Instruction tuning LLM - инструктивное обучение больших языковых моделей
Модели, следующие инструкциям, - это уровень искусственного интеллекта конца 2023 года. Первой такой широко нашумевшей моделью стала GPT-3.5, и далее ChatGPT, Claude, Bing Chat и др.
Сейчас в модели стали добавлять разные другие возможности - навык рассуждения (reasoning), вызов функций (function calling) и другие.
Но начало было положено тем, что модели сделали инструктивными. Вы просите модель придумать сказку про синий трактор - и модель придумывает вам такую сказку. Или спросите "как готовить борщ" и модель отвечает вам на вопрос. В общем слушается вашей инструкции и генерирует текст, реализующий вашу просьбу. Многие уже регулярно взаимодействуют с такими моделями и используют их в работе. Инструктивные ИИ модели имеют множество недостатков: они могут генерировать ложную информацию, распространять социальные стереотипы и производить токсичный контент.
Но чтобы сделать даже такое чудо и превратить базовую модель в инструктивню - нужно пройти этап инструктивного дообучения. Исходно базовая модель просто "прочитала" все тексты Интернета и умеет генерировать связно выглядящий текст, а надо получить ИИ чат бота, отвечающего на вопросы и выполняющего просьбы пользователя.
Большие языковые модели (LLMs) обычно обучаются минимизировать ошибку предсказания контекстуального слова на больших корпусах текстов (для GPT это предсказание следующего слова). Однако пользователи ожидают, что модель будет "следовать их инструкциям и делать это этично и безопасно".
Чтобы устранить это несоответствие, был предложен метод дообучения базовых моделей на выполнение инструкций (instruction tuning, IT), который оказался эффективным способом повышения возможностей и управляемости языковых моделей. Этот метод включает дополнительное обучение LLM с использованием пар "инструкция - результат", где инструкция обозначает задачу, поставленную человеком, а результат представляет желаемый ответ, соответствующий инструкции.
Преимущества Instruction tuning заключаются в следующем:
- Дообучение LLM на наборе инструкций сокращает разрыв между задачей предсказания следующего слова, на которой изначально обучаются модели, и целью пользователей, которые ожидают выполнения инструкций.
- Instruction tuning позволяет добиться более управляемого и предсказуемого поведения модели по сравнению со стандартными LLM. Инструкции ограничивают ответы модели, направляя их к желаемым характеристикам или знаниям в определённой области, предоставляя людям возможность вмешиваться в работу модели.
- Instruction tuning является достаточно эффективным и при наличии мощной базовой LLM позволяет быстро адаптироваться к специфическим доменам без необходимости масштабного переобучения или изменения архитектуры модели.
Несмотря на свою эффективность, метод инструктивного обучения сопряжён с рядом сложностей:
- Создание высококачественных инструкций, которые адекватно покрывают целевые задачи, представляет собой нетривиальную задачу. Существующие в открытом Интернет наборы инструкций часто ограничены по объёму, разнообразию и креативности.
- Возникают опасения, что инструктивное дообучение улучшает выполнение только тех задач, которые широко представлены в обучающем наборе данных (Gudibande et al., 2023).
- Метод подвергается критике за то, что он лишь улавливает поверхностные шаблоны и стили (например, формат ответа), а не способствует глубокому пониманию и обучению на решение задач (Kung and Peng, 2023).
На подготовку инструктивных данных вручную OpenAI потратили много сил и денег. И хороший инструктивный датасет - это был существенный фактор успеха Чат ГПТ.
Создание набора инструкций
Каждый элемент в наборе данных инструкций состоит из трёх компонентов:
- Инструкция — текстовая последовательность на естественном языке, описывающая задачу (например, "напишите благодарственное письмо XX за XX", "напишите статью в блог на тему XX" и т. д.).
- Дополнительный ввод (опционально) — контекстная информация, уточняющая или дополняющая задачу - те данные по отношению к которым модель должна исполнить инструкцию.
- Ожидаемый результат — ответ, соответствующий инструкции и дополнительному вводу. То как модель должна правильно ответить.
Существуют три основных подхода к созданию наборов данных инструкций:
-
Ручная разметка - в специальном программном обеспечении люди пишут ответы на вопросы, а затем подготовленные пары вопрос-ответ проверяются также людьми с перекрытием (каждый пример проверяют на корректность несколько человек). Такая разметка очень ресурсозатратна и стоит дорого. Особенно если вам надо привлекать экспертов для написания ответов и перекрестной проверки.
-
Интеграция данных из уже готовых аннотированных наборов данных на естественном языке. В этом подходе пары (инструкция, результат) извлекаются из существующих аннотированных наборов данных на естественном языке. Для этого используются шаблоны, преобразующие пары (текст, метка) в пары (инструкция, результат). Например, наборы данных Flan (Longpre et al., 2023) и P3 (Sanh et al., 2021) построены с использованием подхода интеграции данных.
-
Генерация результатов с использованием крупных языковых моделей (LLMs). Альтернативный способ быстрой генерации желаемых результатов для заданных инструкций заключается в использовании LLM, таких как GPT-3.5-Turbo или GPT-4, или что из сильных ИИ моделей вам доступно, вместо ручного сбора ответов. Источниками инструкций могут быть:
- Инструкции, собранные вручную.
- Расширенные на основе небольшого набора вручную составленных инструкций с помощью LLM.
- Затем собранные инструкции передаются языковым моделям, чтобы получить результаты.
- Датасеты, такие как Alpaca, InstructWild (Xue et al., 2023) и Self-Instruct (Wang et al., 2022c), созданы с использованием этого подхода.
Для создания диалоговых примеров инструктивных данных LLM могут симулировать различные роли (например, пользователя и AI-ассистента) и генерировать сообщения в формате диалога (Xu et al., 2023b).
На основе собранного набора данных инструкций предобученную базовую модель можно дообучить (supervised fine-tuning). В этом процессе модель обучается предсказывать каждый токен результата последовательно, используя инструкцию и дополнительный ввод в качестве исходных данных.
Далее рассказ о состоянии инструктивных дел на основе обзора https://arxiv.org/html/2308.10792v5 сделанного в марте 2024.
Поэтому данные приведенные ниже актуальны на 14 марта 2024. С тех пор утекло много воды и сгорело много видеокарт. Но как хороший исторический срез - пойдет.
Датасеты для инструктивного обучения
Инструктивные датасеты созданные вручную никто особо не опенсорсит. Поэтому в свободном доступе по большей части доминирует или интеграция данных, или синтетика.
Датасеты, созданные вручную или на основе интеграции данных
Такие датасеты включают наборы, которые либо аннотированы вручную, либо напрямую собраны из интернета и отфильтрованы вручную. Для их создания не применяются методы машинного обучения, процесс основан на ручной сборке и проверке уже размеченных ранее данных или написании данных с нуля. В результате такие наборы данных обычно имеют меньший объём. Ниже перечислены наиболее часто используемые наборы данных, созданные вручную или на основе интеграции данных для английского языка.
Natural Instructions
Natural Instructions (Mishra et al., 2021) — это созданный вручную англоязычный набор данных инструкций, включающий 193 тысячи примеров, извлечённых из 61 задачи обработки естественного языка (NLP). Датасет состоит из двух компонентов: "инструкции" и "примеры".
Каждая "инструкция" представляет собой описание задачи, включающее семь компонентов: название, определение, аспекты, которых следует избегать, акценты/предостережения, промпт, положительный пример и отрицательный пример.
"Примеры" состоят из пар ("ввод", "вывод"), где "ввод" представляет собой исходные данные, а "вывод" — текстовый результат, соответствующий данной инструкции.
Данные для набора были собраны из существующих NLP-наборов данных, связанных с 61 задачей. Авторы извлекли "инструкции", ссылаясь на файлы аннотированных инструкций из этих наборов данных. Затем они создали "примеры", унифицировав данные из всех наборов задач в формат пар ("ввод", "вывод").
P3 (Public Pool of Prompts)
P3 (Public Pool of Prompts) (Sanh et al., 2021) — это набор данных для обучения моделей на выполнение инструкций, созданный путём интеграции 170 англоязычных NLP-наборов данных и 2052 англоязычных промптов (prompts). Промпты представлют собой шаблоны, преобразующие данные из стандартной NLP-задачи (например, ответы на вопросы, классификация текста) в пары "ввод-вывод" на естественном языке.
