Основы Mixture-of-Experts (MoE)
Модели Mixture of Experts (MoE) — это класс трансформерных моделей. В отличие от традиционных плотных моделей, MoE использует "разреженный" подход, при котором для каждого входа (токена) используется только подмножество компонентов модели ("экспертов"). Это позволяет более эффективно проводить предобучение и ускоряет инференс, эффективно управляя при этом большим размером модели. Mixture of Experts (MoE) является продвинутой архитектурой машинного обучения, которая делит части модели на несколько специализированных подсетей.
Концепция MoE была представлена в статье 1991 года "Адаптивная смесь локальных экспертов", в которой предлагалось делить задачи между меньшими, специализированными сетями для сокращения времени обучения и вычислительных требований. Со временем MoE значительно эволюционировала, и сегодня она используется в некоторых из крупнейших моделей глубокого обучения, включая те, которые имеют триллионы параметров. Например, Google Switch Transformers с 1.6 триллиона параметров и другие передовые модели, такие как Mixtral от Mistral, используют MoE для увеличения емкости и эффективности модели. Архитектура MoE предлагает способ сбалансировать высокую емкость больших моделей с практической необходимостью вычислительной эффективности, обеспечивая более быстрое и масштабируемое выполнение моделей.
В MoE каждый эксперт представляет собой нейронную сеть, обычно это прямой нейронный сеть (FFN), а сеть шлюзов или маршрутизатор определяет, какие токены отправляются к какому эксперту (или другими словами - какие эксперты применяются к каждому из токенов). Эксперты специализируются на различных аспектах входных данных, что позволяет модели более эффективно обрабатывать более широкий спектр задач.
Аналогией для понимания MoE может служить больница с различными специализированными отделениями (экспертами). Каждый пациент (входной токен) направляется в соответствующее отделение приемной (маршрутизатором) на основе их симптомов (характеристик данных). Так же, как не все отделения участвуют в лечении каждого пациента, не все эксперты в MoE используются для каждого токена.
Для сравнения, в стандартной архитектуре языковой модели (плотной модели) каждая часть модели используется для каждого токена, подобно тому, как врач общей практики пытается лечить все аспекты потребностей каждого пациента.
Таким образом, MoE предлагает более эффективный и потенциально более быстрый подход к обучению модели и инференсу, используя специализированное подмножество модели для каждого токена, но они имеют свои собственные наборы проблем, особенно в плане требований к памяти и на этапе файн-тюнинга.
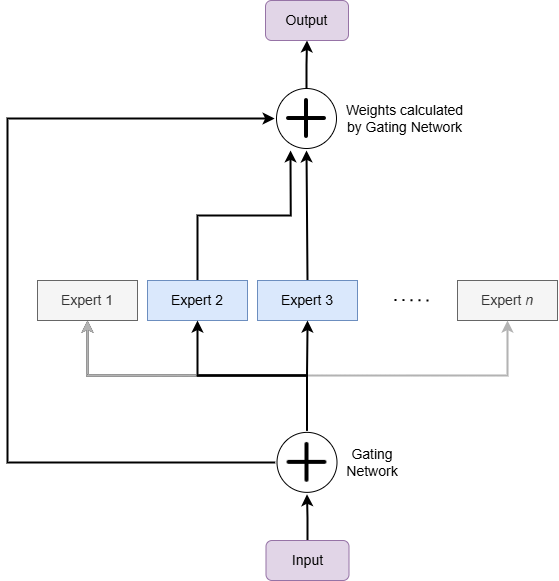
Рис.1 Mixture of Experts (MoE) - общая концепция
MoE в LLM
В больших языковых моделях (LLM), которые используют архитектуру Mixture of Experts (MoE), слои MoE обычно применяются в качестве замены или дополнения к стандартным слоям трансформера, таким как слои полносвязной сети (feed-forward layers). Давайте рассмотрим, как именно MoE интегрируется в архитектуру LLM:
- Слои Feed-Forward в Трансформере:
- В стандартной архитектуре трансформера каждый слой состоит из механизма внимания (self-attention) и полносвязного слоя (feed-forward network). В MoE-архитектуре именно эти полносвязные слои заменяются или дополняются слоями MoE.
