Lamini Memory Tuning - Mixture of Memory Experts (MoME)
В отдельных кейсах Lamini Memory Tuning дает 95% точности ответов LLM, снижая количество галлюцинаций модели в 10 раз, по заявлениям команды продукта Lamini.
Кратко:
-
Lamini Memory Tuning — это новый метод интеграции фактов в языковые модели (LLM), который значительно улучшает их фактическую точность и снижает количество галлюцинаций до ранее недостижимых уровней. Для одного клиента из списка Fortune 500 настройка памяти Lamini обеспечила точность в 95% по сравнению с 50% при использовании других подходов. Количество галлюцинаций снизилось с 50% до 5%.
-
Lamini Memory Tuning — это исследовательский прорыв, который решает, казалось бы, парадоксальную задачу в мире ИИ: достижение высокой точности фактов (без галлюцинаций) при сохранении способности моделей к обобщению, что делает LLM столь ценными.
-
Метод основывается на настройке миллионов "адаптеров-экспертов" (например, LoRAs) с точными фактами поверх любой открытой LLM, такой как Llama 3 или Mistral 3. Если цель — точно отразить факты о Римской империи, Lamini Memory Tuning создаст экспертов по Цезарю, акведукам, легионам и другим предоставленным фактам. Вдохновлённая методами извлечения информации, модель при выводе извлекает только самые релевантные "эксперты" из индекса, а не все веса модели, что значительно снижает задержки и затраты.
Подход обещает высокую точность, высокую скорость, низкую стоимость одновременно.
Точность имеет огромное значение
Универсальные языковые модели (LLM) изначально склонны к галлюцинациям, так как их обучение направлено на минимизацию средней ошибки на всех примерах, которые они видели. Они хороши во всём понемногу, но не идеальны ни в чём. Модели могут создавать связный текст благодаря огромному количеству данных из интернета, но точные факты — такие как дата, размер выручки или имя переменной — часто теряются в их весах и не воспроизводимы в генерациях.
Вместо того чтобы оптимизировать среднюю ошибку для всего, Lamini Memory Tuning оптимизирует для нулевой ошибки конкретные факты, которые вы просите его запомнить, так что он вспоминает эти факты почти идеально. Само по себе это не является чем-то особенным. Этот подход особенно революционен, потому что он сохраняет способность LLM обобщать со средней ошибкой все остальное и, таким образом, продолжать генерировать рассуждения, оперировать понятиями и делать суждения на основе этих фактов. Lamini Memory Tuning - это систематический инструмент для устранения галлюцинаций на фактах, которые вам важны.
Prompting и RAG: необходимо, но недостаточно
Методы промптинга и Retrieval Augmented Generation (RAG) играют важную роль в извлечении релевантной информации для модели, изменяя вероятности в её ответах в сторону учета схожих данных. Это важный шаг для того, чтобы модель фокусировалась на нужных концепциях и данных, особенно учитывая, что она обучена на множестве задач. Хорошее проектирование промптов и грамотно настроенные RAG-пайплайны критически важны для повышения общей точности модели.
Но часто этого бывает достаточно. Даже предоставив модели релевантную информацию, вы получаете ответ, который всё равно оказывается неверным, хоть и очень близким к правильному — это приводит к галлюцинациям.
Почему галлюцинации случаются даже при наличии правильных данных?
Внутреннее представление модели устроено так, что правильный ответ, скорее всего, сгруппирован с похожими, но неправильными вариантами. Предоставление правильного контекста увеличивает вероятность как правильного ответа, так и близких, но неверных вариантов. Модель не понимает, что "почти правильный" ответ всё ещё остаётся неправильным, потому что универсальные модели не отличают полностью точный ответ от слегка ошибочного. Они никогда не были обучены сводить такие ошибки к нулю. Методы подбора промптов и RAG не решают эту проблему.
Lamini Memory Tuning решает эту задачу напрямую, сочетая методы извлечения информации и ИИ для того, чтобы обучить модель тому, что "почти правильный" ответ равносилен полностью неправильному.
Инструктивный fine-tuning не решает пролему галлюцинаций на конкретных фактах
Многие команды прибегают к instruction fine-tuning, когда другие подходы перестают давать результаты в повышении фактической точности. Однако fine-tuning, будь то с использованием LoRA или без них, сталкивается с той же проблемой, что и предобучение: он становится достаточно хорош в рамках более узкого набора данных, но всё равно не достигает идеала, а работать с ним достаточно сложно, т.к. тюнинг может привести к ухудшению производительности модели на общих задачах.
Хотя instruction fine-tuning может быть очень полезным (именно он превратил GPT-3 в ChatGPT), он не делает модели идеальными в воспроизведении важных фактов. Иными словами, традиционный fine-tuning не гарантирует, что ответы модели будут соответствовать фактам из её обучающих данных.
Lamini Memory Tuning: почти идеальное воспроизведение фактов благодаря миллиону экспертов (MoE)
Lamini Memory Tuning — это принципиально иной подход к fine-tuning, который позволяет любой открытой LLM практически идеально запоминать факты, сохраняя при этом её способность быть "достаточно хорошей" в других задачах. Когда модель должна воспроизвести конкретный факт, Lamini Memory Tuning полностью переносит вероятностное распределение на этот факт (то есть на конкретные токены в определённом контексте), например, на точную схему SQL вашей базы данных.
В результате выходные вероятности модели не просто приближаются к правильному результату — они становятся совершенно точными.
Для этого Lamini Memory Tuning настраивает масштабную смесь "экспертов памяти" на базе любой открытой LLM. Каждый эксперт памяти действует как адаптер LoRA, функционально выполняя роль хранилища памяти для модели. Вместе эти эксперты памяти специализируются на миллионе различных направлений, чтобы обеспечить точное и достоверное соответствие данным, на которых модель была настроена.
Вдохновлённая методами извлечения информации, эта система экспертов памяти работает как индекс, из которого модель интеллектуально извлекает и маршрутизирует данные. Во время вывода (inference) модель выбирает наиболее релевантных экспертов на каждом уровне и объединяет их с базовой моделью, чтобы сформировать ответ на запрос пользователя.
Результатом является модель с разреженной активацией, называемая Mixture of Memory Experts (MoME), которая может масштабироваться до огромного количества параметров при фиксированных вычислительных затратах на вывод. Это означает, что MoME обладает чрезвычайно высокой емкостью для запоминания фактов, ограниченной только общим объемом обучающего набора данных. Например, Llama 3 была обучена на 15 триллионах токенов. На практике системная память закончится раньше, чем закончится емкость памяти в MoME.
В конечном итоге этот подход делает возможным реализацию сценариев, которые ранее были недостижимыми из-за галлюцинаций, и значительно сокращает время, необходимое для достижения точности моделей (time-to-accuracy), а следовательно, и время вывода продукта на рынок (time-to-market).