Каждый элемент в P3 состоит из трёх компонентов:
- "Inputs" — последовательность текста, описывающая задачу на естественном языке (например: "Если утверждение 'Он любит Мэри' верно, то верно ли также, что он любит кошку Мэри?").
- "Answer choices" — список текстовых строк, представляющих возможные варианты ответов на данную задачу (например, ["да", "нет", "неопределённо"]).
- "Targets" — текстовая строка, содержащая правильный ответ на указанный "inputs" (например, "да").
Авторы работы P3 даже разработали инструмент PromptSource для совместной работы над подготовкой данных.
Набор данных P3 был создан путём случайного выбора промпта из множества, доступного в PromptSource, и преобразования каждого элемента данных в триплет ("inputs", "answer choices", "targets").
xP3
xP3 (Crosslingual Public Pool of Prompts) (Muennighoff et al., 2022) — это многоязычный набор данных для настройки моделей на выполнение инструкций, включающий 16 различных задач на естественном языке на 46 языках. Каждый элемент в наборе данных состоит из двух компонентов:
- "Inputs" — описание задачи на естественном языке.
- "Targets" — текстовый результат, соответствующий инструкции "inputs".
Оригинальные данные в xP3 поступают из трёх источников:
- Англоязычный набор данных инструкций P3.
- Четыре англоязычные задачи из P3, которые ранее не встречались (например, перевод, написание программного кода).
- 30 мульти-язычных NLP-наборов данных.
Исследователи создали xP3, выбирая вручную написанные шаблоны задач из PromptSource (промпты), а затем заполняя эти шаблоны для преобразования различных NLP-задач в унифицированный формат. Например, шаблон задачи для логического вывода на естественном языке может быть таким: "Если предпосылка верна, то верно ли также, что верно утверждение?" Ответы "да", "может быть", "нет" соответствуют оригинальным меткам задач: "подтверждение (0)", "нейтрально (1)", "противоречие (2)".
Flan 2021
Flan 2021 (Longpre et al., 2023) — это англоязычный набор данных инструкций, созданный путём преобразования 62 широко используемых NLP-бенчмарков (например, SST-2, SNLI, AG News, MultiRC) в пары ввода и вывода на естественном языке.
Каждый элемент в Flan 2021 включает два компонента:
- "Input" — текстовая последовательность, описывающая задачу через инструкцию на естественном языке (например:
Определите тональность предложения 'Он любит кошку.' — положительная или отрицательная?). - "Target" — текстовый результат, корректно выполняющий инструкцию из "input" (например:
положительная).
Исследователи преобразовали стандартные NLP-наборы данных в пары "input-target" с помощью следующей процедуры:
- Составление шаблонов для инструкций и целевых ответов вручную.
- Заполнение шаблонов данными из выбранного набора данных.
LIMA
LIMA (Zhou et al., 2023) — англоязычный набор данных инструкций, который включает обучающий набор с 1 000 элементов данных и тестовый набор с 300 примерами. Обучающий набор состоит из 1 000 пар ("instruction", "response").
Для создания обучающих данных исследователи использовали:
- 75% данных, отобранных с трёх популярных сайтов вопросов и ответов (Stack Exchange, wikiHow и Pushshift Reddit Dataset (Baumgartner et al., 2020)).
- 20% данных, написанных вручную группой авторов
- 5% данных, отобранных из набора Super-Natural Instructions (Wang et al., 2022d).
Для валидационного набора исследователи отобрали 50 примеров, написанных авторами датасета.
Тестовый набор включает 300 примеров, среди которых:
- 76,7% данных написаны авторами датасета
- 23,3% примеров отобраны из Pushshift Reddit Dataset (Baumgartner et al., 2020), который представляет собой коллекцию вопросов и ответов из сообщества Reddit.
Super-Natural Instructions
Super-Natural Instructions (Wang et al., 2022f) — это мультиязычный набор инструкций, включающий 1 616 задач в области обработки естественного языка (NLP) и 5 миллионов примеров задач. Набор охватывает 76 различных типов задач (например, классификация текста, извлечение информации, переписывание текста, составление текста и другие) из 55 языков.
Каждая задача в этом наборе данных включает два компонента:
"Instruction" (инструкция) состоит из следующих частей:
- "Definition" (определение), описывающее задачу на естественном языке.
- "Positive examples" (положительные примеры) — примеры входных данных и правильных выходных данных с коротким объяснением для каждого.
- "Negative examples" (отрицательные примеры) — примеры входных данных и нежелательных выходных данных с коротким объяснением для каждого.
"Task instances" (примеры задач) — это элементы данных, включающие текстовый ввод и список приемлемых текстовых выводов.
- "Input" - сама конкретная задача или вопрос
- "Output" - правильные варианты ответа на вопрос
Первоначальные данные для Super-Natural Instructions были собраны из трёх источников:
- Существующие публичные NLP-наборы данных (например, CommonsenseQA).
- Данные, сгенерированные в ходе краудсорсингового процесса (например, результаты перефразирования вопросов в краудсорсинговых наборах данных QA).
- Синтетические задачи, преобразованные из символических задач и переписанные в виде нескольких предложений (например, алгебраические операции вроде сравнения чисел).
Dolly
Dolly (Conover et al., 2023a) — это англоязычный набор инструкций, включающий 15 000 примеров данных, созданных человеком. Его цель — обучить большие языковые модели (LLMs) взаимодействовать с пользователями так же естественно, как это делает ChatGPT.
Этот набор данных охватывает широкий спектр человеческого поведения, разделённый на 7 типов задач:
-
Открытые вопросы и ответы (Open Q&A): вопросы с произвольным ответом.
Пример: «Почему людям нравятся комедийные фильмы?» -
Закрытые вопросы и ответы (Closed Q&A): вопросы с фиксированным набором ответов.
Пример: «Что больше способствует потомству — инбридинг или аутбридинг?» -
Извлечение информации (Information Extraction): поиск фактов, например, из Википедии.
Пример: «Кто такой Джон Мозес Браунинг?» -
Суммирование информации (Information Summarization): краткое изложение содержания.
Пример: «Пожалуйста, кратко опишите, чем занимается LinkedIn». -
Мозговой штурм (Brainstorming): генерация идей.
Пример: «Придумайте идеи, как управлять своим начальником». -
Классификация (Classification): определение принадлежности к категориям.
Пример: «Определите, какие из этих видов животных вымерли, а какие живы: Palaeophis, Гигантская черепаха». -
Творческое письмо (Creative writing): написание художественных текстов.
Пример: «Напишите короткий рассказ о человеке, который обнаружил скрытую комнату в своём доме».
OpenAssistant Conversations
OpenAssistant Conversations (Köpf et al., 2023) — это набор данных, созданный человеком, содержащий разговоры в стиле ассистента на 35 языках. Набор включает 161 443 сообщения (91 829 запросов пользователей, 69 614 ответов ассистентов) из 66 497 деревьев разговоров на 35 языках, а также 461 292 аннотированных людьми рейтингов качества.
Каждое описание в наборе данных представляет собой дерево разговора (CT). Конкретно, каждый узел в дереве разговора представляет собой сообщение, созданное одной из ролей (пользователь или ассистент) в разговоре. Корневой узел дерева представляет собой исходный запрос от пользователя, а другие узлы — ответы как от пользователя, так и от ассистента. Путь от корня до любого узла в дереве представляет собой валидный разговор между пользователем и ассистентом, который осуществляется поочередно, и называется ветвью.
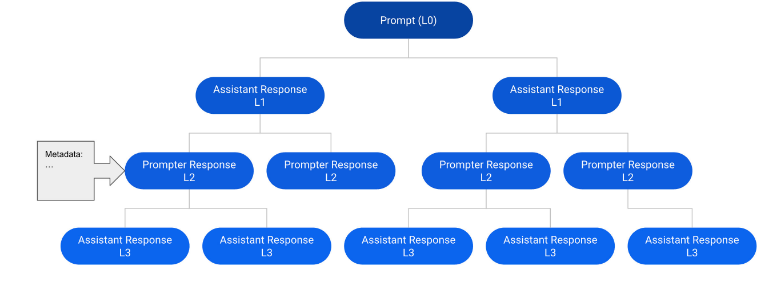
Рис. 1. Пример дерева разговора, состоящего из 12 сообщений в 6 ветвях.