- В MoE-версии, вместо одного большого полносвязного слоя, используется несколько "экспертов" — небольших полносвязных сетей. Для каждого входного токена выбирается подмножество экспертов, которые обрабатывают этот токен.
Пример архитектуры слоя трансформера с MoE:
Input
│
├── Self-Attention Layer
│
├── MoE Layer
│ ├── Gate (вычисляет веса для экспертов)
│ ├── Expert 1 (полносвязная сеть)
│ ├── Expert 2 (полносвязная сеть)
│ └── ...
│
├── Normalization Layer
│
└── OutputЧто означает термин "Эксперт"?
В контексте моделей Mixture of Experts (MoE) термин "эксперт" обычно относится к компоненту модели, который специализируется на определенном типе задачи или шаблоне в данных, а не на конкретной теме, такой как финансы, бизнес или ИТ. Эти эксперты больше связаны с обработкой различных видов вычислительных шаблонов или задач (таких как генерация кода, рассуждение, суммирование), чем с фокусировкой на знаниях, специфичных для домена. Но в целом эксперты не обязаны быть интерпретируемыми.
Каждый эксперт в модели MoE по сути является меньшей нейронной сетью, обученной быть особенно эффективной при определенных видах операций или шаблонов в данных. Модель учится направлять различные части входных данных к наиболее релевантному эксперту. Например, один эксперт может быть более эффективен в обработке числовых данных, в то время как другой может специализироваться на задачах обработки естественного языка.
Специализация экспертов в основном определяется данными, на которых они обучаются, и структурой самой модели. Речь идет больше о природе вычислительной задачи (например, распознавание определенных шаблонов, работа с определенными типами входных данных), чем о знаниях, специфичных для домена.
Однако теоретически возможно разработать модели MoE, где различные эксперты обучаются на различных доменах знаний (например, на конкретных темах), но это больше вопрос выбора дизайна и подхода к обучению, чем врожденная особенность архитектуры MoE. На практике модели MoE, как правило, используются больше для их вычислительной эффективности и гибкости в обработке различных задач в рамках крупномасштабной модели.
Сами эксперты могут различаться по сложности, от простых однослойных сетей до сложных многослойных архитектур, в зависимости от требуемой специализации. В некоторых реализациях MoE каждый эксперт может использовать разные типы моделей.
Сеть шлюзов
Сеть шлюзов выступает в роли динамического принимающего решения в MoE, направляя входные данные к наиболее релевантным экспертам на основе характеристик входа. Для каждого элемента данных сеть шлюзов назначает вероятность или "вес" каждому эксперту, определяя, кто должен обработать вход. Для оптимизации производительности сеть шлюзов обычно использует алгоритмы маршрутизации, такие как top-k маршрутизация, которая выбирает топ-k экспертов для каждого входа, или маршрутизация выбора экспертов, где эксперты указывают, какие данные они лучше всего могут обработать. Выбирая, какие эксперты активировать, сеть шлюзов обеспечивает эффективную обработку, максимизируя производительность модели при минимизации вычислительной нагрузки.
