Medprompt - Могут ли универсальные базовые модели превзойти специализированные только за счет промптинга? На примере медицины
Краткий ответ:
- да могут
- few-shot на основе векторной близости входящего вопроса и примеров с ответами из базы
- примеры во few-shot с цепочками рассуждений
- синтетичексие сгенерированные цепочки рассуждений работают хорошо, не хуже чем написанные людьми
- самосогласованность через перетасовку контекта работает хорошо
- получилось на GPT4 с промртингом перебить специально обученную Med-PaLM 2 и выбить на MMLU-style медицинских бенчмарках 80-90% точности
На основе https://arxiv.org/abs/2311.16452
В статье исследователи изучили способности универсальных моделей, таких как GPT-4, быть применимыми в различных узких задачах и областях - например в медицине. Существует мнение, что такие модели уступают специализированным моделям, прошедшим дополнительное обучение на данных конкретного домена, например дообученным на медицинских данных. Например, в медицинской области большинство работ с опирались на модели, натренированные на специализированных данных, такие как BioGPT и Med-PaLM.
В своей работе исследователи продолжили изучение возможностей GPT-4 на медицинских тестах, не прибегая к специальному дообучению на медицинских данных. Вместо того чтобы просто демонстрировать способности модели «из коробки», они провели систематическое исследование методов оптимизации запросов к LLM (prompt engineering). Было установлено, что усовершенствование подходов к созданию запросов может раскрыть более глубокие специализированные способности модели, которые она приобрела на этапе предобучения на общем корпусе знаний. В результате GPT-4 превзошел лучшие результаты, ранее достигнутые на медицинских тестах.
Исследователи представили метод Medprompt, который сочетает несколько стратегий оптимизации запросов. Эта методика позволяет GPT-4 демонстрировать лучшие результаты на всех девяти наборах данных из комплекса MultiMedQA. Методика Medprompt превзошла такие специализированные модели, как Med-PaLM 2, с использованием значительно меньшего числа вызовов модели. Например, на наборе данных MedQA использование Medprompt позволило снизить уровень ошибок на 27% по сравнению с предыдущими лучшими методами и впервые превысить порог точности в 90%.
Помимо медицинских задач, исследователи продемонстрировали универсальность подхода Medprompt. Они показали, что методика успешно применяется в других областях, таких как электротехника, машинное обучение, философия, бухгалтерия, юриспруденция, сестринское дело и клиническая психология. Эти результаты подтверждают широкую применимость предложенной стратегии.
После выхода GPT-4 в марте 2023 года авторы продемонстрировали, что эта модель обладает значительными биомедицинскими способностями «из коробки». Используя базовую стратегию создания запросов, исследователи показали сильные результаты.
В контексте языковых моделей термин «prompting» обозначает входные данные, которые задают направление для генерации ответа моделью. Эмпирические исследования показывают, что производительность foundation models в конкретной задаче сильно зависит от качества запроса и может изменяться порой неожиданным образом. Например, исследование продемонстрировало, что производительность модели на наборе данных GSM8K может варьироваться более чем на 10% без изменения параметров модели. «Prompt engineering» — это процесс разработки эффективных формулировок запросов, которые позволяют моделям лучше справляться с поставленными задачами. Ниже представлены ключевые подходы, лежащие в основе методики Medprompt.
In-Context Learning (ICL) (обучение в контексте) — важная способность foundation models, позволяющая решать новые задачи на основе нескольких примеров, представленных в запросе. Например, ICL-запрос может включать демонстрацию нескольких примеров вопросов и желаемых ответов перед целевым вопросом. ICL не требует обновления параметров модели, но может демонстрировать эффекты, схожие с дообучением. Выбор примеров для few-shot prompting существенно влияет на производительность модели. В исследовании производительности GPT-4 на медицинских задачах была применена базовая ICL-методика, включая one-shot и five-shot prompting, чтобы продемонстрировать простоту применения модели.
Chain of Thought (CoT) (цепочка размышлений) — это метод создания запросов, который включает промежуточные шаги рассуждений перед представлением ответа. Разбивая сложные задачи на последовательность более мелких шагов, CoT позволяет моделям формировать более точные ответы. В работе Med-PaLM врачи создавали CoT-запросы, адаптированные для сложных медицинских задач. В рамках рассматриваемого исследования изучена возможность автоматической генерации CoT-запросов с помощью самой GPT-4. Для этого использовались пары [вопрос, правильный ответ] из обучающего набора данных. Было установлено, что GPT-4 способна самостоятельно генерировать качественные CoT-цепочки рассуждений даже для наиболее сложных медицинских задач.