Исследователи собрали деревья разговоров, следуя пятиэтапному процессу:
- Шаг 1. Запрос: участники выполняли роль пользователя и создавали начальные запросы.
- Шаг 2. Оценка запросов: участники оценивали начальные запросы, созданные на шаге 1, и исследователи выбирали высококачественные запросы как корневые узлы, применяя стратегию сбалансированного отбора.
- Шаг 3. Расширение узлов дерева: участники добавляли сообщения-ответы от пользователя или ассистента.
- Шаг 4. Оценка ответов: участники присваивали оценки существующим ответам в узлах.
- Шаг 5. Ранжирование: участники ранжировали ответы ассистентов в соответствии с руководящими принципами для участников.
Машина состояний дерева отслеживала и управляла состоянием (например, начальное состояние, текущее состояние, конечное состояние) на протяжении всего процесса создания разговоров. После этого набор данных OpenAssistant Conversations был построен путём фильтрации оскорбительных и неподобающих вариантов на основе деревьев разговоров.
Синтетические данные через дистилляцию
Синтетические данные создаются с использованием уже готовых сильных предварительно обученных моделей, те эти данные не скачиваются с сайтов типа Reddit или Ответы Mail.ru и не пишутся вручную.
По сравнению с вручную аннотированными или написанными данными, синтетические данные имеют два преимущества:
- Генерация синтетических данных, специфичных для задачи, происходит быстрее и дешевле, чем создание вручную аннотированных данных для инструктивного файн-тюнинга;
- Качество и разнообразие синтетических данных превосходят возможности людей-аннотаторов, копирайтеров и разметчиков, что способствует улучшению производительности и разнообразию данных и в итоге ведет к более широкому обобщению принципов для LLM.
Рассмотрим датасеты для подхода с дистилляцией. Дистилляцией называют передачу знаний и когнитивных способностей от более мощной и умной модели-учителя к менее сложной, но более вычислительно эффективной модели-ученику. Это делается чтобы иметь то же или близкое качество ответов как у учителя, а пользоваться маленькой моделью в несколько раз быстрее и дешевле по вычислениям.
В контексте создания синтетических данных этот процесс включает генерацию запросов и ответов от существующих LLM (например, ChatGPT или o1 от OpenAI) и использование этих запросов и ответов в качестве основы для дальнейшего инструктивного обучения LLM.
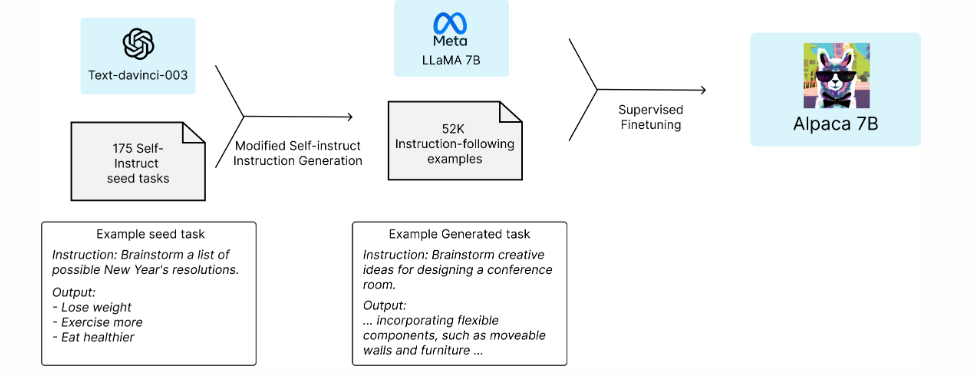
Рис. 2. Alpaca - Taori et al. (2023a) пытаются передать знания модели GPT-3 Brown et al. (2020a) меньшей языковой модели LLaMA-7B Touvron et al. (2023a) за счет генерации синтетического инструктивного датасета.
Alpaca
Alpaca (Taori et al., 2023a), датасет и обученная на основе LLAMA модель, созданные группой Stanford NLP. В этой работе применили подход дистилляции. Базовая модель LLaMA-7B Touvron et al. (2023a) была дообучена на 52 000 примеров инструкций, полученных на основе GPT-3 Brown et al. (2020a), что позволило этой меньшей модели достичь производительности, сравнимой с GPT-3 Brown et al. (2020a).
Это было одно из первых широко известных исследований с инструктивным обучением на синтетических данных. Перед исследователями стояли две ключевые задачи при обучении высококачественной модели, следующей инструкциям, в рамках академического бюджета:
- наличие мощной предобученной языковой модели
- и высококачественных данных для следования инструкциям.
Первая задача была решена благодаря выпуску новых моделей LLaMA от Meta. Для второй задачи исследователи воспользовались подходом, предложенным в статье о self-instruct: использование существующей мощной языковой модели для автоматической генерации данных инструкций.
В частности, Alpaca представляет собой языковую модель, дообученную с использованием метода SFT - обучение на данных с эталонными ответами на базе модели LLaMA 7B. Обучение проводилось на 52 тысячах, сгенерированных моделью text-davinci-003 от OpenAI (Instruct GPT).
Схема на рисунке 2 демонстрирует, как была получена модель Alpaca. Для создания данных исследователи использовали метод self-instruct, дополнив его собственными наработками. В качестве начального набора (seed set) было использовано 175 пар инструкций и ответов, написанных вручную. Затем исследователи использовали text-davinci-003, чтобы на основе начального набора генерировать дополнительные инструкции, используя начальные примеры как контекст. Процесс генерации был улучшен по сравнению с оригинальным методом self-instruct: упрощён пайплайн генерации (подробности доступны на их GitHub), а также значительно снижены затраты. В результате процесса генерации исследователи получили 52 тысячи уникальных инструкций и соответствующих ответов, общая стоимость которых составила менее $500 при использовании API OpenAI.
WizardLM / Evol-Instruct
Вместо простого запроса к модели серии GPT на генерацию инструкций на основе показанных в промте, WizardLM (Xu et al., 2023a) сосредотачивается на том, чтобы получить более разнообразные и качественные инструкции и ответы от GPT-3 (Brown et al., 2020a). Для этого в WizardLM (Xu et al., 2023a) сначала строит пятиуровневую систему запросов, постепенно увеличивая сложность генерации данных. Затем WizardLM (Xu et al., 2023a) расширяет темы запросов через ручное дополнение, тем самым увеличивая разнообразие создаваемых данных. В конечном итоге, после файн-тюнинга открытой модели LLaMA Touvron et al. (2023b), WizardLM (Xu et al., 2023a) достигает более чем 90% от качества ChatGPT OpenAI (2022) по 17 из 29 навыков.
Orca и Orca-2
Orca (Mukherjee et al., 2023) и Orca-2 (Mitra et al., 2023) представляют собой два обширных набора данных для дистилляции, предназначенные для обучения относительно небольших языковых моделей логическому рассуждению. Например, Orca (Mukherjee et al., 2023) включает множество директив рассуждений, таких как "давайте подумаем шаг за шагом" и "обоснуйте ваш ответ", чтобы показать пути рассуждений LLM (например, ChatGPT OpenAI (2022)) при составлении ответов. Развивая эту концепцию, Orca (Mukherjee et al., 2023) включает 1 миллион ответов от GPT-4 OpenAI (2023), в то время как Orca-2 (Mitra et al., 2023) добавляет ещё 817 тысяч ответов от GPT-4 OpenAI (2023). Этот обширный набор данных облегчает обучение навыку рассуждения меньших языковых моделей, позволяя им достигать или даже превосходить производительность исходных моделей GPT-4, которые по слухам в 5–10 раз больше их размера.
Baize
Baize (Conover et al., 2023b) представляет собой англоязычный корпус для диалогов в несколько реплик, включающий 111,5 тысяч примеров, созданных с использованием ChatGPT. Каждый обмен репликами представляет собой вопрос пользователя и ответ ассистента. Для создания набора данных Baize исследователи предложили метод "самостоятельного чата", при котором ChatGPT поочерёдно играет роли пользователя и AI-ассистента, генерируя сообщения в формате диалога.