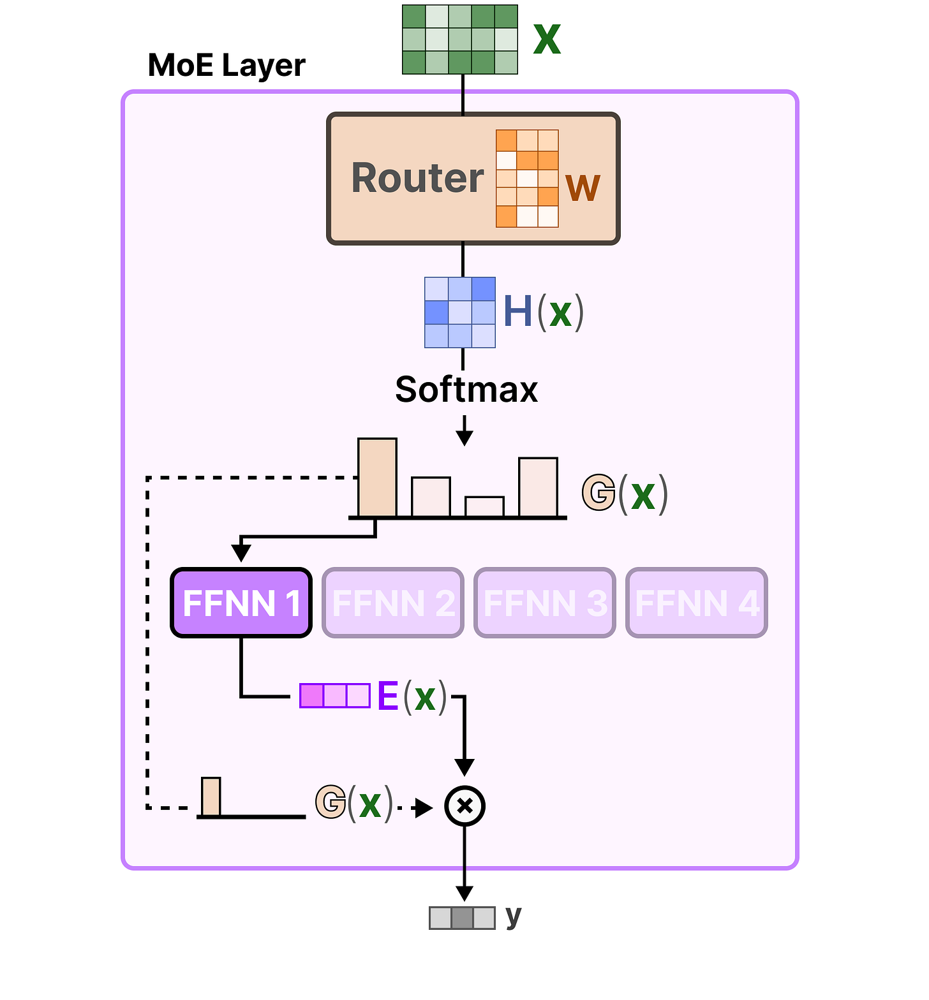
Рис.2 Упрощенный вид слоя Mixture-of-Experts
Входные данные X подаются в Router (сеть с пропусканием с весами W), который вычисляет скрытый вектор H(x), а затем распределение SoftMax G(x) по экспертам (столбиковая диаграмма представляет вероятности для четырех экспертов). Маршрутизатор выбирает лучших экспертов на основе G(x) — на этой иллюстрации Эксперт 1 (фиолетовый) является основным активированным экспертом (гиперпараметр модели - выбирать top_k=1 экспертов на каждом шаге).
Этот эксперт (сеть прямой связи, FFNN 1) обрабатывает входные данные для получения выходных данных E(x). Окончательный выход y слоя MoE представляет собой взвешенную сумму выходных данных экспертов (здесь, по сути, просто выходные данные Эксперта 1, умноженные на его вес). На практике часто для добавления емкости используются два эксперта на токен, и их выходные данные будут взвещиваться и суммироваться. Другие эксперты (серые) не участвуют в инференсе при этих входных данных, что делает вычисления разреженными и эффективными.
Mixtral 8x7B
Mixtral 8x7B, представленный в статье "Mixtral of Experts", является разреженной моделью Sparse Mixture of Experts (SMoE) языковой модели с отличительными особенностями:
- Она имеет ту же архитектуру, что и Mistral 7B, но каждый слой состоит из 8 блоков прямого распространения (экспертов).
- Для каждого токена на каждом слое сеть маршрутизатора выбирает двух экспертов для обработки текущего состояния и комбинирования их выходов.
- Выбранные эксперты могут варьироваться на каждом шаге генерации, позволяя каждому токену иметь доступ к 47B параметрам, но активно используя только 13B параметров во время вывода.
Общая логика процесса инференса:
- Получение входного токена: Представьте поток входных токенов, поступающих в модель. Каждый токен может представлять часть текста, кода или других типов данных.
- Решение о маршрутизации: Каждый токен оценивается сетью маршрутизатора. Маршрутизатор решает, какие два из восьми доступных экспертов (блоков прямого распространения) должны обработать этот конкретный токен. Это решение основывается на характеристиках токена и специализированных функциях экспертов.
- Обработка экспертами: Выбранные эксперты независимо обрабатывают токен. Каждый эксперт применяет свои собственные слои нейронной сети, которые специализированы для определенных типов данных или задач. Например, один эксперт может быть лучше в обработке естественного языка, в то время как другой может быть более эффективен с числовыми данными.
