Законы масштабирования больших языковых моделей - эмпирические законы оптимальности и вычислительного бюджета
В машинном обучении закон масштабирования нейронных сетей — это эмпирический (выявленный опытным путем) закон масштабирования, который описывает, как изменяется производительность нейронной сети при изменении ключевых факторов, таких как количество параметров, размер обучающей выборки и затраты на обучение.
В общем случае, модель глубокого обучения можно охарактеризовать четырьмя параметрами: размером модели, размером обучающей выборки, затратами на обучение и ошибкой после обучения (например, ошибкой на тестовом наборе). Каждый из этих параметров можно выразить как действительное число, обычно обозначаемое как \(N, D, C, L\) (соответственно: количество параметров модели, размер выборки, вычислительные затраты и потери - loss на тестовой выборке.
В целом гсоподствует простое правило - собрал побольше модель, показал ей побольше хороших чистых разнообразных данных - получил умнее, сильнее и лучше модель.
Но насколько больше надо собирать модель? Насколько больше можно давать данных? Сколько раз на этих данных можно повторно учить модель?
Для больших моделей такой сбор, фильтрация данных, обучение стоят миллионы долларов. И уметь планировать обучение очень нужно.
И чаще всего его планируют исходя из вычислительного бюджета. Формулировка задачи для бизнеса чаще всего стоит так:
- у нас есть Х1 видеокарт размера Х2. Мы можем обучать модель на них в течение Х3 времени. Какую модель по размеру нам запустить и сколько данных ей показать, чтобы за этот вычислительный бюджет получить макисмальный результат?
- для лидеров рынка типа OpenAI и xAI - это может быть что-то типа 100 000 видеокарт Nvidia H100 80Gb, 6 месяцев вычислений - что лучше сделать?
- например для крупной мировой лаборатории или топовых Российских компаний это может быть что-то типа 1000 видеокарт Nvidia A100 80 Gb, 3 месяца вычислений - что лучше сделать?
- для маленькой университетской лаборатории и средней технологической компании - этот бюджет будет порядка 10 карат Nvidia V100 на 1 месяц...
- про энтузиастов и любителей с парой домашних видеокарт я совсем молчу.
Если что, первый вариант с 100 тыс H100 на 6 мес vs 1 тыс A100 3 мес - это примерно в 500 раз мощнее. Поэтому не удивляйтесь почему иностранные модели сильно мощнее отчечественных. Мы тут можем пока только догонять, копировать лучшие практики и пытаться повторить их в меньшем масштабе.
А про 10 карт V100 на 1 месяц - это в 1000 раз меньше чем 1000 А100, ну и соответственно в 500 000 раз меньше чем у лидеров ИИ индустрии. Поэтому все что могут небольшие лаборатории, средние компании, инди opensource коллективы - это делать небольшие адаптации опенсорсных моделей, выложенных игроками 1-го и 2-го эшелона.
И чтобы отвечать на поставленный бизнесом вопрос нужны какие-то знания в виде формул, а не гадания на кофейной гуще.
При претрейне моделей ориентируются на ошибку моделей на отложенной тестовой выборке данных - значение функции потерь \(L\). Т.к. на претрейне получается базовая модель, которая еще ничего не умеет - ни на вопросы отвечать, ни рассуждать, ни тексты по запросу генерировать, только продолжать предложения, то и используют loss функцию.
Степенные функции в предсказании производительности моделей
Эмпирические исследования демонстрируют, что значение функции потерь (loss) моделей на тестовых данных подчиняется степенным зависимостям от трёх ключевых факторов:
- количества параметров модели \(N\)
- объёма обучающих данных \(D\)
- вычислительного бюджета \(C\) - сколько раз модель увидит показанные данные
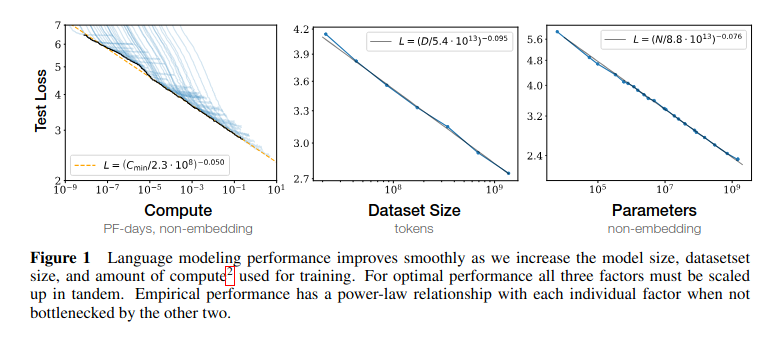
Рис.1 LLM Scaling Laws из работы OpenAI 2020 г.
Например, в работе OpenAI (2020) https://arxiv.org/pdf/2001.08361 установлено, что тестовый loss модели GPT-3 масштабируется как \(L(N) \sim N^{-0.076}\), а зависимость от данных — \(L(D) \sim D^{-0.095}\).
