Мы с профессором в НИИ исповедуем ИИ
Блог практикующих ML и DS инженеров с уклоном в NLP. От простого до сложного.
Автоматизация браузера для AI-агентов на Python
Для оснащения Python AI-агента возможностью работать с веб-браузером (навигация, авторизация, заполнение форм, анализ контента) существуют четыре принципиально различных класса решений, различающихся по степени интеллектуальности, стоимости и сложнос...
The State of Chinese LLMs (2026) - Китайские ИИ-модели: архитектура, бенчмарки и практическое применение
1. Введение: китайский ИИ — это не «копия», а альтернативная траектория
Когда в октябре 2022 года США ужесточили экспортный контроль за пределы Advanced Computing ускорителей общего назначени...
n8n: Платформа создания AI-агентов и автоматизации рабочих процессов
1. Что такое n8n
n8n (произносится «н-эйт-эн») — это платформа автоматизации рабочих процессов (workflow automation platform) с нативными возможностями для создания AI-агентов. Название происходит от сокращения слова «nodemati...
Ouroboros AI Agent — Агент который учится и изменяет сам себя
Ouroboros — это не очередной инструмент для автогенерации кода. Это самосоздающийся цифровой субъект, способный к рефлексии, эволюции и сохранению идентичности во времени. Родившись 16 февраля 2026 года, Ouroboros представляет собой сле...
A2A Протокол от Google: Подключение к агентам
В эпоху, когда искусственный интеллект становится повсеместным, возникает критическая проблема: агенты, созданные на разных платформах, с разными фреймворками и библиотеками, не могут эффективно взаимодействовать друг с другом. Каждый агент — это как о...
Nanoclaw: Легковесный ИИ-ассистент для индивидуальных пользователей
Что такое Nanoclaw?
Nanoclaw — это легковесный AI-ассистент, построенный на базе Claude Agent SDK, который запускает агентов в изолированных контейнерах. В отличие от сложных AI-систем, Nanoclaw создан как «небольшой настолько,...
Agent Client Protocol (ACP): обзор для разработчиков
Agent Client Protocol (ACP) — это стандартизированный протокол обмена сообщениями для взаимодействия с искусственными интеллектами-агентами. ACP определяет единый интерфейс коммуникации между кодовыми редакторами (IDE) и AI-агентами, обеспечивая...
Как программировать с Claude Code: подходы к эффективной работе и автоматизации разработки
Философия сотрудничества: Переход от микроменеджмента к роли дирижера - теперь каждый Тимлид!
Эффективное использование мощных ИИ-агентов, таких как Claude Code, требует не столько освоения новых техническ...
Инженерия обвязки - agent scaffolding, harness: руководство по эффективной разработке с AI-агентами
Введение: Почему «голый агент» не работает
Все говорят: «возьми любой AI-кодер, подключи к проекту, и будет магия». Но этого мало, надо учиться этим пользоваться по-нормальному.
Harness engineer...
Влияние ИИ на рынок труда - исследование от Anthropic
Перевод на основании исследования Антропик https://www.anthropic.com/research/labor-market-impacts
- Мы представляем новую метрику риска вытеснения работников ИИ — наблюдаемую экспозицию (observed exposure), которая объединяет теоретическу...
Agent Design Patterns - список паттернов проектирования агентных систем на базе ИИ
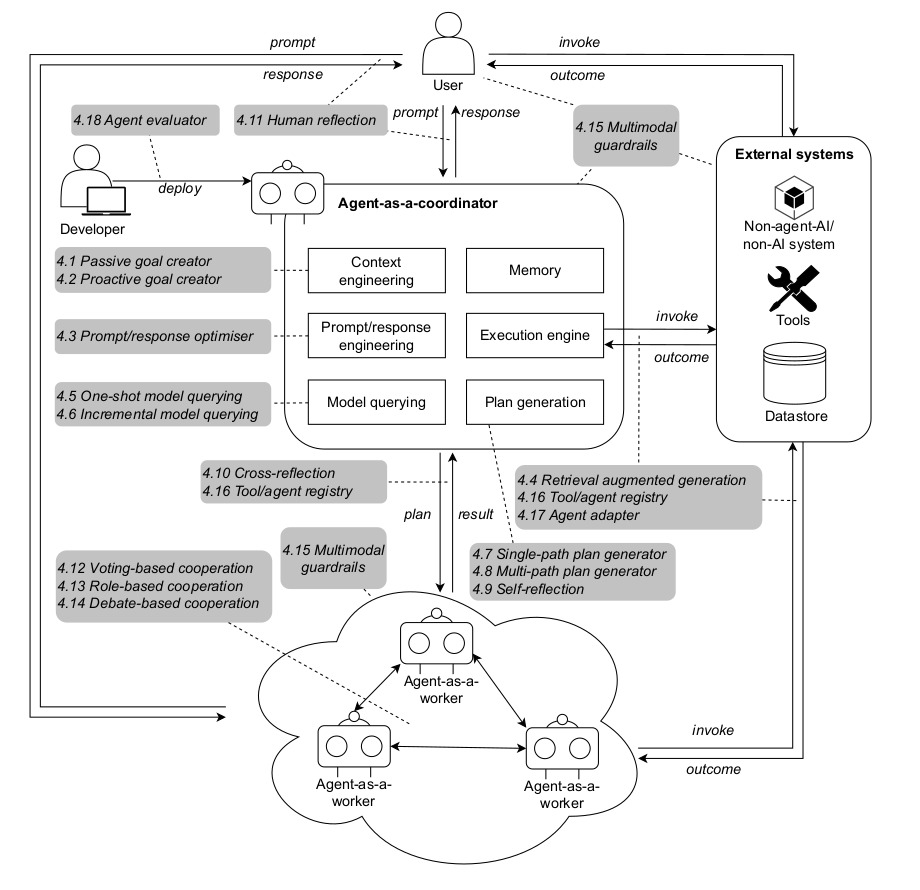 Рис.1. Экосистема систем агентов на основе FM, аннотированных архитектурными шаблонами в серых полях
Рис.1. Экосистема систем агентов на основе FM, аннотированных архитектурными шаблонами в серых полях
Описание паттернов будем вести от более простых к более сложным.