Ensembling (ансамблирование) — это метод, позволяющий объединять результаты нескольких запусков модели для получения более надежного и точного ответа. Этот метод использует технику self-consistency, где генерируется несколько вариантов ответа, которые затем объединяются для достижения консенсуса. Разнообразие результатов можно контролировать с помощью параметра температуры: высокие значения вводят больше случайности в процесс генерации. Ансамблирование также помогает справляться с чувствительностью моделей к порядку примеров в запросе, например, изменяя последовательность примеров в few-shot prompting можно получать разные результаты.
Несмотря на повышение производительности, ансамблирование увеличивает вычислительные затраты. Например, метод Ensemble Refinement в Med-PaLM 2 использовал до 44 отдельных запусков модели для одного вопроса. Чтобы сократить такие затраты, исследователи выбрали более простые методы, минимизируя количество вызовов модели. В статье также представлено исследование влияния увеличенной вычислительной нагрузки на производительность.
Наборы данных
Авторы использовали девять биомедицинских наборов данных с множественным выбором из набора MultiMedQA [29]. Основные характеристики наборов данных:
MedQA [14]
Этот набор включает вопросы с множественным выбором, составленные по образцу экзаменов для получения медицинской лицензии в США, Китае и на Тайване. Для обеспечения справедливости сравнений с предыдущими исследованиями [29, 30, 23], авторы сосредоточились на подмножестве данных из США, где вопросы соответствуют стилю экзамена USMLE (United States Medical Licensing Exam). В наборе содержится 1273 вопроса, каждый из которых имеет четыре варианта ответа.
MedMCQA [25]
Набор включает исторические и учебные вопросы, соответствующие форматам двух вступительных экзаменов в медицинские вузы Индии — AIIMS и NEET-PG. Для анализа использовался поднабор «dev», содержащий 4183 вопроса с четырьмя вариантами ответов, что согласуется с предыдущими исследованиями.
PubMedQA [15]
Этот набор данных требует ответа «да», «нет» или «возможно» на биомедицинские вопросы на основе контекста, взятого из аннотаций PubMed. Существуют два режима тестирования: reasoning-required и reasoning-free. В режиме reasoning-free предоставляются расширенные ответы с объяснениями из аннотаций, однако в данном исследовании результаты были получены для режима reasoning-required, где модель должна использовать только аннотации для формирования ответа. Всего в наборе 500 вопросов.
MMLU [11]
Многозадачный набор данных, включающий 57 различных поднаборов, охватывающих области STEM, гуманитарных и социальных наук. В рамках работы использовалась медицинская часть этого набора, включающая следующие категории: клинические знания, медицинская генетика, анатомия, профессиональная медицина, биология и медицина на уровне колледжа.
В разделе 5.3 показано, что методология Medprompt может быть применена для решения задач за пределами стандартных медицинских тестов. Для проверки этой гипотезы были проведены тесты на двух наборах данных с вопросами для экзамена NCLEX (National Council Licensure Examination) и шести дополнительных поднаборах MMLU, охватывающих такие темы, как бухгалтерский учёт и право. Подробности об этих наборах данных приводятся в соответствующем разделе.
В исследованиях было установлено, что, хотя использование prompting и методов in-context learning не изменяет параметры модели, выбор конкретной стратегии prompting можно рассматривать как высокоуровневую настройку или гиперпараметр всего процесса тестирования. Это требует осторожности, чтобы избежать переобучения, которое могло бы снизить обобщающую способность модели за пределами рассматриваемых тренировочных и тестовых наборов данных. Проблема переобучения при оценке производительности фундаментальных моделей аналогична той, что наблюдается в традиционном машинном обучении при оптимизации гиперпараметров [8]. Исследователи стремились избежать подобного переобучения в процессе разработки prompting-методов.
Интуитивно понятно, что использование в prompt, например, таблицы с конкретными вопросами из тестов, естественно, будет давать значительно лучшие результаты на этих вопросах, чем на новых, ранее не встречавшихся задачах. В традиционном машинном обучении для решения этой проблемы часто применяют разделение данных на тренировочные и тестовые наборы, где тестовые данные оцениваются только на финальном этапе выбора модели. Исследователи применили этот важный элемент методологии к своим экспериментам, выделив случайным образом 20% каждого набора данных как отдельную часть, названную «eyes-off». Эти данные полностью исключались из рассмотрения до заключительного этапа тестирования.
