DeepSeek-V3 Technical Report
Общий обзор
На основе https://arxiv.org/html/2412.19437v2
Компания DeepSeek-AI в феврале 2025 опубликовала веса и представила технический отчет о своей LLM DeepSeek-V3. DeepSeek-V3 это мощная язковая модель на основе архитектуры смеси экспертов (Mixture-of-Experts, MoE) с общим количеством параметров 671 миллиард и 37 миллиардами активированных параметров при инференсе.
Для достижения эффективного инференса и экономически эффективного обучения DeepSeek-V3 использует архитектуры Multi-head Latent Attention (MLA) и DeepSeekMoE, которые были опробированы и проверены в DeepSeek-V2. Кроме того, DeepSeek-V3 внедряет стратегию балансировки нагрузки без вспомогательных потерь и устанавливает цель обучения с предсказанием нескольких токенов для повышения производительности. Предварительно обучали DeepSeek-V3 на 14,8 триллионах разнообразных и высококачественных токенов, за которыми следуют этапы SFT и обучения с подкреплением. Различные оценки показывают, что DeepSeek-V3 превосходит многие другие модели с открытым исходным кодом и достигает производительности, сравнимой с ведущими моделями с закрытым исходным кодом. Несмотря на свое высокое качество, DeepSeek-V3 потребовала на этапе обучения всего 2,788 миллионов часов GPU H800 для полного обучения. Кроме того, его процесс обучения стабилен. В течение всего процесса обучения исследователи не сталкивались с невосстановимыми всплесками потерь и не выполняли откатов. Контрольные чекпоинты модели доступны по адресу https://github.com/deepseek-ai/DeepSeek-V3
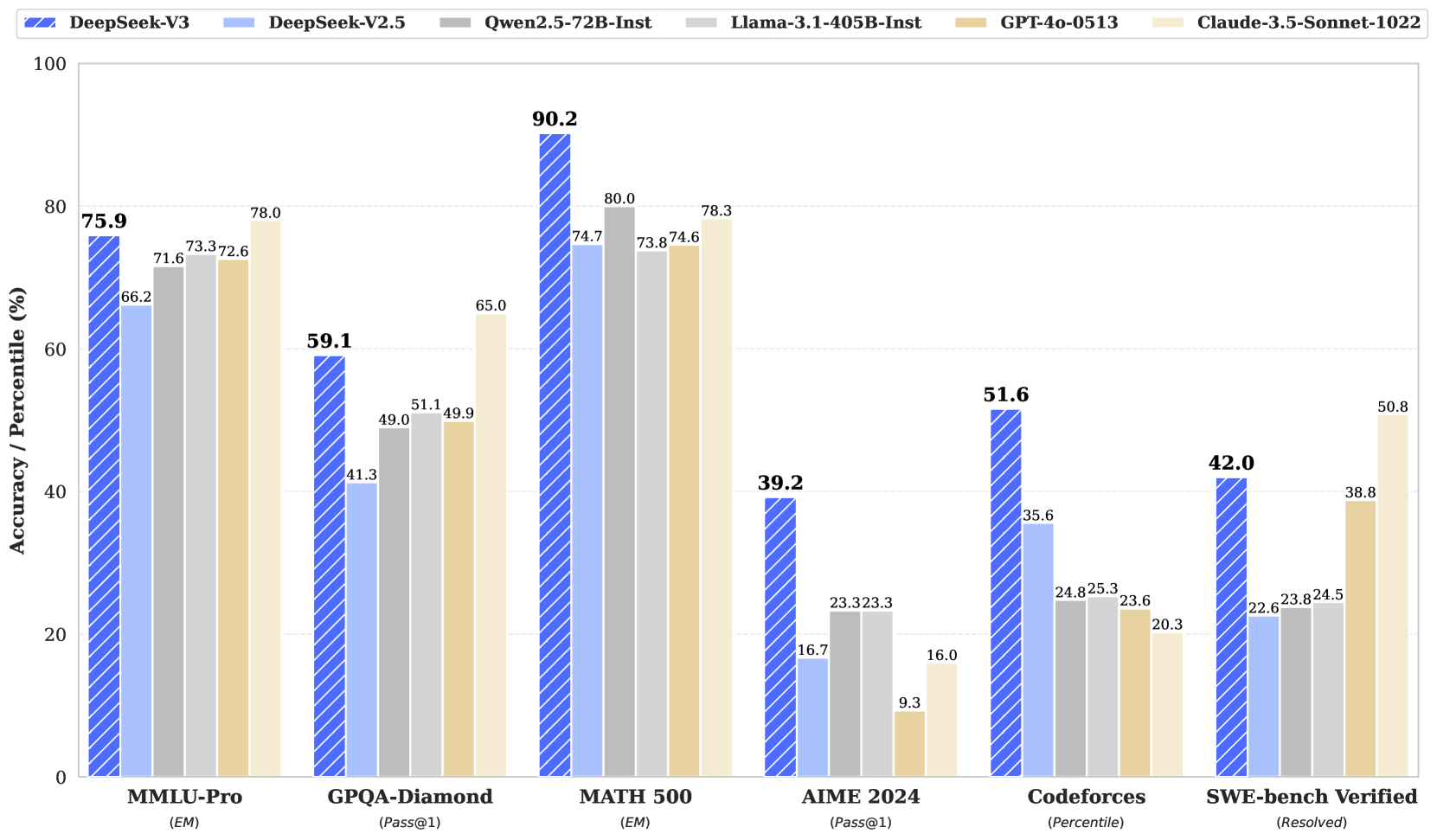
Рис.1 Метрики DeepSeek-V3 на бенчмарках на февраль 2025
В последние годы крупные языковые модели (LLMs) проходят быструю итерацию и эволюцию (OpenAI, 2024a; Anthropic, 2024; Google, 2024), постепенно сокращая разрыв на пути к искусственному общему интеллекту (AGI). Помимо моделей с закрытым исходным кодом, модели с открытым исходным кодом, включая серию DeepSeek (DeepSeek-AI, 2024b, c; Guo et al., 2024; DeepSeek-AI, 2024a), серию LLaMA (Touvron et al., 2023a, b; AI@Meta, 2024a, b), серию Qwen (Qwen, 2023, 2024a, 2024b) и серию Mistral (Jiang et al., 2023; Mistral, 2024), также делают значительные успехи, стремясь сократить разрыв со своими аналогами с закрытым исходным кодом. Чтобы еще больше расширить возможности моделей с открытым исходным кодом, Дипсики увеличили масштабы своих моделей и сделали DeepSeek-V3, большую модель на основе смеси экспертов (MoE) с 671 миллиардом параметров, из которых 37 миллиардов активируются для каждого токена.