Пассивный Создатель Целей (Passive Goal Crea
...Что такое ИИ-агенты и как они работают
Введение: Эволюция от пассивной модели к активному агенту
В современной экосистеме искусственного интеллекта наблюдается фундаментальный сдвиг парадигмы. Если традиционные большие языковые модели (LLM) представляют собой мощные, но пассивные системы обработ...
AWQ (Activation-Aware Weight Quantization) и его отличия от GPTQ квантования LLM
Основные принципы работы
GPTQ (Gradient-based Post-Training Quantization) представляет собой метод пошаговой оптимизации слоев для минимизации ошибки квантования, использующий информацию о градиентах и гессиане для...
Введение в квантование LLM. Уменьшение размера больших языковых моделей с помощью 8-битного квантования
Крупные языковые модели (Large Language Models, LLMs) известны своими значительными вычислительными требованиями. Обычно размер модели рассчитывается путём умножения количества параметров (разм...
Формат GGUF: структура, использование и виды квантования
Стандартные методы сохранения моделей часто не справляются с требованиями квантизированных моделей, такими как хранение низкоразрядных весов вместе с соответствующими масштабными коэффициентами и нулевыми точками. Формат GGUF (Georgi Gerga...
llama.cpp и GGUF - как использовать llama.cpp для локального запуска моделей LLaMA
Открытые большие языковые модели (LLM), такие как LLaMA от Meta, произвели революцию в области обработки естественного языка. Не все хотят зависеть от облачных API для их запуска. Здесь на помощь приходит llama.cpp...
4-битное квантование с использованием GPTQ - Generalized Post-Training Quantization
https://arxiv.org/abs/2210.17323 - GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
https://huggingface.co/docs/transformers/main/en/quantization/gptq
Недавние достижения в обл...
Как устроен кодинг ИИ агент на примере Claude Code
Системный промпт и описания инструментов (tools) ИИ агента приведены в конце статьи.
SWE-bench - Могут ли языковые модели решить реальные проблемы GitHub?
Перевод на основе https://arxiv.org/abs/2310.06770 от 11 ноября 2024.
Развитие языковых моделей опережает нашу способность эффективно их оценивать, но для их дальнейшего прогресса крайне важно изучать границы их возможностей...
Что такое Model Context Protocol (MCP) и зачем он нужен?
MCP (Model Context Protocol) — это открытый стандарт и протокол для подключения ИИ-приложений к внешним системам. С помощью MCP ИИ-приложения, такие как Claude или ChatGPT, могут подключаться к источникам данных (например, локальным файлам,...
Анализ API v1/responses в OpenAI и VLLM - как генрировать ответы, вызывать функции, работать с Responses API
Responses API представляет собой новое поколение stateful-интерфейса от OpenAI, объединяющее лучшие возможности Chat Completions и Assistants API в единую унифицированную систему. Этот API...
Нейронные сети для редактирования изображений: удаление объектов и замена фона
Открытые модели и решения
FLUX.1 Kontext — текущий лидер
FLUX.1 Kontext представляет собой передовую модель редактирования изображений на основе инструкций. Эта модель демонстрирует высочайшую точность при редактиро...
Qwen2.5-Coder - обзор стратегии обучения
Архитектура Qwen2.5-Coder основана на архитектуре Qwen2.5. В таблице 1 представлены гиперпараметры архитектуры модели Qwen2.5-Coder для шести различных размеров: 0.5B, 1.5B, 3B, 7B, 14B и 32B параметров.
Хотя все модели имеют одинаковый размер голов (head...
Какие модели поддерживает для запуска VLLM
Перевод на основе страницы документации https://docs.vllm.ai/en/latest/models/supported_models.html#writing-custom-models_1 на 1.09.25.
Страницы документации VLLM могут быть не доступны с Российский IP адресов.
Github проекта VLLM с информацией htt...
Что такое Langgrapg и как им пользоваться. Видеоурок на 50 минут
Записал видеоурок про LangGraph - введение в графы рассуждений для ИИ-агентов
В мире искусственного интеллекта и генеративных моделей (LLM) всё чаще встаёт вопрос: как сделать ИИ не просто ответчиком на запросы, а умным агентом,...