Данные из «eyes-off» не использовались и не оптимизировались во время разработки prompting-методов. Для упрощения процесса та же методология была применена ко всем наборам данных в MultiMedQA, поскольку многие из них изначально не содержали заранее определённых тренировочных и тестовых разделов. В разделе 5.1 представлено сравнительное исследование производительности Medprompt на разделах «eyes-on» и «eyes-off» из MultiMedQA. Было обнаружено, что производительность на обеих выборках сопоставима, причём GPT-4 с использованием Medprompt показал даже немного лучшие результаты на скрытых данных «eyes-off». Это свидетельствует о том, что методика может хорошо обобщаться на аналогичные вопросы в «открытом мире». В предыдущих исследованиях аналогичного подхода с «eyes-off» не обнаружено.
Подход к промптингу
В данном разделе описывается использование трех ключевых методов в Medprompt: динамический выбор примеров для few-shot, самоорганизованное рассуждение (chain of thought) и перестановка ответов в ensembling. После обсуждения каждого метода приводится подход к их интеграции в Medprompt.
Динамический выбор примеров для few-shot
Few-shot learning [3] является одним из самых эффективных методов in-context learning. Подход с prompting позволяет фундаментальным моделям быстро адаптироваться к специфическим доменам и следовать формату задачи всего за несколько демонстрационных примеров. Для упрощения и повышения эффективности в prompting обычно используются фиксированные примеры few-shot, которые не меняются для разных тестовых примеров. Это требует, чтобы выбранные few-shot примеры были максимально универсальными и релевантными для широкой выборки текстовых примеров.
Одним из способов достижения этого является ручная подготовка примеров экспертами в области, как это описано в [29]. Однако даже такой подход не может гарантировать, что подобранные примеры будут оптимально представлять каждый тестовый пример. В качестве альтернативы, если доступен тренировочный набор данных задачи, он может служить экономичным и качественным источником для выбора few-shot примеров. При достаточно большом тренировочном наборе можно выбирать разные примеры для разных входных тестовых данных. Такой подход был назван динамическим выбором few-shot примеров. Этот метод использует механизм, позволяющий идентифицировать примеры на основе их схожести с текущей задачей [18].
В рамках Medprompt исследователи применили следующий подход для идентификации репрезентативных few-shot примеров: для каждого тестового примера выбираются k тренировочных примеров, которые семантически наиболее схожи, используя метод k-NN кластеризации в эмбеддинговом пространстве.
Для этого сначала использовались векторные представления тренировочных и тестовых вопросов, сгенерированные с помощью text-embedding-ada-002. Затем, для каждого тестового вопроса x, извлекались ближайшие k соседей (x1, x2, ..., xk) из тренировочного набора, основываясь на расстоянии в эмбеддинговом пространстве text-embedding-ada-002. Соседи упорядочивались в соответствии с заранее заданной метрикой сходства d (например, косинусным расстоянием) таким образом, что d(xi, x) ≤ d(xj, x) при i < j.
В сравнении с fine-tuning, динамический выбор few-shot примеров использует тренировочные данные, но не требует миллиарда обновлений параметров модели.
Self-Generated Chain of Thought - синтетические цепочки рассуждений

Рис. 1. Сравнение примеров цепочки мыслей (CoT), созданных экспертами и сгенерированных GPT-4. Используя пару (вопрос, правильный ответ) из обучающего набора, GPT-4 способен генерировать подробное объяснение, подходящее для использования в демонстрациях CoT для few-shot примеров.
Метод Chain-of-thought (CoT) [34] предполагает использование текстовых инструкций, таких как «Давайте подумаем пошагово», чтобы явно побудить модель генерировать последовательность промежуточных шагов рассуждения. Данный подход показал значительное улучшение способности фундаментальных моделей справляться со сложными задачами, требующими многозвенной логики.