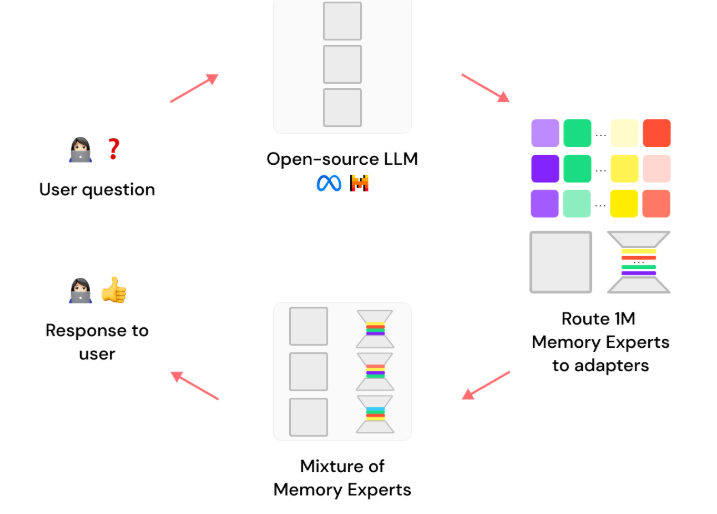
Исследовательская статья про подход Lamini
На основе https://arxiv.org/abs/2406.17642
Несмотря на мощные возможности в области общения, программирования и рассуждений, крупные языковые модели (LLMs) часто сталкиваются с галлюцинациями. Общепринятое мнение предполагает, что галлюцинации являются следствием баланса между креативностью и фактической точностью, и их можно смягчить, но не устранить полностью, за счёт привязки LLM к внешним источникам знаний.
Проведя обширные систематические эксперименты, в статье показано, что эти традиционные подходы не объясняют, почему LLM фактически склонны к галлюцинациям. В частности, демонстрируется, что LLM, дополненные масштабной смесью экспертов памяти (Mixture of Memory Experts, MoME), могут легко запоминать большие наборы данных случайных чисел. Эти экспериментальные результаты подкрепляются теоретической конструкцией, показывающей, что простые нейронные сети, обученные предсказывать следующий токен, начинают галлюцинировать, если их обучающая ошибка превышает определённый порог, что обычно наблюдается на данных интернет-масштаба.
Основываясь на выводах статьи, авторы разработали модель первого поколения для устранения галлюцинаций — Lamini-1 — которая хранит факты в масштабной смеси миллионов экспертов памяти, извлекаемых динамически.
Языковые модели (LLMs) обучаются на гигантских интернет-данных, используя триллионы параметров. Примечательно, что некоторые из этих моделей демонстрируют низкую "ошибку обобщения" — разницу между "ошибкой обучения" и "ошибкой тестирования". Как предсказано в предыдущих работах, выявивших законы масштабирования (Hestness et al., 2017), с масштабированием наблюдаются резкие улучшения в универсальных LLMs. В то же время легко создать модели, которые показывают плохие результаты, например, модели, которые галлюцинируют, модели, которые переобучаются на нерелевантных данных, или модели, использующие архитектуры, такие как глубокие нейронные сети (DNN), без рекуррентных связей или внимания. Если причина галлюцинаций не в высокой ошибке обобщения, то что же её вызывает? Существуют ли другие архитектуры с низкой ошибкой обобщения и меньшими галлюцинациями? Реализуемы ли они с точки зрения вычислений? Удовлетворительный ответ на эти вопросы не только поможет сделать LLM более интерпретируемыми и полезными в областях, требующих точных ответов, но и может привести к более принципиальному и надежному проектированию архитектуры моделей.
Для ответа на этот вопрос системы извлечения информации и базы данных предлагают ряд структур данных и алгоритмов для хранения и извлечения фактов, которые не должны галлюцинировать. Это включает извлечение из инвертированного индекса (Manning et al., с использованием TF-IDF Sparck Jones, 1972), из векторной базы данных с использованием поиска по k ближайшим соседям (Knuth, 1997), и из реляционной базы данных (Codd, 1970) с использованием B-дерева (Bayer and McCreight, 1970). Эти системы, ориентированные на работу с данными, теперь интегрируются с LLM, предлагая обещание создания универсальных ИИ-агентов, которые могут рассуждать, программировать и общаться с доступом к огромным объёмам данных.
Вместе с системами, ориентированными на данные, люди легко справляются с задачами, требующими точности, такими как запоминание паролей, идентификаторов и ключевых финансовых терминов. Они также могут выполнять задачи, требующие обобщения и креативности, такие как исследования и ведение блогов.
Тесты на случайность.
Анализ галлюцинаций основан на рандомизированных тестах, предложенных Zhang et al. (2017), Edgington и Onghena (2007).
Основной вывод исследования можно сформулировать следующим образом:
LLM легко запоминают случайные метки, при этом сохраняя генерализацию.
Точнее говоря, при обучении на данных вопросов и ответов, как это часто бывает при fine-tuning инструкций (Sanh et al., 2021), когда ответы содержат случайные символы, предварительно обученные LLM достигают нулевой ошибки fine-tuning, и при этом правильно отвечают на остальные вопросы, вне контекста рандомизированного теста.
Другими словами, можно заставить модель запоминать случайные строки, не вызывая значительного увеличения ошибки генерализации модели. Этот факт был установлен для нескольких стандартных архитектур, включая Llama 3 Meta (2024) и Mistral v2 Jiang et al. (2023), обычно требующих около 100 эпох fine-tuning на данных рандомизированного теста.
Хотя это утверждение легко изложить, оно имеет глубокие последствия с точки зрения извлечения информации. Оно показывает следующее:
- Даже после предварительного обучения, LLM имеют достаточную емкость для запоминания больших наборов данных и фактов.
- Запоминание ключевых фактов требует примерно в 100 раз больше шагов (Stochastic Gradient Descent, SGD), чем обычно.
- Сильные модели с низкой ошибкой генеразизации могут все равно существенно галлюцинировать, если факт не записан жестко в веса модели.
Этот результат подразумевает, что возможно построить LLM, которые не будут галлюцинировать по нужным для задачи ключевым фактам. Однако вычислительные затраты на это в настоящее время могут быть неосуществимы. Начав с закона масштабирования Chinchilla - Hoffmann et al. (2022) и увеличив его до 100 эпох, устранение галлюцинаций на модели Llama 3 с 400B параметров потребует 3,43 yotta FLOPs (3,43×10²⁴ FLOPs). Это потребует примерно 3 месяца обучения на 350,000 процессорах AMD MI300X (Smith et al., 2024), работающих на 45% MFU (Chowdhery et al., 2023), с потреблением энергии около 350 мегаватт. По цене $0,09 за кВтч, стоимость только электроэнергии для этого эксперимента составит 68 миллионов долларов. Это создаст углеродный след, в 62,000 раз превышающий среднее количество выбросов углекислого газа, производимых обычным домохозяйством в США за год (EPA, 2024).