Исследование Google Research https://research.google/pubs/explaining-neural-scaling-laws/ вводит два режима масштабирования:
- Variance-limited — доминирует при малых данных, где увеличение \(D\) снижает дисперсию оценки.
В пределе бесконечного количества данных или произвольно широкой модели некоторые аспекты обучения нейросетей упрощаются. В частности, если зафиксировать один из параметров D или N и исследовать масштабирование относительно другого параметра при его неограниченном увеличении, то потери уменьшаются как \(1/x\), то есть по степенному закону с показателем 1.
По сути, этот режим, ограниченный дисперсией, удобен для анализа, поскольку предсказания модели можно разложить в ряд по \((1/N)\) или размеру набора данных \(D\). Для демонстрации таких масштабирований достаточно показать, что предел при бесконечном количестве данных или ширине существует и является гладким; это гарантирует возможность разложения в ряд по простым целым степеням.
- Resolution-limited — актуален для больших моделей, где производительность ограничена способностью сети "разрешать" тонкие паттерны в данных.
В этом режиме один из параметров D или N считается бесконечным, и исследуется масштабирование относительно второго параметра. В этом случае различные исследования эмпирически наблюдали степенное масштабирование \(1/x^{α}\), обычно с 0<α<1 как для \(x=N\), так и для \(x=D\).
Можно привести очень общий аргумент в пользу степенных законов масштабирования, если предположим, что обученные модели отображают данные на d-мерное многообразие данных. Основная идея заключается в том, что дополнительные данные (в пределе бесконечного размера модели) или добавленные параметры модели (в пределе бесконечных данных) используются моделью для разбиения многообразия данных на более мелкие компоненты. Модель затем делает независимые предсказания в каждом компоненте многообразия данных, чтобы оптимизировать потери при обучении.
Если исходные данные изменяются непрерывно на многообразии, то размер подрегионов, на которые мы можем разделить многообразие (а не количество регионов), определяет loss модели. Чтобы уменьшить размер подрегионов в два раза, требуется увеличить количество параметров или размер набора данных в 2d раз, и таким образом, обратная величина показателя масштабирования будет пропорциональна внутренней размерности d многообразия данных, так что \(α ∝ 1/d\). Визуализация этого последовательного улучшения аппроксимации с увеличением размера набора данных показана на Рисунке 2 для моделей, обученных предсказывать данные, сгенерированные случайной полносвязной сетью.
Эти режимы объясняют, почему масштабирование только одного параметра (например, \(N\)) приводит к насыщению производительности.
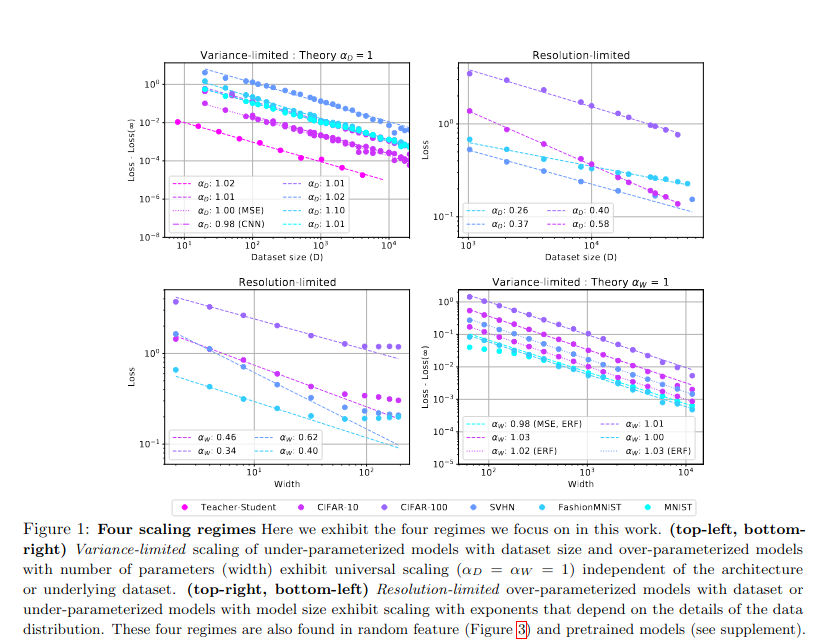
Рис.2 Google Research LLM Scaling Laws из работы 2021 г.
Про FLOPS - что это такое и как измеряют
Вычислительный бюджет определяют во FLOPS. И чтобы понять дальнейшую формулу, надо понимать чему равен FLOPS.
FLOPS (FLoating-point Operations Per Second) - это количество операций с плавающей точкой, выполняемых вычислительной системой за одну секунду. Это важный показатель производительности компьютеров, особенно в научных вычислениях и при работе с искусственным интеллектом.