В частности, сначала исследователи написали промпт для задачи, определяющий формат для ролей пользователя и ассистента для ChatGPT. Затем они отобрали вопросы (например, "Как исправить аккаунт Google Play Store, который не работает?") из наборов данных Quora и Stack Overflow в качестве начальных тем для разговоров (так называемых "seed topics"). После этого ChatGPT запускался с использованием заданного промпта и выбранной темы. ChatGPT продолжал генерировать сообщения для обеих сторон, пока не достигался логичный момент завершения беседы.
Пример используемого промпта
Забудь предыдущие инструкции. Следующий текст — это разговор между человеком и AI-ассистентом. Человек и AI-ассистент поочередно обсуждают тему: '$SEED'.
Реплики человека начинаются с [Human], а реплики AI-ассистента — с [AI].
Человек задаёт вопросы, связанные с темой или предыдущими обсуждениями.
Беседа прекращается, когда у человека больше нет вопросов. AI-ассистент старается не задавать вопросы.
Заверши транскрипт точно в указанном формате.
[Human] Привет!
[AI] Привет! Чем могу помочь? Такой подход позволяет ChatGPT самостоятельно создавать синтетические диалоги, которые затем используются для обучения и анализа.
Наборы данных для дистилляции, специфичной для задач
Помимо вышеупомянутых наборов данных общего назначения, есть еще инструктивные датасеты ShareGPT (RyokoAI/ShareGPT52K), WildChat (Zhao et al., 2024), Vicuna (Zheng et al., 2024) и Unnatural Instructions (Honovich et al., 2022), существуют инициативы, направленные на использование дистилляции для создания наборов данных, которые имитируют возможности крупных языковых моделей (LLMs) в определённых областях.
Например:
- Для генерации кода разработаны такие наборы, как WizardCoder (Luo et al., 2023), Magicoder (Wei et al., 2023b) и WaveCoder (Yu et al., 2023).
- Для задач рассуждения и написания текста созданы Phi-1 (Gunasekar et al., 2023) и Phi-1.5 (Li et al., 2023h).
- Для задач ранжирования используется набор данных Nectar (Zhu et al., 2023a).
Эти специализированные наборы данных позволяют обучать модели в узконаправленных областях, обеспечивая их производительность на уровне крупных языковых моделей.
Синтетические данные через Self-Improvement (самоулучшение)
Концепция Self-Improvement была предложена исследователями под руководством Ванга и др. (2022c). Она подразумевает улучшение способности предобученной базовой модели (например, стандартной версии GPT-3 Brown et al., 2020b) к следованию инструкциям за счёт использования собственных генераций модели. Процесс Self-Improvement, представленный на рисунке 3, включает четыре этапа:
-
Этап 1: Исследователи вручную собрали 175 задач, написанных людьми. Каждая задача включает одну инструкцию и один ожидаемый ответ. Эти данные были добавлены в пул задач в качестве исходного набора.
-
Этап 2: Для генерации инструкций исследователи случайным образом выбрали 8 исходных инструкций из созданного пула задач. Эти инструкции были использованы как примеры в режиме обучения на контексте (in-context learning), чтобы направить стандартную GPT-3 на создание новых инструкций.
-
Этап 3: Для каждой созданной инструкции, если она относится к задаче с заранее заданным ответом (например, написание текста), стандартная GPT-3 сразу генерировала соответствующий ответ. Если инструкция касалась задачи с заранее заданным вводом (например, понимание текста), модель сначала генерировала необходимый контекст, а затем соответствующий ответ.
-
Этап 4: Созданные примеры в формате «инструкция-ответ» фильтровались с использованием набора правил или моделей.
Следуя этому процессу, Ванг и др. (2022c) создали набор данных Self-Instruct, состоящий из 52 тысяч инструкций. Дальнейшие оценки показали, что GPT-3 Brown et al. (2020a), дообученная с использованием Self-Instruct, значительно превосходит аналоги, оставляя всего 5% абсолютного разрыва с InstructGPT (Ouyang et al., 2022).
Процесс самоулучшения основывается на генерации синтетических данных непосредственно самой моделью, что требует наличия мощной базовой языковой модели. Без такой модели этот цикл самоулучшения может ограничиваться изначальными возможностями модели и усугублять существующие предвзятости или ошибки. Несмотря на эти риски, работа в области самоулучшения продолжает приносить значительные результаты.
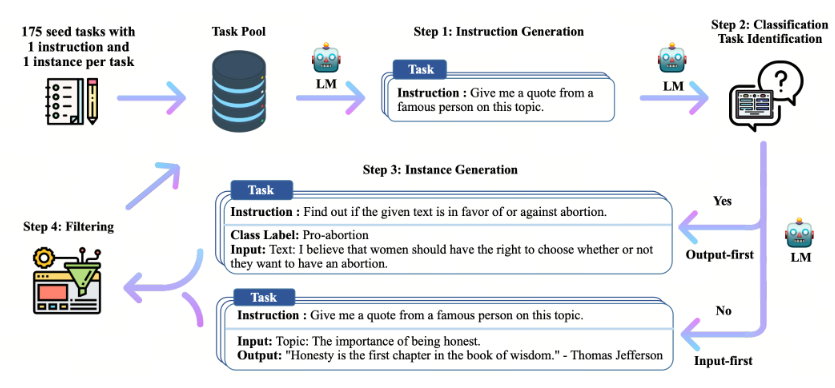
Рис. 3. Общий пайплайн Self-Improvement для генерации синтетических данных.
SPIN
SPIN (Chen et al., 2024b), расшифровывающееся как Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, представляет собой специализированный подход к самоулучшению, основанный на механизме самоигры. В этом подходе основной участник (языковая модель) проходит процесс дообучения, чтобы различать ответы предыдущей версии модели и целевое распределение данных. Этот процесс итеративно адаптирует языковую модель, приближая её к желаемому распределению данных.
Конкретнее, исследователи рассматривают существующую версию языковой модели как pθt, которая используется для генерации ответа y′ на заданный запрос x из набора данных с инструкциями, размеченными человеком. Задача состоит в разработке новой языковой модели pθt+1, способной различать y′ — ответ, созданный предыдущей моделью pθt, и y — ответ, сгенерированный человеком.
Этот процесс напоминает игру с двумя игроками, где первичный игрок, более новая модель pθt+1, стремится определить различия между ответами её оппонента pθt и теми, которые созданы человеком. В то же время противник (предыдущая версия модели pθt) пытается генерировать ответы, максимально приближенные к данным из размеченного набора. Дообучение предыдущей модели pθt с акцентом на человекоподобные ответы приводит к созданию новой модели pθt+1, которая лучше согласуется с целевым распределением данных.
На следующих итерациях улучшенная модель pθt+1 принимает на себя роль оппонента в генерации ответов. Конечная цель механизма самосостязательной игры заключается в эволюции языковой модели до состояния, при котором pθ*=phuman, то есть до момента, когда самая продвинутая версия языковой модели больше не сможет отличать ответы своей предшественницы от тех, что созданы человеком.
SPIN (Chen et al., 2024b) представляет собой вариант подхода к самоулучшению, который позволяет языковым моделям совершенствоваться без привлечения дополнительных данных от человека или обратной связи от более мощных моделей. Экспериментальные результаты показывают, что SPIN значительно повышает производительность языковых моделей на ряде тестов, превосходя даже те модели, которые были обучены с использованием дополнительных данных от человека или обратной связи от внешних ИИ-систем.
Обратный перевод инструкций
Обратный перевод инструкций (Li et al., 2023g), также известный как Self Alignment with Instruction Backtranslation, представляет собой специализированный подход к самоулучшению. В отличие от метода Wang et al. (2022c), который фокусируется на генерации ответов для инструкций, предоставленных человеком, Li et al. (2023g) применяют противоположную стратегию: создают инструкции для текстов, собранных из открытых источников. Для достижения этой цели исследователи используют следующую пятиступенчатую схему:
-
Шаг 1:
- Собираются: немаркированные тексты из Clueweb (Overwijk et al., 2022), предполагая, что эти тексты могут быть связаны с качественными инструкциями;
- 3200 примеров данных в формате «инструкция-ответ», написанных человеком, для использования в качестве исходного набора данных.