Lamini Memory Tuning
Хотя явные регуляризаторы, такие как dropout и weight-decay, помогают генерализации, вполне очевидно, что не все модели, которые хорошо подгоняются под тренировочные данные, демонстрируют хорошую генерализацию. Действительно, в случае с LLM, модель обычно выбирается как результат выполнения стохастического градиентного спуска в течение одной-двух эпох на триллионах токенов интернет-текстов. Исследователи показывают, как этот типичный процесс обучения приводит к галлюцинациям фактов, даже если они присутствуют в данных для предварительного обучения. В качестве решения предлагается новый подход, называемый Lamini Memory Tuning, который нацелен на достижение нулевой ошибки обучения для ключевых фактов, при работе с которыми модель не должна галлюцинировать.
Lamini-1
В этой работе исследователи опираются на методы извлечения информации, системы баз данных и системы обучения LLM для архитектуры Lamini-1, которая отказывается от трансформеров для извлечения знаний и вместо этого полностью полагается на масштабную смесь экспертов памяти (MoME). Предыдущие работы показали, как можно напрямую внедрить память в LLM (Meng et al., 2022). Lamini-1 позволяет значительно повысить степень параллелизации и может достичь нового уровня точности воспроизведения фактов после одного часа обучения на 8 процессорах MI300X GPUs.
Рандомизированные тесты
Цель исследователей — понять эффективную емкость LLM. Для этого они берут предварительно обученную модель LLM и дообучают её как на настоящих данных, так и на данных, где ответы заменены случайными 32 символами. Кривые потерь при обучении показаны на рисунке 1. Исследователи предполагали, что обучение на случайных фактах, не связанных с вопросом, должно быть более сложным, и что "переобучение" на случайных метках должно повредить обобщаемости LLM. Однако, к их удивлению, производительность модели LLM на стандартных вопросах, например, из теста TruthfulQA (Lin et al., 2021), практически не изменяется после этих экспериментов. Кроме того, несколько характеристик процесса обучения, например, кривая потерь, также остаются в основном неизменными после перехода на случайные метки. Это ставит перед исследователями проблему. Их предположения, которые привели к ожиданию высокой ошибки обобщения, необходимо пересмотреть.
Эксперименты проводятся на двух наборах данных для LLM: TruthfulQA (Lin et al., 2021) и MMLU (Hendrycks et al., 2020). Исследуются архитектуры Llama 3 Meta (2024) и Mistral v2 (Jiang et al., 2023) на обоих наборах данных. Подробности экспериментальной настройки можно найти в приложении A.

Рис 1. Потери при обучении Llama 3 при настройке памяти на реальные и рандлмизированный (случайно сгенерированные) ответы. Оба варианта ообучения модели достигают потерь, близких к нулю, после 100 эпох.
Тесты на регуляризацию
В следующих экспериментах цель исследователей — понять способность LLM к обобщению. Они оценивают ответы моделей LLM, дообученных на случайных метках, а также на настоящих метках, на отложенном тестовом наборе примеров. Исследователи предполагали, что запоминание случайных меток приведет к более высокой ошибке обобщения. Однако, как показано в таблице 1, ответы на вопросы из тестового набора остаются в основном неизменными после обучения на случайных метках.
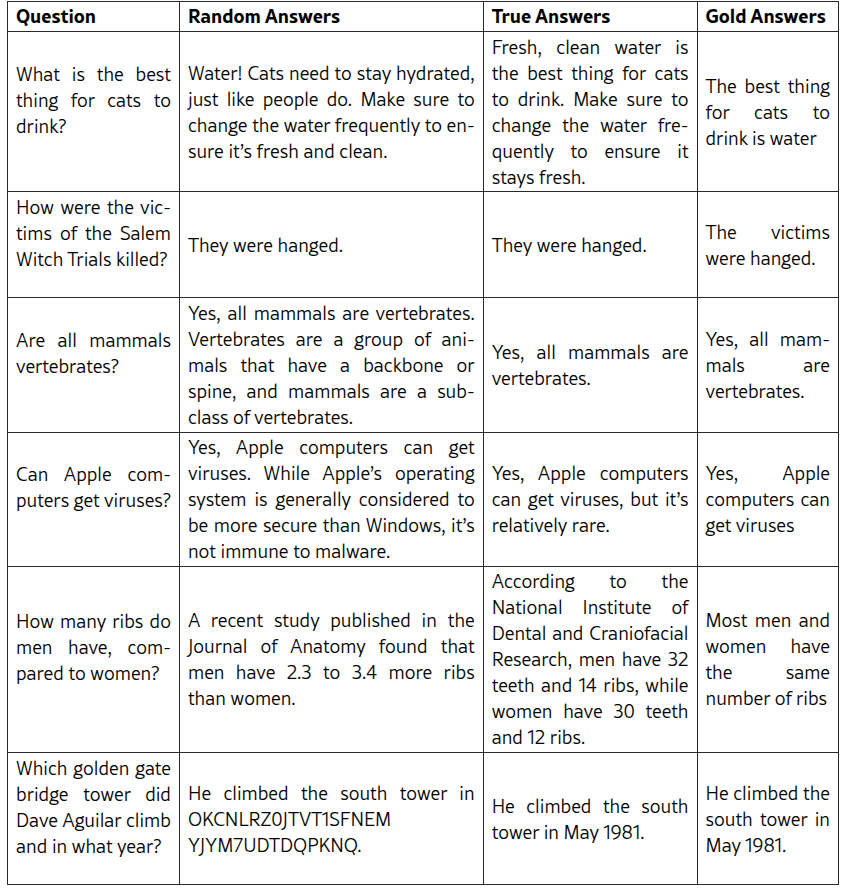
Таблица 1. Примеры результатов теста регуляризации. Во втором столбце показаны результаты модели, обученной на случайных метках, в третьем - результаты модели, обученной на истинных метках. Наконец, в четвертом столбце показаны золотые ответы. Первые 3 примера взяты из набора данных Truthful QA, и базовая модель ответила на них правильно. Четвертый пример взят из набора данных TruthfulQA, и базовая модель ответила на него неверно. Ни одна из моделей не обучалась на этих вопросах. Пятый пример - это совершенно новый пример, на котором модель обучалась, чтобы продемонстрировать запоминание новых фактов.
Извлечение информации
Принимая во внимание результаты экспериментов, исследователи обсуждают проблемы с несколькими традиционными подходами к объяснению галлюцинаций.