С точки зрения архитектуры, DeepSeek-V3 по-прежнему использует Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) для эффективного вывода и DeepSeekMoE (Dai et al., 2024) для экономически эффективного обучения. Эти две архитектуры были проверены в DeepSeek-V2 (DeepSeek-AI, 2024c), демонстрируя свою способность поддерживать устойчивую производительность модели при достижении эффективного обучения и вывода. Помимо базовой архитектуры, было реализовано две дополнительные стратегии для дальнейшего улучшения возможностей модели. Во-первых, DeepSeek-V3 внедряет стратегию балансировки нагрузки без вспомогательных потерь (Wang et al., 2024a), с целью минимизации негативного влияния на производительность модели, возникающего из-за усилий по поощрению балансировки нагрузки. Во-вторых, DeepSeek-V3 использует цель обучения с предсказанием нескольких токенов, что улучшает общую производительность на эталонных тестах.
Для достижения эффективного обучения исследователи поддерживают обучение с FP8 смешанной точностью и внедряют комплексные оптимизации для обучающего фреймворка. Обучение с низкой точностью стало перспективным решением для эффективного обучения (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), его развитие тесно связано с прогрессом в аппаратных возможностях (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). В данной работе они представляют фреймворк для обучения с FP8 смешанной точностью и впервые подтверждают его эффективность на модели чрезвычайно большого масштаба. Благодаря поддержке вычислений и хранения с FP8, им удается ускорить обучение и снизить использование памяти GPU. Что касается обучающего фреймворка, они разрабатывают алгоритм DualPipe для эффективного параллелизма конвейеров, который имеет меньше пузырей конвейера и скрывает большую часть коммуникации во время обучения за счет перекрытия вычислений и коммуникаций. Это перекрытие гарантирует, что по мере дальнейшего масштабирования модели, при условии поддержания постоянного соотношения вычислений к коммуникации, можно использовать мелкозернистых экспертов на узлах, достигая почти нулевых накладных расходов на все-ко-всем коммуникации. Кроме того, они также разрабатывают эффективные ядра для межузловых все-ко-всем коммуникаций, чтобы полностью использовать пропускную способность InfiniBand (IB) и NVLink. Более того, они тщательно оптимизируют объем памяти, что позволяет обучать DeepSeek-V3 без использования дорогостоящего тензорного параллелизма. Сочетая эти усилия, им удается достичь высокой эффективности обучения.
Во время предварительного обучения исследователи обучают DeepSeek-V3 на 14,8 триллионах высококачественных и разнообразных токенов. Процесс предварительного обучения отличается замечательной стабильностью. В течение всего процесса обучения они не сталкивались с невосстановимыми всплесками потерь или не выполняли откатов. Далее они проводят двухэтапное расширение длины контекста для DeepSeek-V3. На первом этапе максимальная длина контекста расширяется до 32K, а на втором этапе — до 128K. После этого они проводят пост-обучение, включая контролируемую тонкую настройку (SFT) и обучение с подкреплением (RL) на базовой модели DeepSeek-V3, чтобы согласовать её с человеческими предпочтениями и раскрыть её потенциал. На этапе пост-обучения они дистиллируют способность к рассуждению из серии моделей DeepSeek-R1 и в то же время тщательно поддерживают баланс между точностью модели и длиной генерации.
Исследователи оценивают DeepSeek-V3 на комплексе эталонных тестов. Несмотря на экономичные затраты на обучение, комплексные оценки показывают, что DeepSeek-V3-Base стала самой сильной открытой базовой моделью на момент 02-2025, особенно в коде и математике. Её чат-версия также превосходит другие модели с открытым исходным кодом и достигает производительности, сравнимой с ведущими моделями с закрытым исходным кодом, включая GPT-4o и Claude-3.5-Sonnet, на серии стандартных и открытых эталонных тестов.
| Затраты на обучение | Предварительное обучение | Расширение контекста | Пост-обучение | Итого |
|---|---|---|---|---|
| в часах GPU H800 | 2664K | 119K | 5K | 2788K |
| в долларах США | $5.328M | $0.238M | $0.01M | $5.576M |
Таблица 1: Затраты на обучение DeepSeek-V3, предполагая, что арендная цена H800 составляет $2 за час GPU.
Также, исследователи подчеркивают экономичные затраты на обучение DeepSeek-V3, которые показаны в Таблице 1 и достигнуты благодаря оптимизированному совместному проектированию алгоритмов, фреймворков и аппаратного обеспечения. На этапе предварительного обучения, обучение DeepSeek-V3 на каждом триллионе токенов требует всего 180 тысяч часов GPU H800, то есть 3,7 дня на их кластере с 2048 GPU H800. Таким образом, их этап предварительного обучения завершается менее чем за два месяца и стоит 2664 тысяч часов GPU. В сочетании с 119 тысячами часов GPU для расширения длины контекста и 5 тысячами часов GPU для пост-обучения, DeepSeek-V3 требует всего 2,788 миллиона часов GPU для полного обучения.
- Предполагая, что арендная цена GPU H800 составляет $2 за час GPU,
- их общие затраты на обучение составляют всего $5,576 миллиона.
Следует отметить, что упомянутые затраты включают только официальное финальное обучение DeepSeek-V3, исключая затраты, связанные с предыдущими исследованиями и экспериментами по абляции архитектур, алгоритмов или данных.