-
Шаг 2: На основе модели обратного перевода, использующей LLaMA (Touvron et al., 2023b) в качестве основы, проводится обучение на собранных исходных данных. Эта модель принимает ответ как входные данные и генерирует инструкцию в качестве выхода. После обучения модель применяется для извлечения инструкций из немаркированных текстов.
-
Шаг 3: Собранные немаркированные тексты передаются обученной модели обратного перевода, что приводит к созданию большого объема данных в формате «инструкция-ответ».
-
Шаг 4: Обучается оценочная модель на основе LLaMA (Touvron et al., 2023b), использующая исходные данные. Эта модель принимает инструкцию как входные данные и генерирует соответствующий ответ, который затем применяется для оценки каждой пары «инструкция-ответ», созданной на предыдущем шаге.
-
Шаг 5: Отфильтровываются низкокачественные пары «инструкция-ответ», а оставшиеся данные используются для дообучения языковых моделей.
Применяя описанный процесс, Li et al. (2023g) генерируют 502 тыс. синтетических пар инструкция - ответ. Модель LLaMA (Touvron et al., 2023b), дообученная на этом размеченном наборе данных, превосходит все другие модели на основе LLaMA в Alpaca leaderboard, при этом данные дистиляции никак не используются в этом подходе, что демонстрирует высокоэффективный процесс самоулучшения.
Инструктивные модели
InstructGPT
InstructGPT (176B) (Ouyang et al., 2022) была создана на основе GPT-3 (176B) (Brown et al., 2020b) и затем дообучена с использованием инструкций, предоставленных людьми. Процесс дообучения включает три этапа:
- Этап 1. Инструктивное дообучение (SFT): На этом этапе исследователи использовали набор данных с инструкциями, отобранными людьми, который был сформирован на основе истории API Playground.
- Этап 2. Обучение модели вознаграждений (reward-model): Эта модель предназначена для предсказания предпочтений человека на основе размеченного набора данных. Данные формировались путем выборки нескольких ответов на одну инструкцию и их ранжирования от лучшего до худшего.
- Этап 3. Оптимизация модели: Модель, дообученная на этапе 1, дополнительно оптимизировалась с использованием новых инструкций и модели вознаграждений, обученной на этапе 2. Для обновления параметров применялся метод оптимизации проксимальной политики (PPO) (Schulman et al., 2017), представляющий собой метод обучения с подкреплением на основе градиента политики.
Этапы 2 и 3 чередовались несколько раз до тех пор, пока производительность модели не переставала значительно улучшаться.
Общие результаты показали, что InstructGPT превосходит GPT-3.
Автоматическая оценка:
-
InstructGPT улучшила показатели GPT-3 на 10% по набору данных TruthfulQA (Lin et al., 2021) с точки зрения правдивости и на 7% по набору RealToxicityPrompts (Gehman et al., 2020) с точки зрения токсичности.
-
На NLP-наборах данных, таких как WSC, производительность InstructGPT сопоставима с GPT-3.
Оценка человеком:
- В четырех аспектах — следование корректным инструкциям, соблюдение явных ограничений, уменьшение галлюцинаций и генерация соответствующих ответов — InstructGPT улучшила показатели GPT-3 на +10%, +20%, -20% и +10% соответственно.
BLOOMZ
BLOOMZ (176B) (Muennighoff et al., 2022) была создана на основе модели BLOOM (176B) (Scao et al., 2022) и затем дообучена на наборе данных с инструкциями xP3 (Muennighoff et al., 2022). Этот набор представляет собой коллекцию данных с инструкциями на 46 языках, собранных из двух источников:
- P3: коллекция пар (инструкция на английском, ответ на английском).
- Набор данных (инструкция на английском, ответ на нескольких языках): сформированный из мультиязычных NLP-наборов данных (например, китайских бенчмарков) путем заполнения шаблонов задач заранее определенными инструкциями на английском языке.
Автоматическая оценка:
- Результаты BLOOMZ превосходят показатели BLOOM в условиях zero-shot (без примеров в промпте, только инструкция) на:
- +10.4% в задачах на разрешение кореференции,
- +20.5% в задачах на дополнение предложений,
- +9.8% в задачах на вывод в естественном языке.
На бенчмарке HumanEval (Chen et al., 2021) BLOOMZ превосходит BLOOM на 10% по метрике Pass@100. В генеративных задачах BLOOMZ показывает улучшение на +9% по метрике BLEU в сравнении с BLOOM на платформе lm-evaluation-harness.
Эти результаты подчеркивают значительное улучшение модели BLOOMZ относительно ее предшественника в различных задачах обработки естественного языка и генерации текста.
Flan-T5
Flan-T5 (11B) представляет собой языковую модель, созданную на основе базовой модели T5 (11B) (Raffel et al., 2019) и дообученную на наборе данных FLAN (Longpre et al., 2023). Набор данных FLAN состоит из пар (инструкция, ответ), сформированных на основе 62 наборов данных, относящихся к 12 задачам обработки естественного языка (например, вывод в естественном языке, рассуждения на основе здравого смысла, генерация перефразировок), путем заполнения шаблонов разнообразными инструкциями в рамках единого формата задач.
В процессе дообучения Flan-T5 исследователи использовали фреймворк T5X на базе JAX и выбирали лучшую модель, оцененную на отложенных задачах каждые 2000 шагов. По сравнению с этапом предобучения T5, дообучение Flan-T5 потребовало лишь 0,2% вычислительных ресурсов (примерно 128 TPU v4 в течение 37 часов).
Результаты оценки:
Flan-T5 (11B) превосходит T5 (11B) и демонстрирует сопоставимые результаты с более крупными моделями, включая PaLM (60B) (Chowdhery et al., 2022), в условиях few-shot (использование в промте нескольких примеров). Flan-T5 показывает следующие улучшения по сравнению с T5:
- +18.9% на MMLU (Hendrycks et al., 2020),
- +12.3% на BBH (Suzgun et al., 2022),
- +4.1% на TyDiQA (Clark et al., 2020),
- +5.8% на MGSM (Shi et al., 2022),
- +2.1% в задачах открытой генерации,
- +8% на RealToxicityPrompts (Gehman et al., 2020).
В условиях few-shot Flan-T5 превосходит PaLM на +1.4% и +1.2% на наборах данных BBH и TyDiQA соответственно.
Эти результаты демонстрируют эффективность дообучения Flan-T5 и её способность конкурировать с более крупными языковыми моделями в различных задачах обработки естественного языка.
Alpaca
Alpaca (7B) (Taori et al., 2023a) — языковая модель, обученная на базе LLaMA (7B) (Touvron et al., 2023a), которая была дообучена на созданном наборе данных инструкций, сгенерированном моделью InstructGPT (175B, text-davinci-003) (Ouyang et al., 2022). Процесс дообучения занял около 3 часов на устройстве с 8 картами A100 80GB с использованием смешанной точности (mixed-presicion) и FSDP (fully shared data parallelism).
Alpaca (7B) демонстрирует сопоставимые результаты с InstructGPT (175B, text-davinci-003) в рамках оценки людьми. В частности, Alpaca превосходит InstructGPT на наборе данных self-instruct, получив 90 победных примеров по сравнению с 89 у InstructGPT.
Vicuna
Vicuna (13B) (Chiang et al., 2023) — языковая модель, обученная на базе LLaMA (13B) (Touvron et al., 2023a), дообученная на диалоговом наборе данных ShareGPT, сгенерированном с помощью ChatGPT краудсорсингом.
Авторы собрали опубликованные пользователями диалоги на платформе ShareGPT.com, и отфильтровали низкокачественные записи, оставив 70 тыс. диалогов. LLaMA (13B) была дообучена на этом наборе данных с использованием модифицированной функции потерь, предназначенной для длинных диалогов. Чтобы лучше обрабатывать длинные контексты в диалогах, авторы увеличили максимальную длину контекста с 512 до 2048 токенов. Для тренировки они использовали техники gradient checkpointing и flash attention (Dao et al., 2022), чтобы уменьшить потребление памяти GPU в процессе дообучения. Процесс дообучения занял 24 часа на устройстве с 8 картами A100 80GB с FSDP (fully shared data parallelism).