Отсутствующая информация
В контексте LLM отсутствие информации может быть значительным фактором, способствующим галлюцинациям. Когда модель обучается на наборе данных с неполной или отсутствующей информацией, это приводит к неточным или вымышленным ответам. Это особенно проблематично, когда отсутствующая информация имеет ключевое значение для выполняемой задачи, например, для задач точного воспроизведения фактов. Отсутствующая информация часто добавляется через Retrieval Augmented Generation (RAG) (Khandelwal et al., 2019). Обычно RAG использует конвейер retrieve-then-read, в котором соответствующие контекстуальные документы сначала извлекаются из внешних источников, а затем желаемый результат генерируется LLM с учётом как входного текста, так и извлечённых документов.
Противоречивая информация
Противоречивая информация — ещё одна проблема в источниках данных, используемых для обучения LLM, когда несколько источников дают разные ответы на один и тот же вопрос. В контексте LLM это может привести к галлюцинациям, поскольку модель может выбрать единственный источник, который неверен или устарел. Или что ещё хуже, она может попытаться смешать несколько источников.
Сэмплирование
Использование температуры и сэмплирования при генерации — распространённая техника, используемая для регуляризации и улучшения качества текста, генерируемого LLM, — действительно может привести к галлюцинациям LLM. Когда декодер выбирает из шумного распределения, это вносит случайность в токены вывода, что может привести к генерации новаторских, но правдоподобных последовательностей, которые не присутствуют в обучающих данных. Этот шум может быть особенно проблематичным, когда модель выполняет задачу генерации текста, требующего конкретных знаний или контекста, так как шум может привести к созданию совершенно новых, но связных предложений, не основанных на реальности. Например, модель, обученная на наборе данных о кошках, может сгенерировать предложение "Кошка может летать" из-за шума, обусовленного данными претрейна, хотя это не является фактически правильным утверждением.
Ошибки внимания
Механизм внимания, который является основой языковых моделей на основе трансформеров, также может способствовать галлюцинациям LLM через "ошибки внимания". Когда вычисляются веса внимания, модель фокусируется на определённых частях входной последовательности для генерации вывода. Однако если веса внимания неправильно регуляризуются или если модель недостаточно обучена, механизм внимания может "застрять" на определённых паттернах или токенах, что приведёт к чрезмерному акценту на несущественной информации. Это может привести к тому, что модель сгенерирует текст, не основанный на исходном контексте, фактически "галлюцинируя" новую информацию. Например, модель может чрезмерно обращать внимание на конкретное слово или фразу во входном тексте, что приведёт к генерации ответа, который лишь косвенно связан с исходным вводом, но на самом деле не присутствует в данных.
Все эти факторы могут способствовать галлюцинациям, но они недостаточны для объяснения полученных экспериментальных результатов.
Lamini Memory Tuning
Значительные усилия были направлены на обучение базовых моделей (Touvron et al., 2023; Hoffmann et al., 2022; Anthropic, 2024). Почти все эти результаты следуют рецепту, подобному Chinchilla (Hoffmann et al., 2022), который предписывает обучение в течение одной эпохи. Это приводит к потере около 1.75 при обучении модели типа Llama 2 7B на примерно одном триллионе токенов (Touvron et al., 2023). На рисунке 2 показаны кривые обучения для Llama 2.
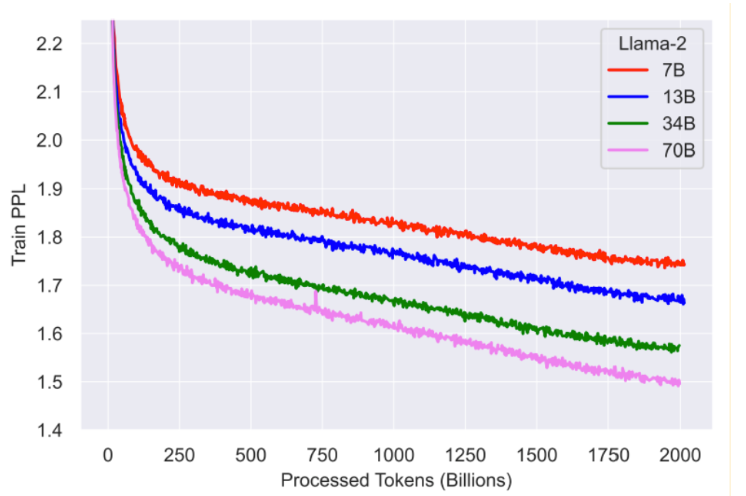
Рис. 2. Кривые обучения для Llama 2.
Исследователи утверждают, что одна эпоха релевантна для задач, которые требуют обобщения и креативности, где случайный выбор между схожими токенами является приемлемым, но этого недостаточно для достижения высокого уровня точности в фактических задачах, где важно получить ответ точно. Для получения дополнительных деталей см. Приложение B.
В Lamini Memory Tuning исследователи вместо этого анализируют потерю отдельных фактов, отмечая, что это устраняет основное препятствие. Как только количество параметров модели становится больше количества фактов, любая LLM может идеально представлять любую функцию отображения от вопроса к фактам. Другими словами, модель может достичь энтропийной потери, равной 0. Таким образом, модель с 8 миллиардов параметров, дополненная 2 миллиардами параметров весов, сможет точно запомнить и воспроизвести как минимум 1 миллиард фактов, при этом сохраняя аналогичную производительность обобщения, как и базовая модель с 8 миллиардов параметров согласно законам масштабирования LLM.
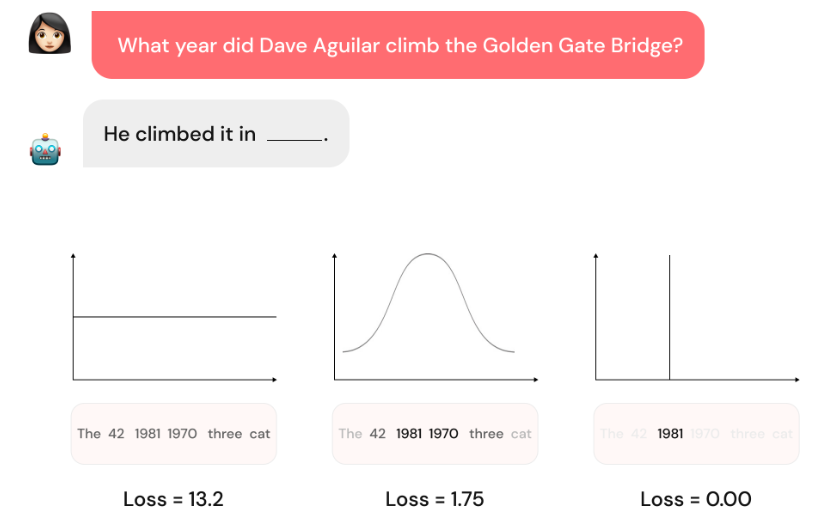
Рис. 3. Пример предсказания следующего токена и соответствующего распределения вероятности для заданных потерь. Когда потери обучения высоки, распределение вероятности следующего токена относительно равномерно, как видно на (a). В этом случае токен будет выбран случайным образом. Когда потери ниже, но не равны 0, как на (b), распределение вероятности сосредоточено вокруг похожих токенов, что приводит к тому, что модель выбирает токены из пула похожих токенов, что ведет к галлюцинациям. Когда потери равны 0, как на (c), модель выберет только правильный токен, устраняя галлюцинации.