Основной вклад исследователей включает:
Архитектура: Инновационная стратегия балансировки нагрузки и цель обучения
- На основе эффективной архитектуры DeepSeek-V2 они внедряют стратегию балансировки нагрузки без вспомогательных потерь, которая минимизирует ухудшение производительности, возникающее из-за поощрения балансировки нагрузки.
- Они исследуют цель предсказания нескольких токенов (Multi-Token Prediction, MTP) и доказывают её пользу для производительности модели. Она также может быть использована для спекулятивного декодирования для ускорения вывода.
Предварительное обучение: На пути к максимальной эффективности обучения
- Они разрабатывают фреймворк для обучения с FP8 смешанной точностью и впервые подтверждают осуществимость и эффективность обучения с FP8 на модели чрезвычайно большого масштаба.
- Благодаря совместному проектированию алгоритмов, фреймворков и аппаратного обеспечения, они преодолевают узкое место в коммуникации при межузловом обучении MoE, достигая почти полного перекрытия вычислений и коммуникаций. Это значительно повышает их эффективность обучения и снижает затраты на обучение, позволяя им дальней масштабировать размер модели без дополнительных накладных расходов.
- При экономичных затратах всего в 2,664 миллиона часов GPU H800 они завершают предварительное обучение DeepSeek-V3 на 14,8 триллионах токенов, создавая на данный момент самую сильную открытую базовую модель. Последующие этапы обучения после предварительного обучения требуют всего 0,1 миллиона часов GPU.
Пост-обучение: Дистилляция знаний из DeepSeek-R1
- Исследователи представляют инновационную методологию для дистилляции способностей к рассуждению из модели с длинной цепочкой мыслей (Chain-of-Thought, CoT), в частности, из одной из моделей серии DeepSeek R1, в стандартные LLMs, особенно в DeepSeek-V3. Их методология элегантно интегрирует паттерны верификации и рефлексии R1 в DeepSeek-V3 и значительно улучшает его способности к рассуждению. При этом они также сохраняют контроль над стилем и длиной вывода DeepSeek-V3.
Сводка основных результатов оценки
- Знания:
(1) На образовательных эталонных тестах, таких как MMLU, MMLU-Pro и GPQA, DeepSeek-V3 превосходит все другие модели с открытым исходным кодом, достигая 88,5 на MMLU, 75,9 на MMLU-Pro и 59,1 на GPQA. Его производительность сравнима с ведущими моделями с закрытым исходным кодом, такими как GPT-4o и Claude-Sonnet-3.5, сокращая разрыв между моделями с открытым и закрытым исходным кодом в этой области.
(2) На эталонных тестах на фактуальность DeepSeek-V3 демонстрирует превосходную производительность среди моделей с открытым исходным кодом как на SimpleQA, так и на Chinese SimpleQA. Хотя он отстает от GPT-4o и Claude-Sonnet-3.5 в английских фактических знаниях (SimpleQA), он превосходит эти модели в китайских фактических знаниях (Chinese SimpleQA), подчеркивая свою силу в китайских фактических знаниях.
- Код, математика и рассуждения:
(1) DeepSeek-V3 достигает передовых результатов на эталонных тестах, связанных с математикой, среди всех моделей с открытым и закрытым исходным кодом, не использующих длинную CoT. Особенно, он даже превосходит o1-preview на конкретных эталонных тестах, таких как MATH-500, демонстрируя свои сильные математические способности к рассуждению.
(2) На задачах, связанных с программированием, DeepSeek-V3 становится лучшей моделью для эталонных тестов по программированию, таких как LiveCodeBench, укрепляя свою позицию как ведущей модели в этой области. На задачах, связанных с инженерией, хотя DeepSeek-V3 выполняет немного хуже, чем Claude-Sonnet-3.5, он все же опережает все другие модели с значительным отрывом, демонстрируя свою конкурентоспособность на различных технических эталонных тестах.
В оставшейся части статьи исследователи сначала представляют подробное описание архитектуры модели DeepSeek-V3 (Раздел 2). Затем они знакомят с инфраструктурой, включая их вычислительные кластеры, обучающий фреймворк, поддержку обучения с FP8, стратегию развертывания для вывода и их предложения по будущему дизайну аппаратного обеспечения. Далее они описывают процесс предварительного обучения, включая построение обучающих данных, настройки гиперпараметров, техники расширения длинного контекста, соответствующие оценки, а также некоторые обсуждения (Раздел 4). После этого они обсуждают свои усилия по пост-обучению, включая контролируемую тонкую настройку (SFT), обучение с подкреплением (RL), соответствующие оценки и обсуждения (Раздел 5). Наконец, они завершают работу, обсуждают существующие ограничения DeepSeek-V3 и предлагают потенциальные направления для будущих исследований (Раздел 6).
Архитектура
Исследователи сначала представляют базовую архитектуру DeepSeek-V3, которая отличается использованием Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) для эффективного вывода и DeepSeekMoE (Dai et al., 2024) для экономичного обучения. Затем они представляют цель обучения с предсказанием нескольких токенов (Multi-Token Prediction, MTP), которая, как они наблюдали, улучшает общую производительность на эталонных тестах. Для других незначительных деталей, не упомянутых явно, DeepSeek-V3 следует настройкам DeepSeek-V2 (DeepSeek-AI, 2024c).