Большинство методов, связанных с chain-of-thought, основаны на привлечении экспертов, которые вручную составляют примеры few-shot с цепочками рассуждений для prompting [30]. Однако вместо того, чтобы полагаться на экспертов, исследователи разработали механизм для автоматического создания примеров chain-of-thought. Было установлено, что достаточно просто запросить у GPT-4 создание chain-of-thought для тренировочных примеров, используя следующий шаблон запроса:

Рис. 2. Шаблон промпта, используемый для к генерации цепочек рассуждений - генерация синтетических примеров CoT
Основной проблемой данного подхода в генерации рассуждений моделью является то, что сгенерированные моделью цепочки рассуждений (Chain-of-Thought, CoT) содержат неявный риск появления ложных или некорректных логических выводов. Исследователи снижают этот риск, привлекая GPT-4 для генерации как рассуждений, так и оценки наиболее вероятного ответа, который вытекает из этой цепочки. Если этот ответ не совпадает с правильной меткой (ground truth), образец полностью отбрасывается, так как предполагается, что рассуждения не заслуживают доверия. Хотя ложные или некорректные рассуждения иногда могут привести к правильному ответу (т.е. ложные срабатывания), исследователи обнаружили, что простой этап проверки совпадения финального вывода с целевым эффективно фильтрует ложные отрицательные результаты.
Исследователи отмечают, что по сравнению с примерами CoT, использованными в Med-PaLM 2 [30], которые были вручную созданы клиническими экспертами, рассуждения, сгенерированные GPT-4, являются более длинными и предлагают более детализированную пошаговую логику. Параллельно с этим исследованием другие недавние работы [35, 7] также приходят к выводу, что фундаментальные модели создают более качественные цепочки рассуждений (prompts), чем эксперты.
Choice Shuffling Ensemble - перемешивание порядка ответов и самосогласованность при прохождении теста (оценка на бенчмарках)
Хотя это менее выражено, чем у других foundation models, GPT-4 может демонстрировать склонность отдавать предпочтение определённым вариантам ответов в задачах с множественным выбором (независимо от содержания вариантов), т.е. проявлять position bias [1, 16, 40]. Чтобы уменьшить этот эффект, исследователи предлагают перемешивать варианты ответов и делать повтрные генерации, и затем проверять согласованность результатов для разных порядков сортировки. В результате они используют технику choice shuffle и self-consistency prompting.
Self-consistency [32] заменяет наивное однопутевое или жадное декодирование на разнообразный набор цепочек рассуждений при многократном запросе модели с параметром temperature > 0, что вводит элемент случайности в генерации. В рамках choice shuffling перед генерацией каждой цепочки рассуждений исследователи перемешивают порядок вариантов ответа. Затем выбирается наиболее согласованный ответ, т.е. тот, который наименее чувствителен к перемешиванию вариантов - те получался в большинстве генераций.
Choice shuffling имеет дополнительное преимущество: оно увеличивает разнообразие цепочек рассуждений сверх того, что даёт выборка по температуре, что в конечном итоге улучшает качество итогового ансамбля [5]. Исследователи также применяют эту технику при генерации промежуточных шагов CoT для обучающих примеров. Для каждого примера варианты ответа перемешиваются несколько раз, и для каждого варианта генерируется цепочка рассуждений. Они сохраняют только те примеры для few-shot, в которых модель выдаёт правильный ответ.
Собираем все вместе: Medprompt
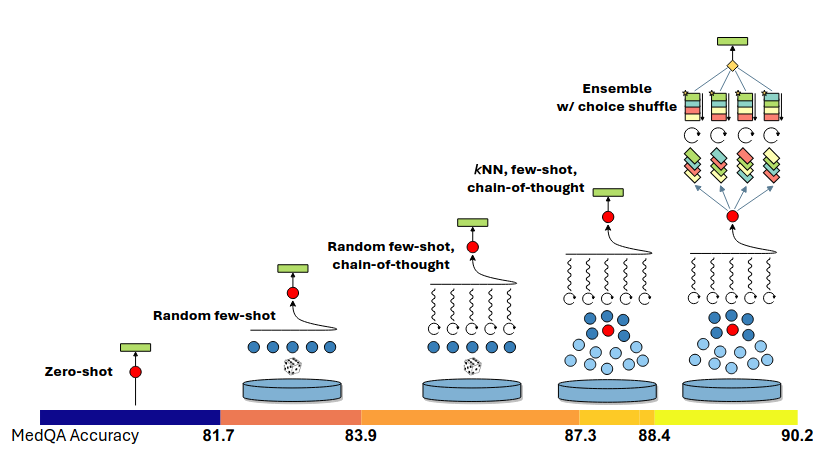
Рис. 3. Визуальная иллюстрация компонентов Medprompt и аддитивного вклада в производительность на тесте MedQA. Стратегия промптинга используетвыбор примеров few-shot на основе kNN, подсказки цепочки мыслей CoT, сгенерированные GPT-4, и перетасованный ансамбль с выбором ответа
Medprompt объединяет умный выбор примеров для few-shot генерации, само-генерируемые шаги рассуждений (chain of thought) и ансамбль на основе большинства голосов, как описано выше. Сочетание этих методов образует универсальную стратегию prompt-engineering. Визуальное представление эффективности стратегии Medprompt на бенчмарке MedQA, с поэтапным добавлением каждого компонента, показано на Рисунке 3. Алгоритмическое описание приведено на рис. 4.