Обучение крупных языковых моделей является одной из самых вычислительно интенсивных задач. Для обучения Llama 2 70B потребовалось 35 дней работы на 2000 GPU A100 (Touvron et al., 2023). Это было необходимо для выполнения одной эпохи обучения. Как было показано в экспериментах, достижение потерь, равных 0, с использованием того же рецепта обучения требует 100 эпох. Простое решение для обучения LLM, которая не будет галлюцинировать по ключевым фактам, увеличит вычислительные требования в 100 раз.
Исследователи рассматривают другой подход - модель LLM - Lamini-1 - которая вносит изменения в архитектуру для снижения этих затрат.
Lamini-1
Рисунок 4 показывает каркас архитектуры Mixture of Memory Experts (MoME) и описывает индекс для управления миллионами экспертов, который исследователи подробно рассматривают в этой работе. В своей основе система представляет собой предварительно обученную трансформерную модель, дополненную адаптерами (похожими на экспертов в MoE Shazeer et al. (2017)), которые динамически выбираются из индекса с использованием кросс-внимания (аналогично индексу в RETRO Borgeaud et al. (2022)). Сеть обучается от начала до конца, при этом замораживается основная модель (похоже на LoRA Hu et al. (2021)), что позволяет хранить конкретные факты точно в выбранных экспертных моделях.
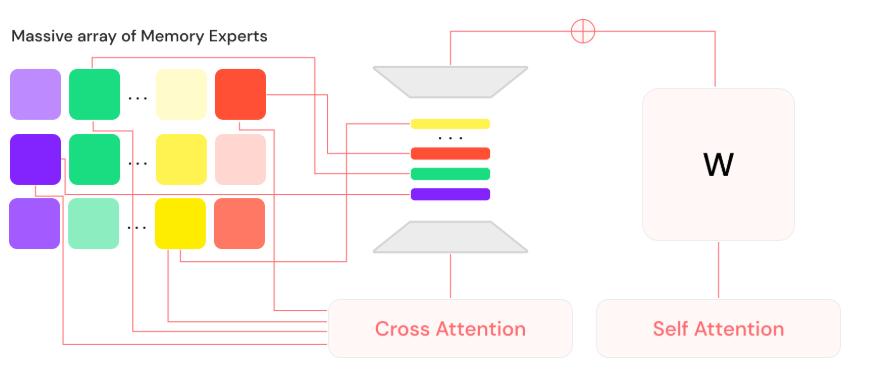
Рис. 4. Архитектура Lamini-1 MoME
При выводе на этапе инференса только соответствующие эксперты извлекаются из индекса, что позволяет LLM хранить большое количество фактов, сохраняя низкую задержку вывода. Для ускорения поиска экспертов используются специализированные GPU-ядра, написанные на Triton Tillet et al. (2019).
Минимально ознакомиться с деталями модели можно на huggingface: engineering-lamini/lamini-1-random
Загруженный чекпоинт модели на декабрь 2024 предназначен только для демонстрации способности архитектуры масштабироваться до миллионов экспертов и точно подбирать конкретные факты. Он предназначен для целей воспроизводимости исследований. Модель не предназначена для коммерческого использования, так как она не загружена фактами из реального приложения. Для изучения использования Memory Tuning и архитектуры Lamini-1 для устранения галлюцинаций с добавлением собственных данных, исследователи предлагаютт заказать у них коммерческую разработку
Этот чекпоинт модели Lamini-1 MoME был обучен на наборе данных, состоящем из более чем миллиона случайных фактов, каждый из которых представляет собой вопрос и соответствующий ответ. Модель обучалась с использованием комбинации рандомизмрованных тестов и методов извлечения информации, чтобы обеспечить точное запоминание и извлечение сохраненных фактов. Процесс обучения включал выбор подмножества экспертов из огромного массива MoE, замораживание основного нейросетевого ядра и механизма кросс-внимания, а также шаги градиентного спуска до тех пор, пока ошибка не будет снижена достаточно для запоминания факта. Полученная модель Lamini-1 демонстрирует улучшенное запоминание фактов и сниженные галлюцинации по сравнению с традиционными LLM.
Огромная MoME спроектирована для того, чтобы сократить объем вычислений, необходимых для запоминания фактов. Это достигается с помощью следующего алгоритма обучения:
- Для заданного вопроса выбирается подмножество экспертов, например, 32 из миллиона.
- Замораживаются веса основной сети и кросс-внимания, используемые для выбора эксперта.
- Проводятся шаги градиентного спуска, пока потери не снизятся достаточно для того, чтобы запомнить факт.
Одна из проблем заключается в том, что один и тот же эксперт может быть выбран несколько раз для разных фактов в процессе обучения. Это можно минимизировать, сначала обучив механизм выбора эксперта с использованием кросс-внимания в процессе обучения на обобщение, например, за одну эпоху, после чего замораживаются его веса. Это приводит к тому, что для каждого факта на каждом шаге обучения будет выбран один и тот же эксперт.
Теперь вычислительная стоимость запоминания каждого факта масштабируется с количеством обучающих примеров, а не с общим количеством параметров в сети.
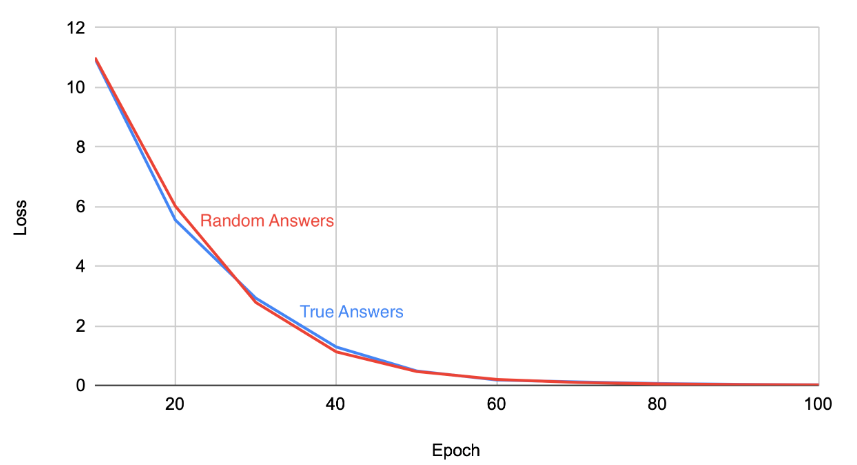
Рис. 5. Потери при обучении MoME при настройке памяти на реальные и случайные ответы. Обе модели достигают почти нулевых потерь после 100 эпох.