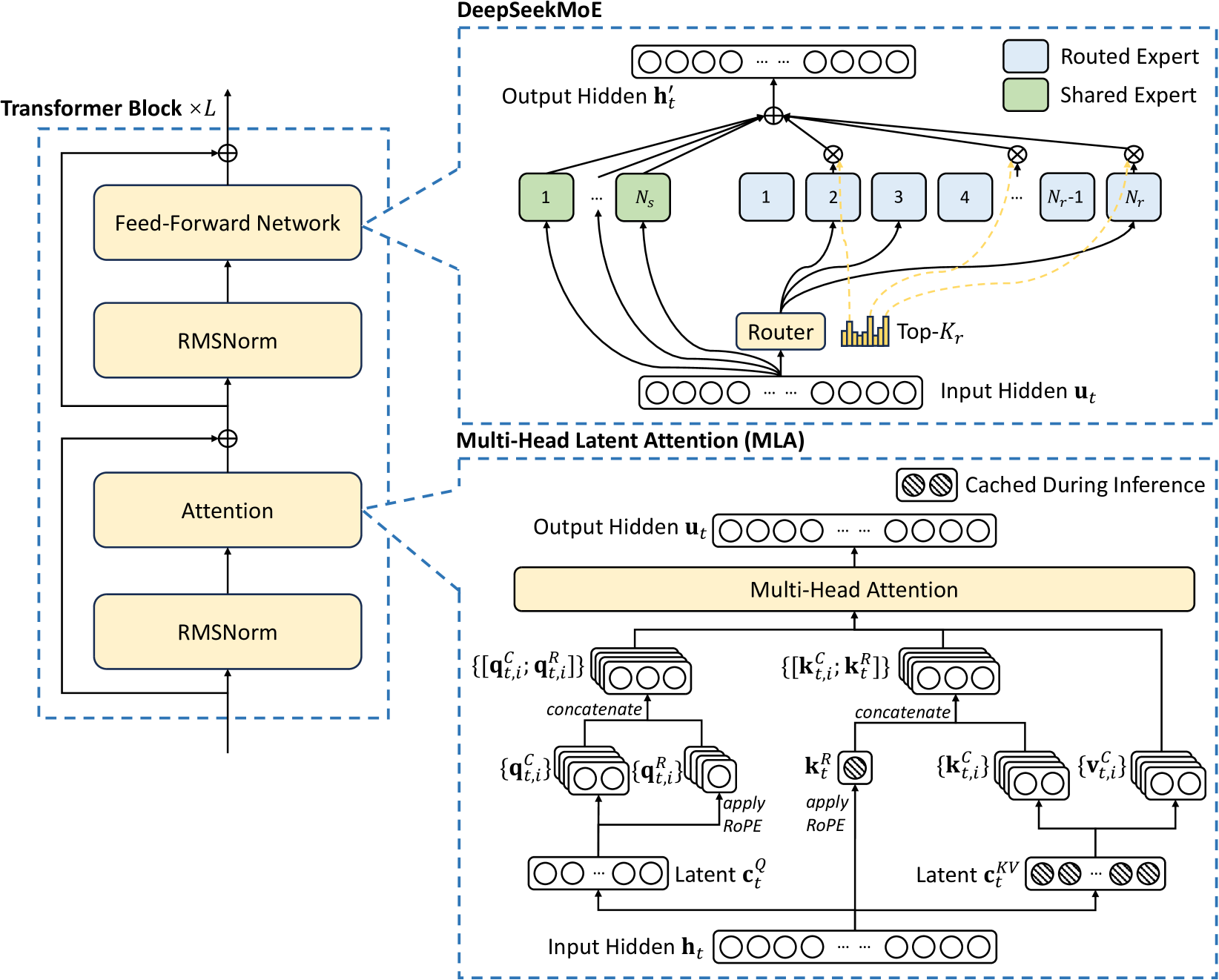
Рис.2 Иллюстрация базовой архитектуры DeepSeek-V3. Следуя DeepSeek-V2, она использует MLA и DeepSeekMoE для эффективного вывода и экономичного обучения.
2.1 Базовая архитектура
Базовая архитектура DeepSeek-V3 по-прежнему основана на фреймворке Transformer (Vaswani et al., 2017). Для эффективного вывода и экономичного обучения DeepSeek-V3 также использует MLA и DeepSeekMoE, которые были тщательно проверены в DeepSeek-V2. В отличие от DeepSeek-V2, исследователи дополнительно внедряют стратегию балансировки нагрузки без вспомогательных потерь (Wang et al., 2024a) для DeepSeekMoE, чтобы уменьшить ухудшение производительности, вызванное усилиями по обеспечению балансировки нагрузки. На рисунке 2 показана базовая архитектура DeepSeek-V3.
2.1.1 Multi-Head Latent Attention
Для механизма внимания DeepSeek-V3 использует архитектуру MLA. Пусть d обозначает размерность встраивания, \(n_h\) — количество голов внимания, \(d_h\) — размерность на голову, а \(𝐡_t∈ℝ^d\) — вход внимания для t-го токена на заданном слое внимания. Основная идея MLA заключается в совместном сжатии с низким рангом для ключей и значений внимания, чтобы уменьшить кэш ключ-значение (KV) во время вывода.
\[ \begin{align} c_t^{KV} &= W^{DKV} h_t, \tag{1} \\ [k_{t,1}^C; k_{t,2}^C; \ldots; k_{t,n_h}^C] &= k_t^C = W^{UK} c_t^{KV}, \tag{2} \\ k_t^R &= \text{RoPE}(W^{KR} h_t), \tag{3} \\ k_{t,i} &= [k_{t,i}^C; k_t^R], \tag{4} \\ [v_{t,1}^C; v_{t,2}^C; \ldots; v_{t,n_h}^C] &= v_t^C = W^{UV} c_t^{KV}. \tag{5} \end{align}\]
где \(c_t^{KV} \in \mathbb{R}^{d_c}\) — это сжатый латентный вектор для ключей и значений; \(d_c\) (\(\ll d_h n_h\)) указывает на размерность сжатия KV; \(W^{DKV} \in \mathbb{R}^{d_c \times d}\) обозначает матрицу понижающего проецирования; \(W^{UK}, W^{UV} \in \mathbb{R}^{d_h n_h \times d_c}\) — это матрицы повышающего проецирования для ключей и значений, соответственно; \(W^{KR} \in \mathbb{R}^{d_R \times d}\) — это матрица, используемая для создания раздельного ключа, который несет в себе вращательное позиционное встраивание (RoPE) (Su et al., 2024); RoPE(·) обозначает операцию, применяющую матрицы RoPE; и [·; ·] обозначает конкатенацию. Обратите внимание, что для MLA только векторы \(c_t^{KV}\) и \(k_t^R\)), нужно кэшировать во время генерации, что приводит к значительному сокращению кэша KV, сохраняя при этом производительность, сравнимую со стандартным Multi-Head Attention (MHA) (Vaswani et al., 2017).