- Комбинирование выходов: После обработки выходы от двух выбранных экспертов комбинируются. Это может включать усреднение выходов, их конкатенацию или использование какого-либо другого метода для слияния информации, полученной каждым экспертом.
- Продолжение через слои: Этот процесс повторяется для каждого слоя модели. На каждом слое сеть маршрутизатора выбирает свою пару экспертов на основе текущего состояния токена.
- Генерация окончательного вывода: После того, как токен прошел через все слои, генерируется распределение вероятностей следующего токена, как в обычной LLM.
Разреженная активация: Важно отметить, что в любой момент времени используется только часть от общего числа параметров (экспертов). Это делает модель "разреженной" и эффективной, особенно во время инференса. Разреженные слои позволяют модели MoE содержать множество экспертов без одновременной активации всех.
В реальном инференсе этот процесс также параллелится на GPU, что еще больше ускоряет работу модели в режиме генерации.
Сложности с MoE сосредоточены в основном на этапе обучения. Заставить это работать хорошо — не тривиальная задача: маршрутизатор должен научиться отправлять правильные входы правильным экспертам. Если он отправляет все одному эксперту, этот эксперт становится узким местом (а другие эксперты недозагружены). Если он разбрасывает входы случайным образом, эксперты не специализируются.
Техники, такие как load-balancing losses, шум в маршрутизации (например, Noisy Top-k gating) или адаптивная маршрутизация (adaptive routing), используются для обеспечения обучения и использования всех экспертов. Мы не будем слишком глубоко вдаваться в эти детали здесь, но хорошо знать, что много исследований посвящено эффективному обучению моделей MoE и предотвращению коллапса экспертов.
Пример реализации Mixture of Experts (MoE) на pytorch
Вот пример простой реализации MoE для задачи классификации текста, когда на выход [CLS] токена Роберты накидывается несколько экспертов в виде простоно линейного слоя. И гейтинг в виде тоже простого линейного слоя с софтмаксом.
Здесь у нас не используется в forward отбор экспертов по top_k, они вычисляются и применяются все. И так проще оставить для обучения. Но никто не мешает на этапе инференса этот отбор по top_k сделать, добавив всего 2 строчки кода. Также чтобы обучение было больше похоже на условия инференса, можно добавить нормировку логитов гейта на температуру (например сделать температуру 0.5 или даже 0.1), чтобы в реальности скоры большинства экспертов стремились к нулю.
# Define the Mixture of Experts model
class MoEClassifier(nn.Module):
def __init__(self, base_model_name="distilroberta-base", num_labels=2, num_experts=3):
super(MoEClassifier, self).__init__()
# Base transformer model (without classification head)
self.base_model = AutoModel.from_pretrained(base_model_name)
self.hidden_size = self.base_model.config.hidden_size
self.num_labels = num_labels
self.num_experts = num_experts
# Expert heads (each a simple linear classifier)
self.experts = nn.ModuleList([nn.Linear(self.hidden_size, self.num_labels) for _ in range(num_experts)])
# Gating network that produces weights for each expert
self.gate = nn.Linear(self.hidden_size, self.num_experts)
def forward(self, input_ids, attention_mask, labels=None):
# Transformer forward pass
outputs = self.base_model(input_ids=input_ids, attention_mask=attention_mask)
# Use [CLS] token representation (first token) as pooled output
last_hidden_state = outputs.last_hidden_state # (batch_size, seq_len, hidden_size)
pooled_output = last_hidden_state[:, 0, :] # (batch_size, hidden_size)
# Compute gating weights (softmax over experts)
gating_logits = self.gate(pooled_output) # (batch_size, num_experts)
gating_weights = torch.softmax(gating_logits, dim=1) # (batch_size, num_experts)
# Compute each expert's logits
expert_logits = torch.stack([expert(pooled_output) for expert in self.experts], dim=1) # (batch_size, num_experts, num_labels)
# Combine experts' outputs weighted by gating probabilities
weighted_logits = expert_logits * gating_weights.unsqueeze(2) # (batch_size, num_experts, num_labels)
final_logits = weighted_logits.sum(dim=1) # (batch_size, num_labels)
loss = None
if labels is not None:
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(final_logits, labels)
# Return a dict similar to HuggingFace model outputs
return {"loss": loss, "logits": final_logits} if loss is not None else {"logits": final_logits}Пример реализации Sparse Mixture of Experts
Тут уже используются
-
Noisy Top-K Gating
Каждый входной вектор проходит через gate, который даёт оценки для всех экспертов. Чтобы избежать "мертвых" экспертов (те, которые никогда не активируются), добавляется шум к логитам. Выбираются top-k экспертов по значению логитов. Их выходы суммируются с весами, полученными через softmax.