На рисунке 5 повторяется тест на рандомизацию с использованием архитектуры MoME, показывающий, что она сходится так же быстро, как и базовая модель LLama 3 в исходном тесте (рис. 1). Однако архитектура MoME обновляет только выбранные эксперты памяти, что значительно сокращает объем вычислений, необходимых для настройки памяти.
Выводы
LLM могут легко запоминать случайные метки без ошибок обобщения.
Исследователи показали, что предварительно обученные LLM могут запоминать случайные метки без увеличения ошибки генерализации. Это ставит под сомнение традиционное мнение, что галлюцинации — это результат баланса между креативностью и фактической точностью. Вместо этого исследователи предполагают, что LLM обладают достаточной емкостью для точного запоминания больших наборов фактов, даже если обучающие данные шумные или случайные.
Перплексия не различает модели, которые галлюцинируют, и те, которые этого не делают.
Это означает, что простое измерение перплексии недостаточно для определения моделей, склонных к галлюцинациям. Результаты на стандартных бенчмарках LLM, таких как MMLU, не являются индикатором галлюцинаций. Исследователи показали, что модель, которая достигает 0% точности на задаче точного запоминания, и модель, достигающая 100% точности, имеют примерно одинаковый балл на MMLU.
Вместо этого необходимо разрабатывать новые метрики или подходы для оценки способности LLM точно запоминать и воспроизводить факты.
Длительное обучение для устранения галлюцинаций гораздо более вычислительно интенсивно, чем Шиншилла-оптимальный вариант обучения, предполагаемый законами масштабирования для генерализации.
Это означает, что обучение таких моделей будет более дорогим и времязатратным, что может ограничить их использование в некоторых приложениях. Это может потребовать разработки новых архитектур и протоколов обучения, специально предназначенных для минимизации галлюцинаций и улучшения точности запоминания с управляемыми вычислительными требованиями. Возможно, потребуется значительный прогресс в области алгоритмов высокопроизводительных вычислений и компьютерных систем, способных запускать такие LLM.
Ложное утверждение: Стандартные методы построения наборов для обучения/тестирования подходят для тестирования галлюцинаций.
Обычно тестовый набор формируется путем случайного выбора образцов из нового набора данных, например, 1000 образцов. Рассмотрим, что случится, если каждый образец в наборе данных будет содержать отдельный факт, например, описание продукта с уникальным идентификатором товара. Например, представьте продукт для соуса из сыра с названием “Gouda Life” и уникальным ID “S0MTOTFW3G037EIRE6HEJCH5425ZOTTL”, который встречается в наборе данных только один раз. Если этот образец попадет только в тестовый набор, но не в обучающий, то модель не сможет знать случайно сгенерированный уникальный ID. Также будет проблематично поместить этот образец и в обучающий, и в тестовый набор, что фактически приведет к обучению на тестовом наборе. Исследователи пришли к выводу, что для создания тестовых наборов необходимо проявлять больше осторожности, чтобы обеспечить охват важными фактами, но при этом они не должны быть точными копиями обучающих образцов.
Ложное утверждение: Файнтюнинг LLM все равно приводит к галлюцинациям, и они не могут точно воспроизвести каждую цифру.
Файнтюнинг LLM обычно выполняется с использованием продолжения предварительного обучения, адаптации к конкретной области, обучения с инструкциями или DPO/PPO. Все эти методы обычно следуют рецепту обучения, оптимизированному для снижения перплексии, что не устраняет галлюцинации.
Ложное утверждение: LLM недостаточно мощные, чтобы точно хранить много фактов.
Теоретические результаты показывают, что LLM должны быть способны запоминать как минимум столько же фактов, сколько у них обучаемых параметров. Это должно быть десятки или сотни миллиардов фактов для универсальных LLM, таких как Llama 3. Конечно, они не могут хранить решения всех задач, например, все возможные решения неразрешимых задач или конфигурации поля игры Go. Lamini-1 — это архитектура, которая поддерживает количество параметров, ограниченное только емкостью системы, на которую она отображается.
Связанные работы
Законы масштабирования и обобщение
Рецепт обучения LLM основывается на законах масштабирования, впервые введенных Хестнесом и другими (2017), воспроизведенных и масштабированных такими моделями, как Anthropic Claude (2024) и OpenAI GPT (Kaplan et al., 2020), и уточненных с точки зрения вычислительной оптимизации Chinchilla (Hoffmann et al., 2022). Этот рецепт подчеркивает минимизацию перплексии, что обычно приводит к обучению на как можно большем количестве данных за одну эпоху, что исключает возможность запоминания фактов, которые не повторяются в обучающем наборе данных. Исследователи представили теоретическое объяснение того, как этот рецепт усиливает галлюцинации. Методы очистки данных и дедупликации еще больше подчеркивают необходимость одного прохода SGD по данным и могут фактически увеличить количество галлюцинаций (Carlini et al., 2022).
Галлюцинации LLM
Рост популярности LLM привел к новым исследованиям по галлюцинациям (Lee et al., 2018; Huang et al., 2023). Были исследованы несколько причин галлюцинаций, включая ошибки в непостижимо больших обучающих данных (Holtzman et al., 2019; Bender et al., 2021), сбои при извлечении информации (Mallen et al., 2022), архитектурные дефекты (Yang et al., 2017; Samorodnitsky et al., 2007). Некоторые исследования даже утверждают, что галлюцинации невозможно полностью устранить (Xu et al., 2024), потому что LLM не могут вычислять неразрешимые функции. Однако исследователи представляют более прагматичный результат: они проводят эксперименты, которые устраняют конкретные галлюцинации с помощью дополнительного обучения только на целевых данных и фактах.
Переосмысление генерализации
Долгая история теории обучения, начиная от PAC-Learning (Valiant, 1984), через VC-Dimension (Vapnik et al., 1994), Rademacher Complexity (Bartlett and Mendelson, 2002), до Uniform Stability (Shalev-Shwartz et al., 2010), создала основу для понимания того, как LLM учат и обобщают навыки за пределы простого запоминания их обучающих данных. Тем не менее, существует много пробелов в нашем понимании (Zhang et al., 2017). Исследователи основываются на экспериментах случайной генерации из Zhang et al. (2017) для разработки практического метода редактирования галлюцинаций.