Для запросов внимания исследователи также выполняют низкоранговое сжатие, что может уменьшить память активации во время обучения:
\[ \begin{align} c_t^Q &= W^{DQ} h_t, \tag{6} \\ [q_{t,1}^C; q_{t,2}^C; \ldots; q_{t,n_h}^C] &= q_t^C = W^{UQ} c_t^Q, \tag{7} \\ [q_{t,1}^R; q_{t,2}^R; \ldots; q_{t,n_h}^R] &= q_t^R = \text{RoPE}(W^{QR} c_t^Q), \tag{8} \\ q_{t,i} &= [q_{t,i}^C; q_{t,i}^R], \tag{9} \end{align}\]
где \(c_t^Q \in \mathbb{R}^{d'_c}\) — это сжатый латентный вектор для запросов; \(d'_{c}\) (\(\ll d_h n_h\)) обозначает размерность сжатия запросов; \(W^{DQ} \in \mathbb{R}^{d'_{c} \times d}\), \(W^{UQ} \in \mathbb{R}^{d_h n_h \times d'_{c}}\) — это матрицы понижающего и повышающего проецирования для запросов, соответственно; и \(W^{QR} \in \mathbb{R}^{d_h^R n_h \times d'_{c}}\) — это матрица для создания раздельных запросов, которые несут в себе вращательное позиционное встраивание (RoPE).
В конечном итоге, запросы внимания (\(q_{t,i}\)), ключи (\(k_{j,i}\)) и значения (\(v_{j,i}^C\)) объединяются, чтобы получить окончательный выход внимания \(u_t\):
\[ \begin{align} o_{t,i} &= \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{q_{t,i}^T k_{j,i}}{d_h + d_h^R} \right) v_{j,i}^C, \tag{10} \\ u_t &= W^O [o_{t,1}; o_{t,2}; \ldots; o_{t,n_h}], \tag{11} \end{align}\]
где \(W^O \in \mathbb{R}^{d \times d_h n_h}\) обозначает матрицу выходного проецирования.
DeepSeekMoE с балансировкой нагрузки без вспомогательных потерь
Базовая архитектура DeepSeekMoE
Для прямого распространения в сетях (Feed-Forward Networks, FFN) DeepSeek-V3 использует архитектуру DeepSeekMoE (Dai et al., 2024). В отличие от традиционных архитектур MoE, таких как GShard (Lepikhin et al., 2021), DeepSeekMoE использует более мелкозернистых экспертов и выделяет некоторых экспертов в качестве общих (DeepSeekMoE uses finer-grained experts and isolates some experts as shared ones). Пусть \(u_t\) обозначает вход FFN для t-го токена, тогда выход FFN \(h_t'\) вычисляется следующим образом:
\[ \begin{align} h_t' &= u_t + \sum_{i=1}^{N_s} FFN_i^{(s)}(u_t) + \sum_{i=1}^{N_r} g_{i,t} FFN_i^{(r)}(u_t), \tag{12} \\ g_{i,t} &= \frac{g_{i,t}'}{\sum_{j=1}^{N_r} g_{j,t}'}, \tag{13} \\ g_{i,t}' &= \begin{cases} s_{i,t}, & \text{if } s_{i,t} \in \text{Top}_k(\{s_{j,t} | 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{otherwise}, \end{cases} \tag{14} \\ s_{i,t} &= \text{Sigmoid}(u_t^T e_i), \tag{15} \end{align}\]
где \(N_s\) и \(N_r\) обозначают количество общих экспертов и маршрутизируемых экспертов, соответственно; \(FFN_i^{(s)}(\cdot)\) и \(FFN_i^{(r)}(\cdot)\) обозначают i-го общего эксперта и i-го маршрутизируемого эксперта, соответственно; \(K_r\) обозначает количество активированных маршрутизируемых экспертов; \(g_{i,t}\) — значение шлюза для i-го эксперта; \(s_{i,t}\) — сродство токена к эксперту (token-to-expert affinity); \(e_i\) — вектор центроида i-го маршрутизируемого эксперта; и \(\text{Top}_k(\cdot, K)\) обозначает множество, включающее K наивысших оценок среди оценок сродства, рассчитанных для t-го токена и всех маршрутизируемых экспертов. В отличие от DeepSeek-V2, DeepSeek-V3 использует сигмоидную функцию для вычисления оценок сродства и применяет нормализацию среди всех выбранных оценок сродства для получения значений шлюза.
Балансировка нагрузки без вспомогательного Loss (Auxiliary-Loss-Free Load Balancing)
Для моделей MoE несбалансированная нагрузка на экспертов может привести к коллапсу маршрутизации (Shazeer et al., 2017) и снижению вычислительной эффективности в сценариях с параллелизмом экспертов. Обычные решения обычно полагаются на вспомогательные потери (дополнительный компонент в Loss функции) (Fedus et al., 2021; Lepikhin et al., 2021), чтобы избежать несбалансированной нагрузки. Однако слишком большие вспомогательные потери могут ухудшить производительность модели (Wang et al., 2024a). Чтобы достичь лучшего компромисса между балансировкой нагрузки и производительностью модели, исследователи внедряют стратегию балансировки нагрузки без вспомогательных потерь (Wang et al., 2024a) для обеспечения балансировки нагрузки. Конкретно, они вводят член смещения \(b_i\) для каждого эксперта и добавляют его к соответствующим оценкам сродства \(s_{i,t}\), чтобы определить топ-K маршрутизацию:
\[ g_{i,t}' = \begin{cases} s_{i,t}, & \text{если } s_{i,t} + b_i \in \text{Top}_k(\{s_{j,t} + b_j | 1 \leq j \leq N_r\}, K_r), \\ 0, & \text{в противном случае.} \end{cases} \tag{16}\]
Обратите внимание, что член смещения используется только для маршрутизации. Значение шлюза, которое будет умножено на выход FFN, по-прежнему выводится из исходной оценки сродства \(s_{i,t}\). Во время обучения исследователи постоянно отслеживают нагрузку на экспертов на всей партии каждого шага обучения. В конце каждого шага они уменьшают член смещения на \(\gamma\), если соответствующий эксперт перегружен, и увеличивают его на \(\gamma\), если соответствующий эксперт недогружен, где \(\gamma\) — это гиперпараметр, называемый скоростью обновления смещения. Благодаря динамической регулировке DeepSeek-V3 поддерживает сбалансированную нагрузку на экспертов во время обучения и достигает лучшей производительности, чем модели, которые поощряют балансировку нагрузки исключительно через вспомогательные потери.