-
Sparse Forward Pass
Только активные эксперты вычисляются, остальные игнорируются → экономия ресурсов. Это ключевое отличие от soft MoE, где все эксперты всегда активны.
-
Load Balancing Loss
Вводится дополнительная компонента в Loss - load_loss, чтобы стимулировать равномерное использование всех экспертов. Это помогает избежать ситуации, когда только 1–2 эксперта получают большую часть нагрузки.
import torch
import torch.nn as nn
import torch.nn.functional as F
class NoisyTopKGate(nn.Module):
def __init__(self, model_dim, num_experts, top_k, noise=True):
super(NoisyTopKGate, self).__init__()
self.num_experts = num_experts
self.top_k = top_k
self.noise = noise
# Gate network — вычисляет logits для каждого эксперта
self.gate = nn.Linear(model_dim, num_experts)
# Noise parameters
self.noise_linear = nn.Linear(model_dim, num_experts)
def forward(self, hidden):
# hidden: [batch_size, model_dim]
# Compute gate logits
logits = self.gate(hidden) # [batch_size, num_experts]
if self.noise:
# Add noise to logits
raw_noise_stddev = self.noise_linear(hidden)
noise_stddev = F.softplus(raw_noise_stddev) + 1e-9
noisy_logits = logits + torch.randn_like(logits) * noise_stddev
else:
noisy_logits = logits
# Apply softmax and select top-k experts
top_k_logits, top_k_indices = noisy_logits.topk(self.top_k, dim=1) # [B, k], [B, k]
top_k_gates = F.softmax(top_k_logits, dim=1) # [B, k]
zeros = torch.zeros_like(logits, requires_grad=False) # [B, E]
gates = zeros.scatter(1, top_k_indices, top_k_gates) # [B, E]
return gates, top_k_indices, top_k_gates
class SparseMoE(nn.Module):
def __init__(self, model_dim, num_experts, top_k, num_labels):
super(SparseMoE, self).__init__()
self.num_experts = num_experts
self.top_k = top_k
# Gating network
self.gate = NoisyTopKGate(model_dim, num_experts, top_k)
# Expert networks
self.experts = nn.ModuleList([
nn.Linear(model_dim, num_labels) for _ in range(num_experts)
])
# Load balancing loss coefficient
self.load_balance_coeff = 0.01
def forward(self, hidden, labels=None):
batch_size, model_dim = hidden.shape
# Get gating weights
gates, top_k_indices, top_k_gates = self.gate(hidden)
# Initialize output
final_output = torch.zeros((batch_size, model_dim), device=hidden.device)
# For each expert, compute output only if it's active
for i, expert in enumerate(self.experts):
# Find which examples use this expert
mask = (top_k_indices == i).any(dim=1)
if mask.any():
expert_input = hidden[mask]
expert_output = expert(expert_input)
# Accumulate with appropriate gates
final_output[mask] += expert_output * gates[mask][:, i].unsqueeze(-1)
# Compute load balancing loss
# Mean over batch of how many times each expert is used
density = gates.mean(dim=0) # [E]
density_proxy = gates.detach().mean(dim=0)
load_loss = -self.load_balance_coeff * density_proxy * torch.log(density + 1e-9)
load_loss = load_loss.sum()
# Final classification layer
logits = final_output.mean(dim=1, keepdim=True) # Simplified
# Loss
loss = None
if labels is not None:
ce_loss = F.cross_entropy(logits, labels)
loss = ce_loss + load_loss
return {
"logits": logits,
"loss": loss,
"load_loss": load_loss.item(),
"gate_weights": gates,
"top_k_indices": top_k_indices
}Хороших и крепких вам Микстур!