Medprompt состоит из двух этапов:
-
предварительной обработки
-
и шага предсказания, на котором формируется финальный ответ для тестового примера.
-
Во время этапа предварительной обработки каждый вопрос из обучающего набора данных пропускается через облегчённую модель эмбеддинга для генерации векторного представления (строка 4 в Algorithm 1). Исследователи использовали OpenAI’s text-embedding-ada-002 для создания эмбеддинга.
-
Для каждого вопроса GPT-4 используется для генерации chain of thought и предсказания финального ответа (строка 5).
-
Если сгенерированный ответ совпадает с правильной меткой (ground truth), исследователи сохраняют соответствующий вопрос, его векторное представление, цепочку рассуждений и финальный ответ.
-
В противном случае вопрос полностью исключается из пула выборки, поскольку предполагается, что логика рассуждений ненадёжна, если модель в итоге приходит к неверному ответу (строки 6-7).
-
Во время этапа предсказания, получив тестовый вопрос, исследователи повторно создают его эмбеддинг, используя ту же модель эмбеддинга, что и на этапе предварительной обработки, и применяют kNN для поиска схожих примеров из предварительно обработанного пула (строки 12-13). Найденные примеры и соответствующие цепочки рассуждений, сгенерированные GPT-4, структурируются как контекст для генерации ответа на тестовый вопрос с помощью GPT-4 (строка 14).
-
Тестовый вопрос и соответствующие варианты ответов добавляются в конец контекста, формируя финальный prompt (строка 17).
-
Модель, следуя предоставленным примерам few-shot, генерирует цепочку рассуждений (chain of thought) и предполагаемый ответ.
-
Затем исследователи выполняют процесс ансамблирования, повторяя описанные выше шаги несколько раз для повышения надёжности результата. Для увеличения разнообразия ответов перемешивается порядок вариантов ответа в тестовом вопросе (строки 15-16), как подробно описано выше.
-
Чтобы определить финальный предсказанный ответ для теста, выбирается наиболее часто встречающийся ответ (строка 20).

Рис.4. Алгоритмическое описание Medprompt
Результаты Medprompt, представленные исследователями, настроены с использованием 5 примеров few-shot, отобранных с помощью kNN, и 5 параллельных API-вызовов в рамках процедуры choice-shuffle ensemble, что, по их мнению, позволяет достичь разумного баланса между минимизацией затрат на предсказание и максимизацией точности.
Анализы абляции показывают, что дальнейшие улучшения можно получить за счёт увеличения значений этих гиперпараметров. Например, при увеличении количества few-shot примеров до 20 и элементов ансамбля до 11 производительность на MedQA повышается ещё на +0,4%, достигая нового рекордного уровня в 90,6%.
Исследователи отмечают, что, хотя Medprompt демонстрирует рекордные результаты на медицинских тестовых наборах, этот алгоритм является универсальным и не ограничивается медицинской областью или задачами с множественным выбором.
Они считают, что общая парадигма, сочетающая умный выбор примеров few-shot по векторной близости вопроса и вопросов в few-shot примерах, синтетически-сгенерированные шаги рассуждений (chain of thought) в обучающих примерах и ансамблирование по принципу большинства голосов, может быть широко применено и к другим областям, не только к медицине.
Результаты
Качество различных базовых моделей на тестах множественного выбора MultiMedIA [29] представлена на рис. 5. GPT-4 с Medprompt превосходит все другие модели на каждом тесте.