Авторы создали тестовый набор, который использовался исключительно для оценки производительности чат-ботов. Они собрали тестовый набор, состоящий из 8 категорий вопросов, таких как задачи Ферми, ролевые сценарии, задачи по программированию/математике и другие, а затем попросили GPT-4 (OpenAI, 2023) оценить ответы моделей по таким критериям, как полезность, релевантность, точность и подробность.
На созданном тестовом наборе Vicuna (13B) превзошла Alpaca (13B) (Taori et al., 2023a) и LLaMA (13B) по 90% вопросов теста, а также сгенерировала ответы, равные или лучшие по сравнению с ChatGPT в 45% случаев.
GPT-4-LLM
GPT-4-LLM (7B) (Peng et al., 2023) — языковая модель, обученная путем дообучения LLaMA (7B) (Touvron et al., 2023a) на наборе данных инструкций, сгенерированных GPT-4 (OpenAI, 2023). GPT-4-LLM инициализируется с LLaMA, затем дообучается в два этапа:
- supervised fine-tuning (SFT) на созданном наборе данных инструкций. Исследователи использовали инструкции из Alpaca (Taori et al., 2023a), а затем собрали ответы, сгенерированные GPT-4. LLaMA дообучается на наборе данных, сгенерированном GPT-4. Процесс дообучения занимает примерно три часа на машине с 8 картами A100 80GB, с использованием смешанной точности и полного параллелизма данных.
- оптимизация модели с шага 1 с использованием метода proximal policy optimization (PPO) (Schulman et al., 2017). Исследователи сначала создали набор для сравнения, собрав ответы от GPT-4, InstructGPT (Ouyang et al., 2022) и OPT-IML (Iyer et al., 2022) на набор инструкций, а затем попросили GPT-4 оценить каждый ответ от 1 до 10. Используя оценки, обучалась модель вознаграждения на основе OPT (Zhang et al., 2022a). Модель, дообученная на шаге 1, оптимизируется с использованием модели вознаграждения для вычисления градиента политики.
На основе оценок GPT-4-LLM (7B) превосходит не только базовую модель Alpaca (7B), но и более крупные модели, включая Alpaca (13B) и LLaMA (13B). По автоматическим оценкам GPT-4-LLM (7B) превосходит Alpaca по данным User-Oriented-Instructions-252 (Wang et al., 2022c), Vicuna-Instructions (Chiang et al., 2023) и Unnatural Instructions (Honovich et al., 2022) на 0.2, 0.5 и 0.7 соответственно.
По оценкам людьми по таким аспектам, как полезность, честность и безвредность, GPT-4-LLM превосходит Alpaca на 11.7, 20.9 и 28.6 соответственно.
Claude
Claude5 — языковая модель, основанная на инструктивном дообучении базовой модели. Процесс дообучения состоит из двух этапов:
-
supervised fine-tuning (SFT) на наборе инструкций. Исследователи создали набор инструкций, собрав 52 тыс. различных инструкций, которые были дополнены ответами, сгенерированными GPT-4. Процесс дообучения занял примерно восемь часов на машине с 8 картами A100 80GB, с использованием смешанной точности и FSDP.
-
оптимизация модели с шага 1 с использованием метода proximal policy optimization (PPO). Исследователи сначала создали набор для сравнения, собрав ответы от нескольких крупных языковых моделей (например, GPT-3 (Brown et al., 2020b)) на данный набор инструкций, а затем попросили GPT-4 (OpenAI, 2023) оценить каждый ответ. Используя оценки, обучалась модель вознаграждения. Затем дообученная модель с шага 1 оптимизировалась с использованием модели вознаграждения методом PPO.
Claude генерирует более полезные и безвредные ответы по сравнению с базовой моделью. На автоматических оценках Claude превосходит GPT-3 на 7% по данным RealToxicityPrompts (Gehman et al., 2020) по показателю токсичности. По оцнкам людьми четырех различных аспектов, включая следование правильным инструкциям, соблюдение явных ограничений, меньшее количество галлюцинаций и генерацию соответствующих ответов, Claude превосходит GPT-3 (Brown et al., 2020b) на +10%, +20%, -20% и +10% соответственно.
WizardLM
WizardLM (7B) (Xu et al., 2023a) — языковая модель, обученная путем дообучения LLaMA (7B) (Touvron et al., 2023a) на наборе данных инструкций Evol-Instruct, сгенерированных ChatGPT. Она была дообучена на подмножестве (с 70 тыс. примеров) Evol-Instruct для обеспечения сравненимости с Vicuna (Chiang et al., 2023). Процесс дообучения занимает примерно 70 часов за 3 эпохи с использованием 8 GPU V100 и техники Deepspeed Zero-3 (Rasley et al., 2020). Во время инференса максимальная длина генерации составляет 2048 токенов.
Для оценки производительности LLM на сложных инструкциях исследователи собрали 218 инструкций, созданных людьми, из реальных диалогов (например, открытые проекты, платформы и форумы), которые вошли в тестовый набор Evol-Instruct.
Оценки проводятся на тестовом наборе Evol-Instruct и тестовом наборе Vicuna. При оценке людьми WizardLM значительно превосходит Alpaca (7B) (Taori et al., 2023a) и Vicuna (7B), генерируя равные или лучшие ответы на 67% тестовых примеров по сравнению с ChatGPT. Автоматическая оценка проводится путем запроса у GPT-4 сравнения ответов моделей. В частности, WizardLM демонстрирует улучшение производительности по сравнению с Alpaca на +6.2% и +5.3% на тестовых наборах Evol-Instruct и Vicuna. WizardLM превосходит Vicuna на +5.8% на тестовом наборе Evol-Instruct и на +1.7% на тестовом наборе Vicuna.
ChatGLM2
ChatGLM2 (6B) (Du et al., 2022) — языковая модель, обученная путем дообучения GLM (6B) (Du et al., 2022) на двух-язычном наборе данных, содержащем как английские, так и китайские инструкции. Двуязычный набор данных инструкций включает 1.4 трлн токенов с соотношением 1:1 между китайским и английским языками. Инструкции в наборе данных взяты из задач вопрос-ответ и дополнены примерами диалогов. ChatGLM инициализируется с GLM, затем обучается по трехступенчатой стратегии дообучения, аналогичной InstructGPT (Ouyang et al., 2022). Для лучшего моделирования контекстной информации в многошаговых диалогах исследователи увеличили multi-query attention и causal mask strategies. Во время инференса ChatGLM2 требует 13 ГБ памяти GPU с FP16 и поддерживает диалоги длиной до 8 тыс. токенов с 6 ГБ памяти GPU с использованием техники квантования модели INT4.
Оценки проводятся на четырех английских и китайских бенчмарках, включая MMLU (английский) (Hendrycks et al., 2020), C-Eval (китайский) (Huang et al., 2023), GSM8K (математика) (Cobbe et al., 2021) и BBH (английский) (Suzgun et al., 2022). ChatGLM2 (6B) превосходит GLM (6B) и базовую модель ChatGLM (6B) на всех бенчмарках. В частности, ChatGLM2 превосходит GLM на +3.1 по MMLU, +5.0 по C-Eval, +8.6 по GSM8K и +2.2 по BBH. ChatGLM2 показывает лучшие результаты по сравнению с ChatGLM на +2.1, +1.2, +0.4 и +0.8 на MMLU, C-Eval, GSM8K и BBH соответственно.
LIMA
LIMA (65B) (Zhou et al., 2023) — большая языковая модель, обученная путем дообучения LLaMA (65B) (Touvron et al., 2023a) на наборе инструкций, который был построен на основе предложенной гипотезы поверхностного выравнивания - superficial alignment.
Гипотеза superficial alignment заключается в том, что знания и способности модели почти полностью приобретаются на этапе предварительного обучения, в то время как alignment (например, дообучение на инструкциях) учит модели генерировать ответы в соответствии с предпочтительным для пользователя форматом. Исходя из гипотезы superficial alignment, исследователи утверждают, что большие языковые модели могут генерировать удовлетворительные для пользователя ответы, если их дообучить на небольшом наборе инструкций. Поэтому исследователи построили наборы данных для обучения, проверки и тестирования инструкций, чтобы проверить эту гипотезу.