Дополнительные вспомогательные потери на уровне последовательности (Complementary Sequence-Wise Auxiliary Loss)
Хотя DeepSeek-V3 в основном полагается на стратегию балансировки нагрузки без вспомогательных потерь, для предотвращения экстремального дисбаланса внутри любой отдельной последовательности исследователи также используют дополнительные потери балансировки на уровне последовательности:
\[ \begin{align} \mathcal{L}_{\text{Bal}} &= \alpha \sum_{i=1}^{N_r} f_i P_i, \tag{17} \\ f_i &= \frac{N_r}{K_r T} \sum_{t=1}^{T} \mathbb{1} \left( s_{i,t} \in \text{Top}_k(\{s_{j,t} | 1 \leq j \leq N_r\}, K_r) \right), \tag{18} \\ s_{i,t}' &= \frac{s_{i,t}}{\sum_{j=1}^{N_r} s_{j,t}}, \tag{19} \\ P_i &= \frac{1}{T} \sum_{t=1}^{T} s_{i,t}', \tag{20} \end{align}\]
где коэффициент балансировки \(\alpha\) является гиперпараметром, которому будет присвоено крайне малое значение для DeepSeek-V3; \(\mathbb{1}(\cdot)\) обозначает индикаторную функцию; и \(T\) обозначает количество токенов в последовательности. Потери балансировки на уровне последовательности поощряют балансировку нагрузки на экспертов для каждой последовательности.
Маршрутизация с ограничением по узлам (Node-Limited Routing)
Подобно маршрутизации с ограничением по устройству, используемой в DeepSeek-V2, DeepSeek-V3 также использует механизм ограниченной маршрутизации для ограничения затрат на коммуникацию во время обучения. Кратко говоря, исследователи обеспечивают, чтобы каждый токен отправлялся не более чем на M узлов, которые выбираются в соответствии с суммой наивысших \(K_r M\) оценок сродства экспертов, распределённых на каждом узле. При таком ограничении их фреймворк обучения MoE может почти полностью достичь перекрытия вычислений и коммуникаций.
Отсутствие отбрасывания токенов (No Token-Dropping)
Благодаря эффективной стратегии балансировки нагрузки, DeepSeek-V3 поддерживает хороший баланс нагрузки в течение всего обучения. Поэтому DeepSeek-V3 не отбрасывает ни одного токена во время обучения. Кроме того, они также реализуют специфические стратегии развёртывания, чтобы обеспечить баланс нагрузки при выводе, поэтому DeepSeek-V3 также не отбрасывает токены во время вывода.
Предсказание нескольких токенов (Multi-Token Prediction)
Вдохновленные работой Gloeckle и др. (2024), исследователи прорабатывают и устанавливают цель предсказания нескольких токенов (Multi-Token Prediction, MTP) для DeepSeek-V3, которая расширяет область предсказания на несколько будущих токенов на каждой позиции. С одной стороны, цель MTP уплотняет обучающие сигналы и может улучшить эффективность использования данных. С другой стороны, MTP может позволить модели заранее планировать свои представления для лучшего предсказания будущих токенов. На рисунке 3 иллюстрируется их реализация MTP. В отличие от Gloeckle и др. (2024), которые параллельно предсказывают D дополнительных токенов, используя независимые выходные слои, они последовательно предсказывают дополнительные токены и сохраняют полную причинную цепочку на каждой глубине предсказания. В этом разделе они представляют детали своей реализации MTP.
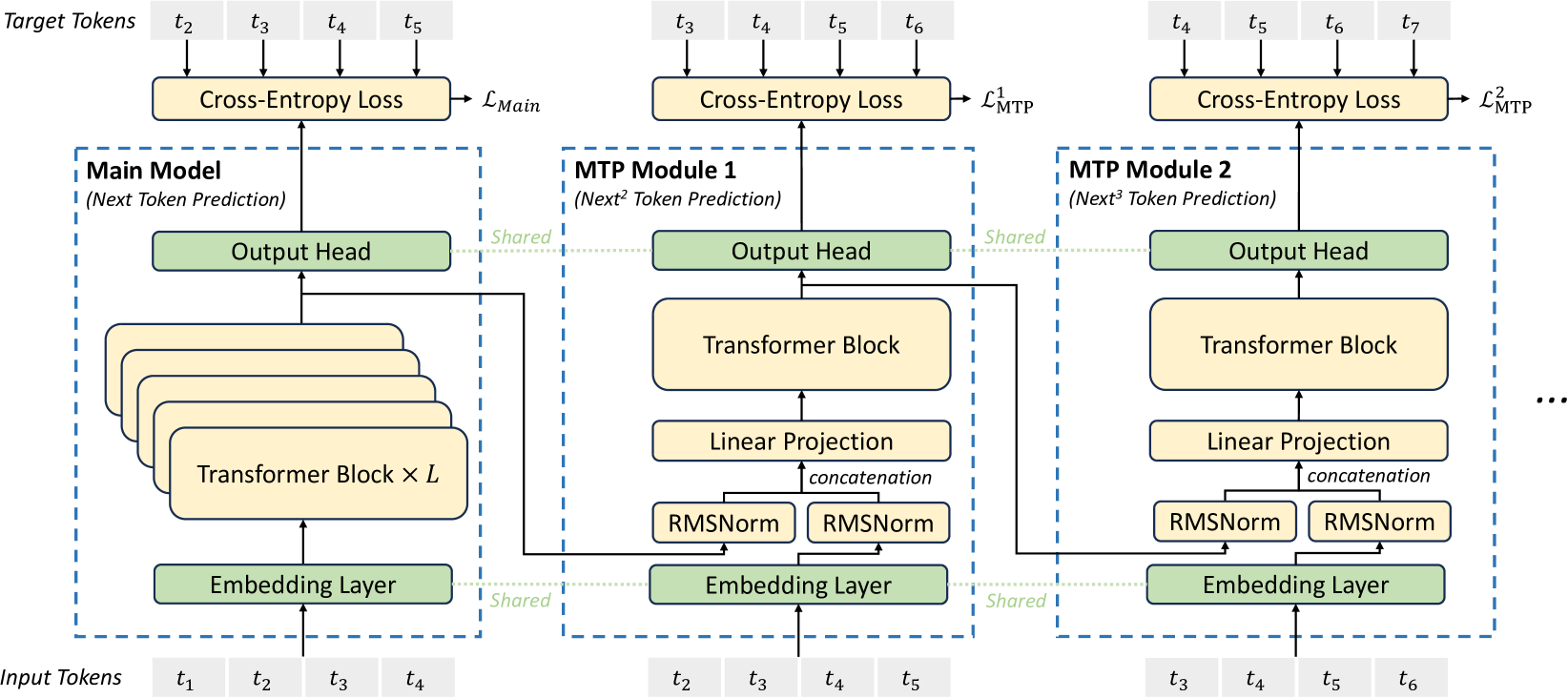
Рис.3. Иллюстрация реализации Multi-Token Prediction (MTP). Cохраняется полная причинно-следственная цепочка для прогнозирования каждого токена на каждой глубине.
Модули MTP