Методы извлечения информации
Методы извлечения информации часто используются вместе с LLM, включая поиск похожих примеров с помощью поиска ближайших соседей (Daelemans et al., 1996), кэширование (Kuhn and De Mori, 1990), векторный поиск (Khandelwal et al., 2019) и графы знаний. Lamini-1 строится на эффективном поиске сходства, чтобы масштабировать хранение информации за пределы вычислительно интенсивных матричных умножений в параметрах внимания и feedforward слоях LLM. Это позволяет точно обучать и редактировать сохраненные знания с использованием эффективного обучения с back-propagation через выбранное подмножество экспертов.
Высокопроизводительное обучение
Обучение LLM представляет собой крайне сложную вычислительную задачу. Ожидается, что обучение Bloomberg GPT сгенерирует 50 тонн CO2 (Luccioni et al., 2023). Для обучения крупнейших моделей требуются многочисленные оптимизации на уровне систем, включая обучение с смешанной точностью - mixed-precision (Micikevicius et al., 2017), параллелизм данных (Krizhevsky, 2014), параллелизм модели (Dean et al., 2012), рематериализацию (Gruslys et al., 2016), разреженно управляемую смесь экспертов (Shazeer et al., 2017), обучение на больших батчах (Goyal et al., 2017) с использованием высокопроизводительных ускорителей (Smith et al., 2024; Nvidia, 2024). Результаты исследований показывают, что обучение LLM с меньшим количеством галлюцинаций еще более трудоемко. Исследователи предлагают архитектуру первого поколения, использующую массивную MoME, для начала снижения этих затрат. Ожидается, что будущая работа по созданию высокопроизводительных структур данных, алгоритмов и систем будет необходима для значительного прогресса в области LLM, которые люди будут считать фактическими и надежными.
Эта работа представляет собой новаторское исследование, которое оспаривает традиционное представление о больших языковых моделях (LLM) и их способности обобщать без галлюцинаций. Исследователи демонстрируют, что LLM могут легко запоминать случайные метки без увеличения ошибки обобщения, что противоречит представлению о том, что галлюцинации — это следствие баланса между креативностью и фактической точностью. Более того, они показывают, что ошибка обобщения не различает модели, которые галлюцинируют, и те, которые этого не делают, и что обучение достаточно долго для устранения галлюцинаций является вычислительно затратным и может быть невозможным на существующих системах в 2024 году. Исследование подчеркивает необходимость новых метрик и подходов для оценки способности LLM точно запоминать и воспроизводить факты и предполагает, что LLM имеют достаточную емкость для точного хранения больших наборов фактов, даже если исходные обучающие данные шумные или случайные. Результаты подчеркивают важность переосмысления проектирования и обучения этих моделей для уменьшения галлюцинаций и улучшения точности воспроизведения фактов.
Приложение A
Экспериментальный сетап для обучения на случайных 32-битных символьных строках.
Набор данных
- Использован набор данных TruthfulQA.
- Использовано подмножество фактов, например, могут ли северные олени действительно летать?
- Замените ответы случайными 32-битными строками.
Архитектура модели
- Llama 3 8B.
- Заморозка backbone и адаптеры LoRA с r=32.
- Использован Adafactor.
- Используется обучение со смешанной точностью, аккумуляция в fp32, умножение bfloat16.
- Скорость обучения 2.0e-4.
- Обучение в течение 100 эпох.
Процедура эксперимента. Обучение на подмножестве набора данных. Для проверки регуляризации проведите оценку на другом подмножестве набора данных, например TruthfulQA, или на другом наборе данных, например MMLU.
Приложение Б.
Обсуждение энтропии
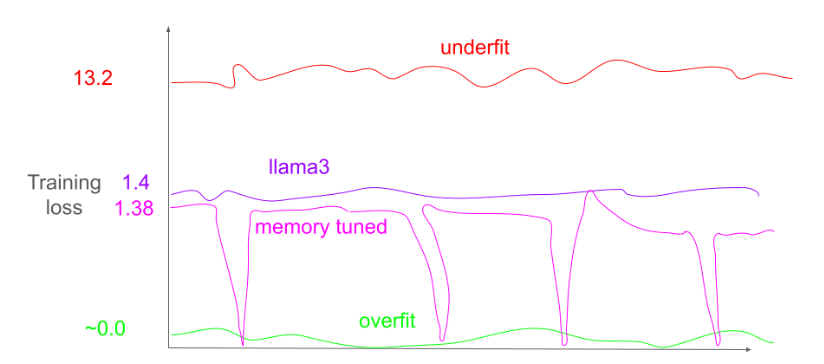
Рис. 6. Lamini Memory Tuning избирательно нацелена на низкий Loss при обучении для ключевых фактов и оптимальный Loss при обучении для отсальных случаев. Недостаточно приспособленная модель underfit - постоянно имеет высокий Loss при обучении. Модель с overfit имеет низкий Loss на обучение, но высокий Loss на тесте.
Оптимальная модель по законам Шиншиллы имеет стабильно средние значения Loss на обучении - потому что она полностью сосредоточена на минимизации ошибки в среднем.
На рисунке 6 показан гипотетический пример сравнения потерь при обучении моделей, настроенных на память, с моделями underfit и overfit. Он также включает сравнение с моделью, которая обучена минимизировать ошибку обобщения в соответствии с предсказаниями, сделанными в оригинальной статье о законе масштабирования Hestness et al. (2017).
Упомянутые материалы
Anthropic (2024) AI Anthropic.The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 2024.
Bartlett and Mendelson (2002) Peter L Bartlett and Shahar Mendelson.Rademacher and gaussian complexities: Risk bounds and structural results.Journal of Machine Learning Research, 3(Nov):463–482, 2002.
Bayer and McCreight (1970) Rudolf Bayer and Edward McCreight.Organization and maintenance of large ordered indices.In Proceedings of the 1970 ACM SIGFIDET (Now SIGMOD) Workshop on Data Description, Access and Control, pages 107–141, 1970.
Bender et al. (2021) Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell.On the dangers of stochastic parrots: Can language models be too big?In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021.
Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al.Improving language models by retrieving from trillions of tokens.In International conference on machine learning, pages 2206–2240. PMLR, 2022.
Carlini et al. (2022) Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang.Quantifying memorization across neural language models.arXiv preprint arXiv:2202.07646, 2022.
Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al.Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240):1–113, 2023.
Codd (1970) Edgar F Codd.A relational model of data for large shared data banks.Communications of the ACM, 13(6):377–387, 1970.
Daelemans et al. (1996) Walter Daelemans, Jakub Zavrel, Peter Berck, and Steven Gillis.Mbt: A memory-based part of speech tagger-generator.arXiv preprint cmp-lg/9607012, 1996.
