, тогда как вход в наиболее экспонированные профессии снижается примерно на полпроцентного пункта. Усреднённая оценка в пост-чатгпт-эру показывает снижение уровня трудоустройства на 14% в экспонированных профессиях по сравнению с 2022 годом, хотя это лишь едва достигает статистической значимости. (Для работников старше 25 лет такого снижения не наблюдается.)
Это может служить определённым сигналом ранних эффектов ИИ на занятость и перекликается с выводами Brynjolfsson et al. Однако существуют и альтернативные интерпретации. Молодые работники, которых не нанимают, могут оставаться на своих текущих местах, переходить на другие работы или возвращаться к учёбе. Дополнительное предостережение, связанное с данными: переходы между работами могут быть более уязвимы к ошибкам измерения в опросах.¹⁰
Обсуждение
В этом отчёте представлена новая метрика для понимания воздействия ИИ на рынок труда и изучено влияние на безработицу и найм. Рабочие места в большей степени экспонированы к ИИ в той мере, в какой их задачи теоретически выполнимы с помощью LLM и наблюдаются на наших платформах в автоматизированных, связанных с работой сценариях использования. Мы обнаруживаем, что среди наиболее экспонированных оказываются программисты, специалисты по обслуживанию клиентов и финансовые аналитики. Используя данные опросов по США, мы не находим влияния на уровень безработицы для работников в наиболее экспонированных профессиях, хотя имеются предварительные свидетельства того, что найм в эти профессии несколько замедлился для работников в возрасте 22–25 лет.
Наша работа — это первый шаг к каталогизации влияния ИИ на рынок труда. Мы надеемся, что аналитические шаги, предпринятые в этом отчёте, особенно в части покрытия и контрфактических сценариев, будет легко обновлять по мере появления новых данных о занятости и использовании ИИ. Устоявшийся подход может помочь будущим наблюдателям отделить сигнал от шума.
В текущей работе можно внести несколько улучшений. Наши данные об использовании будут включены в будущие обновления, формируя эволюционирующую картину покрытия задач и рабочих мест в экономике. Метрика Eloundou et al. также может быть обновлена, поскольку она привязана к возможностям LLM по состоянию на начало 2023 года. И, учитывая наводящие на размышления результаты, касающиеся молодых работников и новичков на рынке труда, ключевым следующим шагом может стать изучение того, как недавние выпускники с образовательными квалификациями в экспонированных областях ориентируются на рынке труда.