Конкретно, их реализация MTP использует D последовательных модулей для предсказания D дополнительных токенов. k-й модуль MTP состоит из общего слоя встраивания \(\text{Emb}(\cdot)\), общего выходного слоя \(\text{OutHead}(\cdot)\), блока Transformer \(\text{TRM}_k(\cdot)\) и матрицы проекции \(M_k \in \mathbb{R}^{d \times 2d}\). Для i-го входного токена \(t_i\), на k-й глубине предсказания, они сначала объединяют представление i-го токена на (k-1)-й глубине \(h_i^{k-1} \in \mathbb{R}^d\) и встраивание (i+k)-го токена \(\text{Emb}(t_{i+k}) \in \mathbb{R}^d\) с линейной проекцией:
\[ h_i^{'k} = M_k [\text{RMSNorm}(h_i^{k-1}); \text{RMSNorm}(\text{Emb}(t_{i+k}))], \tag{21}\]
где [·; ·] обозначает конкатенацию. Особенно, когда \(k = 1\), \(h_i{k-1}\) относится к представлению, данному основной моделью. Обратите внимание, что для каждого модуля MTP его слой встраивания является общим с основной моделью. Объединенное \(h_i{'k}\) служит входом для блока Transformer на k-й глубине для получения выходного представления на текущей глубине \(h_i^k\):
\[ h_{1:T-k}^k = \text{TRM}_k(h_{1:T-k}^{'k}), \tag{22}\]
где T представляет длину входной последовательности, \(_{i:j}\) - обозначает операцию среза (включая обе границы). Наконец, принимая \(h_i^k\) в качестве входа, общий выходной слой вычисляет распределение вероятностей для k-го дополнительного предсказанного токена \(P_{i+1+k,k} \in \mathbb{R}^V\), где V — размер словаря:
\[ P_{i+k+1}^k = \text{OutHead}(h_i^k). \tag{23}\]
Выходной слой \(\text{OutHead}(\cdot)\) линейно отображает представление в логиты и затем применяет функцию \(\text{Softmax}(\cdot)\) для вычисления вероятностей предсказания k-го дополнительного токена.
Также для каждого модуля MTP его выходной слой является общим с основной моделью. Их принцип поддержания причинной цепочки предсказаний похож на EAGLE (Li et al., 2024b), но его основная цель — спекулятивное декодирование (Xia et al., 2023; Leviathan et al., 2023), тогда как они используют MTP для улучшения обучения.
Loss обучения MTP.
Для каждой глубины предсказания мы вычисляем функцию потерь перекрёстной энтропии \(\mathcal{L}_{\text{MTP}_k}\):
\[ \mathcal{L}_{\text{MTP}_k} = \text{CrossEntropy}(P_{2+k:T+1}^{k}, t_{2+k:T+1}) = -\frac{1}{T} \sum_{i=2+k}^{T+1} \log P_{ik}[t_i],\]
где \(T\) обозначает длину входной последовательности, \(t_i\) обозначает истинный токен на \(i\)-й позиции, а \(P_{ik}[t_i]\) обозначает соответствующую вероятность предсказания \(t_i\), заданную \(k\)-м модулем MTP. Наконец, мы вычисляем среднее значение потерь MTP по всем глубинам и умножаем его на весовой коэффициент \(\lambda\), чтобы получить общую потерю MTP \(\mathcal{L}_{\text{MTP}}\), которая служит дополнительной целью обучения для DeepSeek-V3:
\[ \mathcal{L}_{\text{MTP}} = \lambda \frac{1}{D} \sum_{k=1}^{D} \mathcal{L}_{\text{MTP}_k}.\]
Для каждого модуля вычисляется своя функция потерь — то есть, насколько хорошо он предсказал нужный токен. Потом эти потери усредняются и добавляются к основной функции потерь модели как штраф/цель.
Таким образом, модель учится не только правильно воспроизводить следующий токен , но и планировать вперёд , чтобы предсказывать последовательность целиком.
Зачем это нужно?
- Лучшее понимание контекста : если модель знает, что ей нужно предсказать не один, а несколько токенов вперёд, она старается строить более осмысленные представления.
- Эффективное обучение : модель получает больше сигналов от данных, чем раньше.