Оценки проводятся на построенном тестовом наборе данных. Для человеческой оценки LIMA превосходит InstructGPT и Alpaca на 17% и 19% соответственно. Кроме того, LIMA достигает результатов, сопоставимых с BARD, Claude и GPT-4. Для автоматической оценки, проводимой путем запроса у GPT-4 оценить ответы (чем выше оценка, тем лучше), LIMA превосходит InstructGPT и Alpaca на 20% и 36% соответственно, достигая результатов, сопоставимых с BARD, но уступая Claude и GPT-4. Экспериментальные результаты в целом по мнению исследователей подтвердили предложенную гипотезу поверхностного выравнивания.
OPT-IML (175B)
(Iyer et al., 2022) — это большая языковая модель, обученная исследователями посредством дообучения модели OPT (175B) (Zhang et al., 2022a) на специально созданном наборе данных Instruction Meta-Learning (IML). Этот набор данных включает более 1500 задач в области обработки естественного языка (NLP), собранных из восьми публично доступных наборов данных, таких как PromptSource (Bach et al., 2022), FLAN (Longpre et al., 2023) и Super-Natural Instructions (Wang et al., 2022e). После дообучения OPT-IML превзошла OPT по всем используемым критериям.
Dolly 2.0 (12B)
(Conover et al., 2023a) была создана исследователями, начав с предобученной языковой модели Pythia (12B) (Biderman et al., 2023) и дообучив её на наборе инструкций databricks-dolly-15k, который содержит 7 категорий задач NLP, включая классификацию текста и извлечение информации. После дообучения Dolly 2.0 (12B) значительно превзошла Pythia (12B) на бенчмарке EleutherAI LLM Evaluation Harness (Gao et al., 2021) и достигла результатов, сопоставимых с GPT-NEOX (20B) (Black et al., 2022), которая содержит вдвое больше параметров.
Falcon-Instruct (40B)
(Almazrouei et al., 2023a) — большая языковая модель, дообученная исследователями на основе Falcon (40B) (Almazrouei et al., 2023b) на англоязычном диалоговом наборе данных, содержащем 150 миллионов токенов из Baize (Xu et al., 2023c) и дополненных 5% данных из RefinedWeb (Penedo et al., 2023). Для оптимизации использования памяти исследователи применили технологии flash attention (Dao et al., 2022) и multi-query. Falcon-Instruct (40B) показала лучшие результаты на Open LLM Leaderboard (Beeching et al., 2023) по сравнению с базовой моделью Falcon (40B) и превзошла Guanaco (65B), которая имеет больше параметров.
Guanaco (7B)
(JosephusCheung, 2021) представляет собой языковую модель для длинных диалогов, разработанную путём дообучения LLaMA (7B) (Touvron et al., 2023a) на многоязычном диалоговом наборе данных. Этот набор данных включает 52 тысячи пар инструкций на английском языке из Alpaca (Taori et al., 2023a) и более 534 тысяч много-шаговых диалогов на различных языках, таких как упрощённый китайский, традиционный китайский, японский и немецкий. После дообучения Guanaco способна генерировать ответы, адаптированные к ролям, и непрерывно поддерживать тему в много-шаговых диалогах.
Minotaur (15B)
Эта модель была создана исследователями путём дообучения Starcoder Plus (15B) (Li et al., 2023f) на открытых наборах данных инструкций, включая WizardLM (Xu et al., 2023a) и GPTeacher-General-Instruct. Minotaur поддерживает максимальную длину контекста до 18 тысяч токенов.
Nous-Herme (13B)
Эта языковая модель создана путём дообучения LLaMA (13B) (Touvron et al., 2023a) на наборе инструкций, содержащем более 300 тысяч примеров, взятых из GPTeacher, CodeAlpaca (Chaudhary, 2023), GPT-4-LLM (Peng et al., 2023), Unnatural Instructions (Honovich et al., 2022) и Camel-AI (Li et al., 2023c). По результатам оценки Nous-Herme (13B) показала результаты, сопоставимые с GPT-3.5-turbo, в задачах ARC challenge (Clark et al., 2018) и BoolQ (Clark et al., 2019).
TÜLU (6.7B)
(Wang et al., 2023c) — это модель, дообученная исследователями на основе OPT (6.7B) (Zhang et al., 2022a) с использованием смешанного набора инструкций, включающего FLAN V2 (Longpre et al., 2023), CoT (Wei et al., 2022), Dolly (Conover et al., 2023a) и другие. TÜLU (6.7B) достигает на бенчмарках в среднем 83% качества ChatGPT и 68% от качества GPT-4.
YuLan-Chat (13B)
(YuLan-Chat-Team, 2023) была создана исследователями путём дообучения LLaMA (13B) (Touvron et al., 2023a) на двуязычном наборе данных, содержащем 250 тысяч пар инструкций на китайском и английском языках. YuLan-Chat-13B показала сопоставимые результаты с ChatGLM (6B) (Du et al., 2022) и превзошла Vicuna (13B) (Chiang et al., 2023) на наборе BBH3K, являющемся частью BBH (Srivastava et al., 2022).
MOSS (16B)
Это билингвальная диалоговая языковая модель, разработанная исследователями для ведения многошаговых диалогов. После дообучения MOSS превзошла базовую модель, демонстрируя лучшее соответствие предпочтениям пользователей.
Airoboros (13B)
Эта модель была создана исследователями путём дообучения LLAMA (13B) (Touvron et al., 2023a) на наборе данных Self-instruct (Wang et al., 2022c). Airoboros показала значительное улучшение результатов на всех бенчмарках по сравнению с LLAMA (13B) и достигла высокой сопоставимости с моделями, специально дообученными для определённых задач.
UltraLM (13B)
(Ding et al., 2023a) была создана путём дообучения LLAMA (13B) (Touvron et al., 2023a). UltraLM (13B) продемонстрировала более высокую производительность, чем Dolly (12B), с долей побед до 98%, и превзошла Vicuna (Chiang et al., 2023) и WizardLM (Xu et al., 2023a) с долями побед в 9% и 28% соответственно.
По итогу мы видим что инструктивность улучшает базовые модели. Все приведенные инструктивные модели превосходят свои базовые версии.
Т.е. инструктивный тюнинг не портит модели. Если сделан корректно, то он их улучшает.
И как известно из других статей, инструктивный тюнинг на широком круге инструкций улучшает способности базовой модели. Те инструктивная LLM модель общего домена - является более сильной базовой моделью для конкретных прикладных задач.
Domain-specific Instruction Finetuning - инструктивный тюнинг для конкретных доменов
Information Extraction
https://arxiv.org/abs/2304.08085
Были реализованы разными исследователями подходы к обучению инструктивных моделей в конкретных доменах. Например InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction Xiao Wang, Weikang Zhou, Can Zu, Han Xia, Tianze Chen, Yuansen Zhang, Rui Zheng, Junjie Ye, Qi Zhang, Tao Gui, Jihua Kang, Jingsheng Yang, Siyuan Li, Chunsai Du
В исследовании предлагается InstructUIE — единая структура для извлечения информации, основанная на обучении LLM FlanT5 11B с использованием инструкций. Она позволяет унифицированно моделировать различные задачи извлечения информации и учитывать зависимость между задачами. Для проверки метода был представлен IE INSTRUCTIONS — набор из 32 разнообразных датасетов для извлечения информации в едином текстовом формате с инструкциями, составленными экспертами. Исследователи показали, что предложенный метод демонстрирует результаты, сопоставимые с Bert в условиях с обучением, и значительно превосходит передовые модели, а также gpt-3.5, в условиях без обучения.