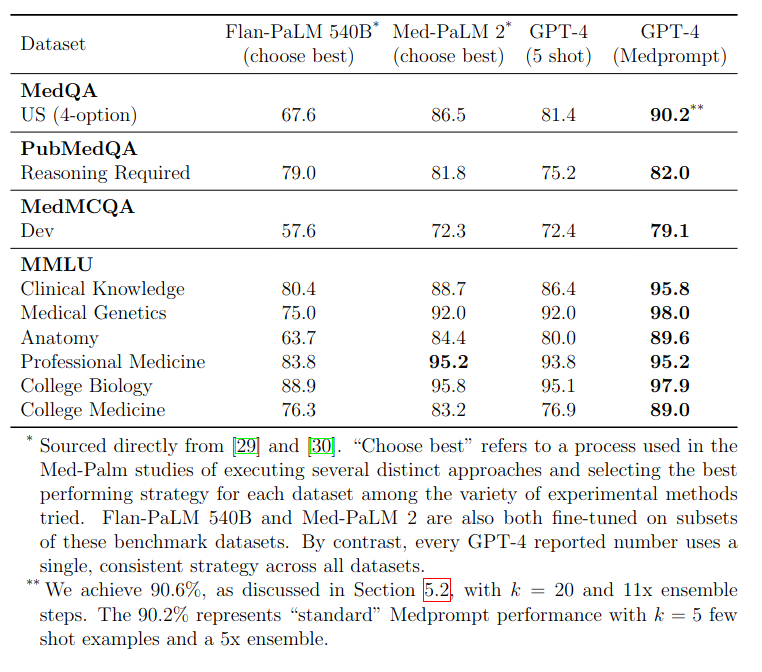
Рис.5. Результаты различных базовых моделей на тестах множественного выбора MultiMedIA
Помимо серии постепенных улучшений в абляционных исследованиях, исследователи сравнивают цепочку рассуждений (chain-of-thought, CoT), созданную экспертами для Med-PaLM 2 [30], с CoT, автоматически сгенерированной GPT-4. Оценка GPT-4 проводится с использованием обоих CoT-промптов, при фиксированных 5 примерах few-shot и без ансамблирования.
Самостоятельно сгенерированный CoT от GPT-4 превзошёл экспертный CoT на 3,1 процентных пункта. Исследователи отмечают, что по сравнению с CoT, созданным экспертами для Med-PaLM 2, цепочки рассуждений, сгенерированные GPT-4, являются более длинными и предлагают более детализированную пошаговую логику.
Одним из возможных объяснений этого является то, что CoT, сгенерированный GPT-4, может быть лучше адаптирован к сильным и слабым сторонам самой модели, что приводит к повышению производительности по сравнению с экспертной версией. Другое объяснение заключается в том, что CoT, созданный экспертами, может содержать скрытые предвзятости или предположения, которые не применимы ко всем вопросам в MedQA, тогда как CoT, сгенерированный GPT-4, может быть более развернутым и лучше обобщаться для различных вопросов.
Обобщение: исследование Medprompt в различных доменах
Исследователи утверждают, что сочетание техник prompt engineering, использованных в Medprompt — включая динамический выбор примеров few-shot, само-генерируемые рассуждения (chain of thought) и choice shuffle ensembling — имеет универсальное применение. Эти методы не были специально разработаны для датасетов из набора MultiMedQA.
Для проверки этого утверждения исследователи протестировали финальную методологию Medprompt на шести дополнительных и разнообразных датасетах из набора MMLU benchmark suite, охватывающих задачи по следующим предметам: электротехника, машинное обучение, философия, профессиональный бухгалтерский учёт, юриспруденция и профессиональная психология.
Кроме того, исследователи использовали ещё два дополнительных датасета с вопросами в стиле экзамена NCLEX (National Council Licensure Examination) — экзамена, необходимого для получения лицензии медсестры в США.
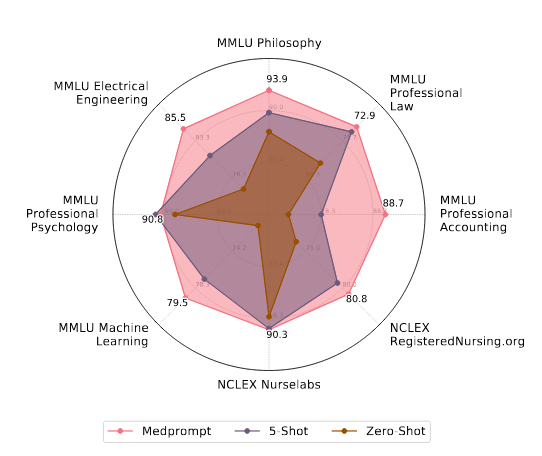
Рис.6. Производительность GPT-4 с тремя различными стратегиями подсказок для наборов данных вне домена. Подходы с нулем и пятью примерами в промпте представляют собой базовые уровни и отражают методологию, использованную в [23].