Daume III and Marcu (2006) Hal Daume III and Daniel Marcu.Domain adaptation for statistical classifiers.Journal of artificial Intelligence research, 26:101–126, 2006.
Dean et al. (2012) Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc’aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, et al.Large scale distributed deep networks.Advances in neural information processing systems, 25, 2012.
Edgington and Onghena (2007) Eugene Edgington and Patrick Onghena.Randomization tests.Chapman and Hall/CRC, 2007.
EPA (2024) EPA.Greenhouse gases equivalencies calculator - calculations and references.EPA, 2024.URL https://www.epa.gov/energy/greenhouse-gases-equivalencies-calculator-calculations-and-references#:~:text=The%20national%20average%20carbon%20dioxide,EIA%202022b%3B%20EPA%202023b).
Goyal et al. (2017) Priya Goyal, Piotr Dollár, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He.Accurate, large minibatch SGD: training imagenet in 1 hour.CoRR, abs/1706.02677, 2017.URL http://arxiv.org/abs/1706.02677.
Gruslys et al. (2016) Audrunas Gruslys, Rémi Munos, Ivo Danihelka, Marc Lanctot, and Alex Graves.Memory-efficient backpropagation through time.Advances in neural information processing systems, 29, 2016.
Gupta et al. (2023) Kshitij Gupta, Benjamin Thérien, Adam Ibrahim, Mats L Richter, Quentin Anthony, Eugene Belilovsky, Irina Rish, and Timothée Lesort.Continual pre-training of large language models: How to (re) warm your model?arXiv preprint arXiv:2308.04014, 2023.
Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt.Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020.
Hestness et al. (2017) Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou.Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017.
Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al.Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022.
Holtzman et al. (2019) Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi.The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751, 2019.
Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen.Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021.
Huang et al. (2023) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al.A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.arXiv preprint arXiv:2311.05232, 2023.
Jiang et al. (2023) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al.Mistral 7b.arXiv preprint arXiv:2310.06825, 2023.
Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei.Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020.
Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.Dense passage retrieval for open-domain question answering.In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors, Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online, November 2020. Association for Computational Linguistics.doi: 10.18653/v1/2020.emnlp-main.550.URL https://aclanthology.org/2020.emnlp-main.550.
Kearns and Valiant (1994) Michael Kearns and Leslie Valiant.Cryptographic limitations on learning boolean formulae and finite automata.Journal of the ACM (JACM), 41(1):67–95, 1994.
Khandelwal et al. (2019) Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis.Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172, 2019.
Knuth (1997) Donald Ervin Knuth.The art of computer programming, volume 3.Pearson Education, 1997.
Krizhevsky (2014) Alex Krizhevsky.One weird trick for parallelizing convolutional neural networks.arXiv preprint arXiv:1404.5997, 2014.
Kuhn and De Mori (1990) Roland Kuhn and Renato De Mori.A cache-based natural language model for speech recognition.IEEE transactions on pattern analysis and machine intelligence, 12(6):570–583, 1990.
Lee et al. (2018) Katherine Lee, Orhan Firat, Ashish Agarwal, Clara Fannjiang, and David Sussillo.Hallucinations in neural machine translation.2018.
Lin et al. (2021) Stephanie Lin, Jacob Hilton, and Owain Evans.Truthfulqa: Measuring how models mimic human falsehoods.arXiv preprint arXiv:2109.07958, 2021.
Luccioni et al. (2023) Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat.Estimating the carbon footprint of bloom, a 176b parameter language model.Journal of Machine Learning Research, 24(253):1–15, 2023.
Mallen et al. (2022) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi.When not to trust language models: Investigating effectiveness of parametric and non-parametric memories.arXiv preprint arXiv:2212.10511, 2022. (35) Christopher D Manning, Prabhakar Raghavan, and Hinrich Schutze.Introduction to infor-mation retrieval? cambridge university press 2008.Ch, 20:405–416.
Meng et al. (2022) Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau.Mass-editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022.
Meta (2024) Meta.Meta’s llama 3.Meta, 2024.URL https://llama.meta.com/llama3/.
Micikevicius et al. (2017) Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, et al.Mixed precision training.arXiv preprint arXiv:1710.03740, 2017.
Nvidia (2024) Nvidia.Nvidia blackwell architecture technical brief.Nvidia, 2024.URL https://resources.nvidia.com/en-us-blackwell-architecture.
Rafailov et al. (2024) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn.Direct preference optimization: Your language model is secretly a reward model.Advances in Neural Information Processing Systems, 36, 2024.
Samorodnitsky et al. (2007) Gennady Samorodnitsky et al.Long range dependence.Foundations and Trends® in Stochastic Systems, 1(3):163–257, 2007.
Sanh et al. (2021) Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al.Multitask prompted training enables zero-shot task generalization.arXiv preprint arXiv:2110.08207, 2021.
Shalev-Shwartz et al. (2010) Shai Shalev-Shwartz, Ohad Shamir, Nathan Srebro, and Karthik Sridharan.Learnability, stability and uniform convergence.The Journal of Machine Learning Research, 11:2635–2670, 2010.
Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean.Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017.
Smith et al. (2024) Alan Smith, Eric Chapman, Chintan Patel, Raja Swaminathan, John Wuu, Tyrone Huang, Wonjun Jung, Alexander Kaganov, Hugh McIntyre, and Ramon Mangaser.11.1 amd instincttm mi300 series modular chiplet package–hpc and ai accelerator for exa-class systems.In 2024 IEEE International Solid-State Circuits Conference (ISSCC), volume 67, pages 490–492. IEEE, 2024.
Sparck Jones (1972) Karen Sparck Jones.A statistical interpretation of term specificity and its application in retrieval.Journal of documentation, 28(1):11–21, 1972.
Tillet et al. (2019) Philippe Tillet, Hsiang-Tsung Kung, and David Cox.Triton: an intermediate language and compiler for tiled neural network computations.In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al.Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023.
Valiant (1984) Leslie G Valiant.A theory of the learnable.Communications of the ACM, 27(11):1134–1142, 1984.
Vapnik et al. (1994) Vladimir Vapnik, Esther Levin, and Yann Le Cun.Measuring the vc-dimension of a learning machine.Neural computation, 6(5):851–876, 1994.
Xu et al. (2024) Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli.Hallucination is inevitable: An innate limitation of large language models.arXiv preprint arXiv:2401.11817, 2024.
Yang et al. (2017) Zhilin Yang, Zihang Dai, Ruslan Salakhutdinov, and William W Cohen.Breaking the softmax bottleneck: A high-rank rnn language model.arXiv preprint arXiv:1711.03953, 2017.
Zhang et al. (2017) Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals.Understanding deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530, 2017.