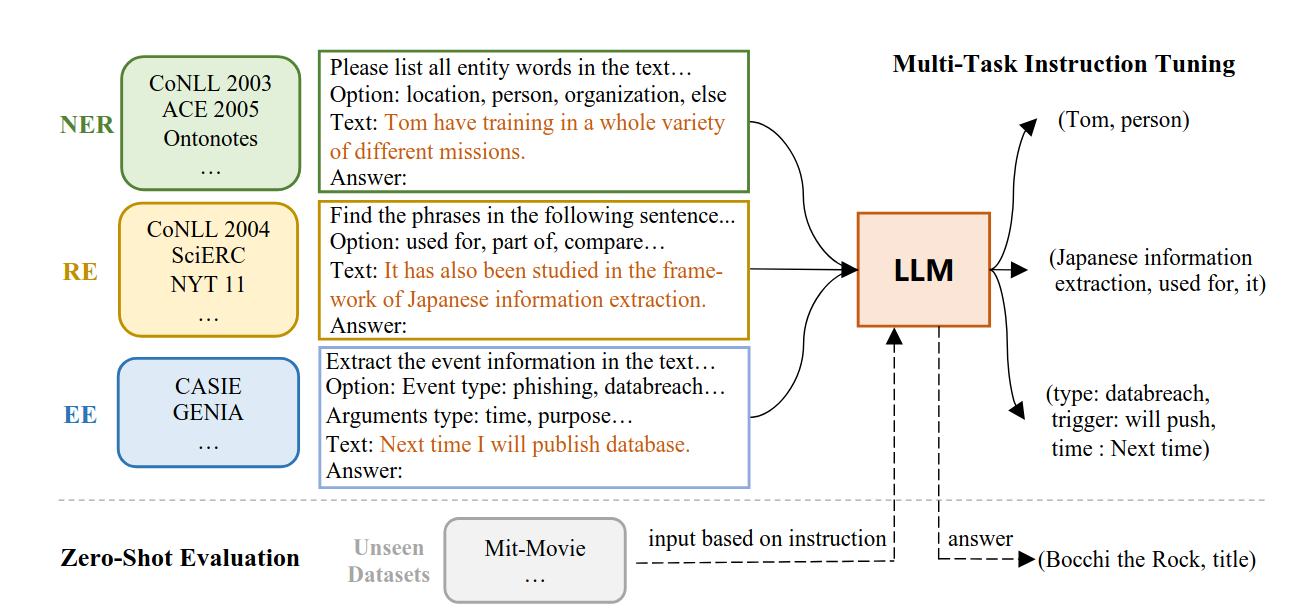
Рис. 5. фреймворк InstructUIE. Входные данные состоят из инструкций по задачам, опций и текста. Выходные данные — это более понятное предложение, преобразованное из исходных структур меток
Чтобы лучше передавать и использовать знания, полученные в предварительно обученных языковых моделях, исследователи реформулировали задачи извлечения информации (IE - Information Etraction) в форму seq2seq и решили их с помощью тонкой настройки крупных языковых моделей (LLMs), как показано на Рисунке 5. Каждая задача формируется с использованием четырех компонентов: инструкции к задаче, опций, текста и результата.
Инструкция к задаче предоставляет подробное руководство по извлечению необходимой информации из входного текста и созданию нужной структуры вывода. В ней описывается тип извлекаемой информации, формат результата и любые дополнительные правила или ограничения, которые необходимо соблюдать во время извлечения. Инструкция служит связующим звеном между сырым входным текстом и структурированным выводом, позволяя модели понимать задачу и генерировать точный и содержательный результат.
Cписок инструкций для каждой задачи.
Исследователи разработали инструкции для различных задач извлечения информации, предлагая единые подсказки (prompts) и форматы вывода для каждой задачи. Эти инструкции помогают моделям понимать задачу и формировать результаты в структурированном виде.
Опции представляют собой ограничения на выходные метки для задачи и определяют возможные результаты, которые модель может сгенерировать для конкретного ввода. Эти ограничения уникальны для каждой задачи и определяют соответствие предсказанных результатов семантическим концептам. Например, в задачах извлечения именованных сущностей (NER) опции могут включать метки, такие как "person", "organization", "location" или "miscellaneous". В задачах извлечения отношений (RE - relation extraction) опции могут представлять типы отношений, например, "works for", "born in", "married to" и так далее. Для извлечения событий (EE - events extraction) опции могут обозначать теги событий, такие как "начало", "завершение", "происшествие", "прекращение" и так далее. Опции обеспечивают структурированное пространство вывода для модели, позволяя ей генерировать результаты, согласованные с семантической структурой задачи.
Текст — это входное предложение для конкретного экземпляра задачи. Оно передается в предварительно обученную языковую модель вместе с инструкцией и опциями, чтобы модель могла сгенерировать нужный результат для данной задачи.
Результат — это предложение, преобразованное из оригинальных тегов выборки. Например, для NER формат вывода будет "метка сущности: диапазон сущности". Для RE — "отношение: головная сущность, зависимая сущность". Для EE — "метка события: слово-триггер, метка аргумента: диапазон аргумента". В случаях, когда входные данные не содержат структурированной информации, соответствующей предложенным опциям, для соответствующего результата присваивается значение "None".
NER (Named Entity Recognition)
- Перечислить все слова-сущности в тексте, которые соответствуют указанной категории. Формат вывода: "type1: word1; type2: word2".
- Найти все слова-сущности, относящиеся к заданной категории, в тексте. Формат вывода: "type1: word1; type2: word2".
- Выписать все слова-сущности в тексте, которые принадлежат указанной категории. Формат вывода: "type1: word1; type2: word2".
RE (Relation Extraction)
- Для заданной фразы, описывающей связь между двумя словами, извлечь слова и лексическую связь между ними. Формат вывода: "relation1: word1, word2; relation2: word3, word4".
- Найти фразы в следующих предложениях, которые имеют указанное отношение. Формат вывода: "relation1: word1, word2; relation2: word3, word4".
- Для данного предложения извлечь субъект и объект, между которыми существует указанное отношение, согласно типам отношений. Формат вывода: "relation1: word1, word2; relation2: word3, word4".
EE (Event Extraction)
- Определить роль в тексте, которая участвовала в событии, исходя из типа события, и вернуть её в списке событий.
- Извлечь информацию о событиях в тексте и вернуть их в виде списка событий.
ES (Entity Span)
- Перечислить все слова-сущности в тексте, соответствующие указанной категории. Формат вывода: "word1, word2".
ET (Entity Type)
- Для заданных опций указать категории всех перечисленных слов-сущностей. Формат вывода: "type1: word1; type2: word2".
EP (Entity Pair)
- Перечислить все пары сущностей, содержащие определённое отношение, согласно заданным опциям. Формат вывода: "word1, word2; word3, word4".
EPR (Entity Pair Relation)
- Для заданных опций указать отношения всех перечисленных пар сущностей. Формат вывода: "relation1: word1, word2; relation2: word3, word4".
EEA (Event Argument Extraction)
- Для заданного типа события и триггера указать аргументы из всех предложенных опций. Формат вывода: "name: role".
EET (Event Type and Trigger)
- Определить тип события и его триггерное слово из предложенных опций. Формат вывода: "event type: trigger".
Эти инструкции направлены на стандартизацию и унификацию подходов к различным задачам извлечения информации, что упрощает применение моделей к широкому спектру данных.
ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge
https://arxiv.org/abs/2303.14070
Применение LLM моделей без адаптации к медицинской сфере приводит к низкой точности диагностики и некорректным рекомендациям по лечению и препаратам. Чтобы решить эту проблему, исследователи собрали данные о более чем 700 заболеваниях, их симптомах, рекомендуемых лекарствах и необходимых медицинских тестах. На основе этих данных было создано 5 000 диалогов между врачами и пациентами, что позволило провести тюнинг моделей для медицинских целей.
Созданная модель, получившая название ChatDoctor, продемонстрировала значительный потенциал в понимании потребностей пациентов, предоставлении информированных рекомендаций и помощи в решении различных задач, связанных с медициной.
Ключевым шагом в работе стало создание процесса для инструктивного тюнинга LLMs в медицинской области. Этот процесс включает сбор данных, их предобработку, выбор модели, настройку гиперпараметров, выбор метрик для оценки и развертывание модели. Следуя этому процессу, исследователи могут адаптировать существующие диалоговые модели или разрабатывать новые для применения в медицине.
Результаты работы ChatDoctor показали, что модель превосходит общие LLMs, такие как ChatGPT, по точности диагностики в реальных клинических сценариях. Это подтверждает её эффективность в помощи при первичной диагностике и сопровождении пациентов.
Модель обучалась на основе LLAMA 7B на корпусе порядка 100 тыс диалогов.
Поэтому инструктивный тюнинг возможен на разные задачи, в том числе в конкретных доменах. Рабочий размер моделей 7-15 миллиардов параметров.