На Рисунке 6 представлена производительность GPT-4 на этих разнообразных внешних датасетах с использованием Medprompt в сравнении с zero-shot и five-shot промптами (с случайным выбором примеров). Во всех этих датасетах Medprompt обеспечивает среднее улучшение на +7,3% по сравнению с zero-shot бейзлайном. Для сравнения, на датасетах MultiMedQA, изученных в данной работе, Medprompt дал улучшение на +7,1% относительно того же zero-shot бейзлайна.
Исследователи подчёркивают, что схожий прирост точности на датасетах с разным распределением демонстрирует универсальность подхода Medprompt. Хотя это выходит за рамки данной работы, исследователи считают, что общий базовый принцип Medprompt — сочетание few-shot learning и chain-of-thought reasoning, обёрнутых в слой ансамблирования — может быть расширен для применения за пределами задач с вопросами и множественным выбором, с минимальными алгоритмическими модификациями.
Например, в задаче генерации открытого текста слой ансамблирования может не полагаться на прямое голосование по большинству, а вместо этого выбирать ответ, который наиболее близок к остальным ответам в пространстве эмбеддингов. Другим вариантом может быть объединение всех K сгенерированных текстовых фрагментов в структурированном формате и запрос модели на выбор наиболее вероятного варианта, по аналогии с Ensemble Refinement [30]. Исследователи оставляют на будущее дальнейшее изучение возможных алгоритмических модификаций для применения в других задачах.
Ограничения и риски
Поскольку foundation models обучаются на огромных датасетах интернет-масштаба, высокая производительность на тестах может быть связана с эффектами запоминания или утечки данных, когда модель ранее могла сталкиваться с тестовыми примерами во время обучения. В предыдущем исследовании, оценивавшем производительность GPT-4 на тех же датасетах с базовыми промптами [23], был использован алгоритм MELD для blackbox-тестирования, который не обнаружил доказательств запоминания. Однако такие методы не могут гарантировать отсутствие утечки данных.
Кроме того, исследователи отдельно протестировали GPT-4 на вопросах USMLE, находящихся за платным доступом и недоступных в открытом интернете, где модель также показала высокие результаты [23]. В текущем исследовании использовались стандартные практики машинного обучения для контроля переобучения и утечки данных на этапе prompt engineering. Однако вопросы потенциального загрязнения тестовых данных во время обучения остаются актуальными.
Исследователи также подчёркивают, что высокая производительность GPT-4 с использованием Medprompt не свидетельствует о его реальной эффективности в задачах здравоохранения в открытом мире [23]. Хотя возможность превращения foundation models в ведущих специалистов по тестовым задачам выглядит многообещающей, они с осторожностью воспринимают выводы о применимости этих методов в реальных условиях медицины — будь то автоматизация административных задач, поддержка клинических решений или взаимодействие с пациентами.
Важно отметить, что медицинские тесты, которые исследователи и другие используют для оценки, предназначены для проверки человеческих компетенций в определённых областях. Обычно такие тесты представлены в виде вопросов с множественным выбором. Несмотря на их распространённость и охват широкого спектра тем, они не отражают весь диапазон и сложность медицинских задач, с которыми сталкиваются профессионалы в реальной практике. Поэтому использование таких тестов в качестве прокси для реальных компетенций ограничивает возможность переноса высоких результатов на специализированных тестах в реальную практику. Хотя исследователи считают, что стратегия Medprompt может быть адаптирована для задач без вариантов выбора ответа, в данном исследовании эти адаптации не тестировались.
Исследователи напоминают, что foundation models могут генерировать ошибочную информацию (так называемые «галлюцинации»), что может скомпрометировать полученные ответы. Улучшение стратегий промптинга может уменьшить количество галлюцинаций и повысить общую точность, но оставшиеся ошибки могут стать ещё сложнее для обнаружения. Перспективным направлением является калибровка вероятностных оценок, что позволит предоставлять пользователям надёжные результаты. В предыдущем исследовании было установлено, что GPT-4 демонстрирует хорошую калибровку и может давать надёжные оценки своей уверенности на тестах с вопросами с множественным выбором [23].
Список ссылок на другие работы
- [1] Niels J. Blunch. Position bias in multiple-choice questions. Journal of Marketing Research, 21(2):216–220, 1984.
- [2] Elliot Bolton, David Hall, Michihiro Yasunaga, Tony Lee, Chris Manning, and Percy Liang. Biomedlm, 2022. Stanford Center for Research on Foundation Models.
- [3] Tom B., Ilya Sutskever, Dario Amodei, et all - Language models are few-shot learners, 2020.