- Улучшение генерации : хотя MTP используется на этапе обучения, это помогает модели лучше работать на этапе инференса (генерации текста).
MTP в процессе инференса.
Стратегия MTP направлена в основном на улучшение производительности основной модели, поэтому во время инференса мы можем просто отбросить модули MTP, и основная модель может функционировать независимо и нормально. Кроме того, мы также можем повторно использовать эти модули MTP для спекулятивного декодирования, чтобы ещё больше уменьшить задержку генерации.
- Стандартный режим : MTP-модули просто игнорируются. Модель работает как обычно — генерирует текст по одному токену.
- Режим ускорения : можно использовать MTP-модули для спекулятивного декодирования — когда модель сразу пробует угадать несколько токенов вперёд, чтобы ускорить работу.
Инфраструктура
Вычислительный кластер
Обучение DeepSeek-V3 проводится на кластере, оснащённом 2048 графическими процессорами NVIDIA H800. Каждый узел в кластере H800 содержит 8 графических процессоров, соединённых с помощью NVLink и NVSwitch внутри узлов. Для связи между различными узлами используются межузловые соединения InfiniBand (IB).
Фреймворк обучения
Обучение DeepSeek-V3 поддерживается фреймворком HAI-LLM, эффективным и лёгким фреймворком обучения, разработанным инженерами Дипсик с нуля. В целом, DeepSeek-V3 использует 16-кратный параллелизм конвейеров (PP), 64-кратный параллелизм экспертов (EP), охватывающий 8 узлов, и ZeRO-1 параллелизм данных (DP).
Для обеспечения эффективного обучения DeepSeek-V3 реализованы тщательные инженерные оптимизации. Во-первых, разработан алгоритм DualPipe для эффективного конвейерного параллелизма. По сравнению с существующими методами PP, DualPipe имеет меньше пузырей пайплайна. Более того, он перекрывает этапы вычислений и коммуникации в процессах прямого и обратного прохода, тем самым решая проблему значительных накладных расходов на коммуникацию, введённых межузловым параллелизмом экспертов. Во-вторых, разработаны эффективные межузловые ядра коммуникации "все-со-всеми" для полного использования пропускной способности IB и NVLink и сохранения потоковых мультипроцессоров (SM), предназначенных для коммуникации. Наконец, тщательно оптимизирована память во время обучения, что позволяет обучать DeepSeek-V3 без использования дорогостоящего тензорного параллелизма (TP).
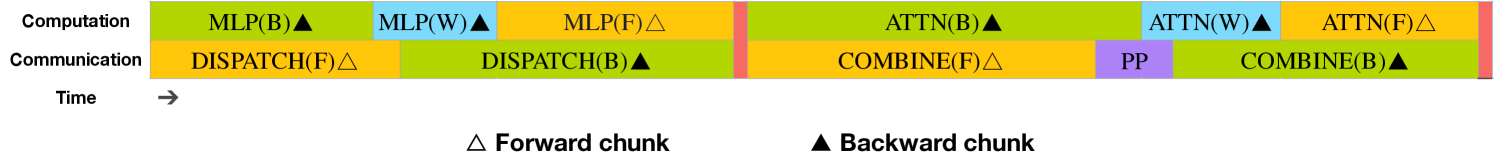
Рис. 4. Стратегия перекрытия для пары отдельных прямых и обратных блоков (границы трансформерных блоков не совпадают). Оранжевым цветом обозначено прямое распространение, зелёным — "обратное для входа", синим — "обратное для весов", фиолетовым — коммуникация параллелизма конвейеров (PP), а красным — барьеры. И все-со-всеми, и PP коммуникации могут быть полностью скрыты.
Для DeepSeek-V3 накладные расходы на коммуникацию, введённые межузловым параллелизмом экспертов, приводят к неэффективному соотношению вычислений к коммуникации примерно 1:1. Чтобы решить эту проблему, разработан инновационный алгоритм конвейерного параллелизма под названием DualPipe, который не только ускоряет обучение модели, эффективно перекрывая этапы вычислений и коммуникации в процессах прямого и обратного распространения, но и уменьшает пузыри конвейера.
Ключевая идея DualPipe заключается в перекрытии вычислений и коммуникаций внутри пары отдельных прямых и обратных блоков. Конкретно, каждый блок делится на четыре компонента: внимание, все-со-всеми диспетчеризация, многослойный перцептрон (MLP) и все-со-всеми объединение. Особенно для обратного блока, как внимание, так и MLP дополнительно делятся на две части: обратное распространение для входа и обратное распространение для весов, как в ZeroBubble. Кроме того, имеется компонент коммуникации параллелизма конвейеров (PP). Как показано на рисунке 4, для пары прямых и обратных блоков, эти компоненты переупорядочиваются, и вручную регулируется соотношение потоковых мультипроцессоров графического процессора (GPU SM), выделенных для коммуникации и вычислений. В этой стратегии перекрытия можно обеспечить, чтобы и все-со-всеми, и PP коммуникации могли быть полностью скрыты во время выполнения. Учитывая эффективную стратегию перекрытия, полное планирование DualPipe показано на рисунке 5. Оно использует двунаправленное планирование конвейера, которое подаёт микро-пакеты с обоих концов конвейера одновременно, и значительная часть коммуникаций может быть полностью перекрыта. Это перекрытие также гарантирует, что по мере дальнейшего масштабирования модели, пока поддерживается постоянное соотношение вычислений к коммуникации, можно по-прежнему использовать мелкозернистых экспертов между узлами, достигая почти нулевых накладных расходов на все-со-всеми коммуникации.

Рис. 5. Пример планирования DualPipe для 8 рангов параллелизма конвейеров (PP) и 20 микро-пакетов в двух направлениях. Микро-пакеты в обратном направлении симметричны тем, что в прямом направлении, поэтому для простоты иллюстрации мы опускаем их идентификаторы пакетов. Две ячейки, заключённые в общую чёрную рамку, имеют взаимно перекрытые вычисления и коммуникации.