- [4] S´ebastien Bubeck, Varun Chandrasekaran, - Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- [5] Rich Caruana, Alexandru Niculescu-Mizil, Geoff Crew, and Alex Ksikes. Ensemble selection from libraries of models. In Proceedings of the twenty-first international conference on Machine learning, page 18, 2004.
- [6] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin - Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [7] Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rockt¨aschel. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023.
- [8] Matthias Feurer and Frank Hutter. Hyperparameter optimization. Automated machine learning: Methods, systems, challenges, pages 3–33, 2019.
- [9] Zelalem Gero, Chandan Singh, Hao Cheng, Tristan Naumann, Michel Galley, Jianfeng Gao, and Hoifung Poon. Self-verification improves few-shot clinical information extraction. In ICML 3rd Workshop on Interpretable Machine Learning in Healthcare (IMLH), 2023.
- [10] Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Nau- mann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomed- ical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23, 2021.
- [11] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- [12] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- [13] Ayanna M. Howard, Cha Zhang, and Eric Horvitz. Addressing bias in machine learning algo- rithms: A pilot study on emotion recognition for intelligent systems. 2017 IEEE Workshop on Advanced Robotics and its Social Impacts (ARSO), pages 1–7, 2017.
- [14] Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421, 2021. 19
- [15] Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. arXiv preprint arXiv:1909.06146, 2019.
- [16] Miyoung Ko, Jinhyuk Lee, Hyunjae Kim, Gangwoo Kim, and Jaewoo Kang. Look at the first sentence: Position bias in question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1109–1121, Online, November 2020. Association for Computational Linguistics.
- [17] Tiffany H Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepa˜no, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, et al. Per- formance of chatgpt on usmle: Potential for ai-assisted medical education using large language models. PLoS digital health, 2(2):e0000198, 2023.
- [18] Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. - What makes good in-context examples for gpt-3?, 2021.
- [19] Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu. - Biogpt: generative pre-trained transformer for biomedical text generation and mining. Briefings in Bioinformatics, 23(6):bbac409, 2022.
- [20] Michael Madaio, Lisa Egede, Hariharan Subramonyam, Jennifer Wortman Vaughan, and Hanna - Assessing the fairness of ai systems: AI practitioners’ processes, challenges, and needs for support. In 25th ACM Conference on Computer-Supported Cooperative Work and Social Computing (CSCW 2022), February 2022.
- [21] John McCarthy, Marvin L Minsky, Nathaniel Rochester, and Claude E Shannon. A proposal for the Dartmouth summer research project on artificial intelligence, August 31, 1955. AI magazine, 27(4):12–12, 2006.
- [22] Allen Newell, John C Shaw, and Herbert A Simon. Report on a general problem solving program. In IFIP congress, volume 256, page 64. Pittsburgh, PA, 1959.
- [23] Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of GPT-4 on medical challenge problems. arXiv preprint arXiv:2303.13375, 2023. [24] OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- [25] Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on Health, Inference, and Learning, pages 248–260. PMLR, 2022.
- [26] Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483, 2023.
- [27] Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage?, 2023.
- [28] Lloyd S Shapley et al. A value for n-person games. 1953.
- [29] Karan Singhal - Large language models encode clinical knowledge. arXiv preprint arXiv:2212.13138, 2022.
- [30] Karan Singhal, Tao Tu, - Towards expert-level medical question answering with large language models, 2023.
- [31] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27, 2014.
- [32] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023.
- [33] Jason Wei, Yi Tay, - Emergent abilities of large language models. Transactions on Machine Learning Research, 2022. Survey Certification.
- [34] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023.
- [35] Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. arXiv preprint arXiv:2309.03409, 2023.
- [36] Michihiro Yasunaga, Antoine Bosselut, Hongyu Ren, Xikun Zhang, Christopher D. Manning, Percy Liang, and Jure Leskovec. Deep bidirectional language-knowledge graph pretraining. In Neural Information Processing Systems (NeurIPS), 2022.
- [37] Michihiro Yasunaga, Jure Leskovec, and Percy Liang. Linkbert: Pretraining language models with document links. In Association for Computational Linguistics (ACL), 2022.
- [38] Travis Zack, - Coding inequity: Assessing gpt-4’s potential for perpetuating racial and gender biases in healthcare. medRxiv, 2023.
- [39] Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors, 2023.
- [40] Lianmin Zheng, - Judging llm-as-a-judge with mt-bench and chatbot arena, 2023