FLOPS можно определить двумя способами:
-
Теоретически: Умножением количества микропроцессоров в системе, числа исполняемых устройств с плавающей точкой в каждом процессоре и частоты процессора.
-
Практически: Измерением с помощью специальных бенчмарков, которые выполняют определенное количество операций с плавающей точкой и замеряют время выполнения.
При работе с большими языковыми моделями (LLM) FLOPS используются для:
- Оценки вычислительной мощности: FLOPS помогают определить, сколько времени потребуется на обучение или инференс модели.
- Сравнения эффективности: Позволяет сравнивать производительность различных систем и архитектур при работе с LLM.
- Планирования ресурсов: Помогает оценить необходимые вычислительные мощности для обучения и развертывания моделей.
- Оптимизации: FLOPS используются для оценки эффективности различных методов оптимизации модели и выбора наиболее подходящих алгоритмов.
- Масштабирования: При увеличении размера модели или датасета FLOPS помогают прогнозировать необходимое увеличение вычислительных ресурсов.
Важно отметить, что для LLM часто используются операции с половинной (FP16) или смешанной точностью, что позволяет увеличить производительность при сохранении приемлемой точности вычислений, классический FLOPS замеряют для Float32 - 4битных чисел одинарной точности.
TFLOPS (Терафлопс) — это единица измерения вычислительной производительности и означает 1 триллион операций в секунду.
Вот сравнение для различных GPU NVIDIA в размерности TFLOPS:
- Серверные видеокарты:
NVIDIA H100 (SXM5)
- FP64: 33.5 TFLOPS
- FP32: 66.9 TFLOPS
- FP16: 133.8 TFLOPS
- FP8 Tensor Core: 1978.9 TFLOPS (3957.8 TFLOPS с использованием функции Sparsity)[1]
NVIDIA A100
- FP64: 9.7 TFLOPS (19.5 TFLOPS с Tensor Core)
- FP32: 19.5 TFLOPS
- FP16: 78 TFLOPS (312 TFLOPS с Tensor Core)
- INT8 Tensor Core: 624 TOPS (1248 TOPS с Sparsity)[5][8]
NVIDIA V100
- FP64: 7 TFLOPS
- FP32: 14 TFLOPS
- Бытовые видеокарты:
NVIDIA RTX 4090
- FP32: 82.58 TFLOPS
- FP16: 82.58 TFLOPS
NVIDIA RTX 3090
- FP32: 35.58 TFLOPS
- FP16: 35.58 TFLOPS
- FP64: 556 GFLOPS
NVIDIA RTX 3060
- FP32: 12 TFLOPS
- FP16: 12 TFLOPS
- FP64: 199 GFLOPS
Как видно поколения видеокарт отличаются по производительности друг от друга достаточно существенно. И в зависимости от доступного вам оборудования доступный вычислительный бюджет будет сильно различаться.
Chinchilla Scaling Laws - Закон оптимальности Шиншиллы: революция в оптимизации вычислений
Исследование DeepMind (2022) https://arxiv.org/abs/2203.15556 пересмотрело подходы к масштабированию, предложив вычислительно-оптимальное распределение ресурсов между \(N\) и \(D\). Для бюджета \(C = 6N_{opt}D_{opt}\), где оптимальные значения определяются как:
\[ N_{opt}(C) = G \left(\frac{C}{6}\right)^a, \quad D_{opt}(C) = G^{-1} \left(\frac{C}{6}\right)^b,\]
где эмпирические константы:
- \(a = \frac{\alpha}{\alpha + \beta}\)
- \(b = \frac{\beta}{\alpha + \beta}\)
- \(\alpha \approx 0.34\)
- \(\beta \approx 0.28\)
Ниже скрин из статьи с их основной формулой:

Рис.3 Цитата из статьи Chinchilla Scaling Laws 2022 г.
Для самой модели Шиншилла исследователями было выбрано соотношение \(D=20×N\) - она обучалась в конфигурации 70B (70 миллиардов) параметров и 1.4T (1.4 триллиона) токенов. Такое соотношение можно принять оптимальным для dense-моделей (плотных, у которых отрабатывают все матрицы весов в слоях, в отличие от MoE).
Практические последствия
- Переобучение существующих моделей: Например, модель Gopher (280B параметров) демонстрировала недостаточную производительность из-за недостатка данных. Согласно Chinchilla scaling, для её размера требовалось в 20 раз больше токенов в обучающей выборке.
- Экономия ресурсов: Модель Chinchilla (70B параметров), обученная на 1.4T токенов, превзошла Gopher (280B) при вдвое меньших заратах на вычисления при обучении модели.
- Претрейн обучение на одну эпоху - исследование DeepMind предполагает обучение на одну эпоху.
Все модели которые обучаются по закону масштабирования, примененному для обучения модели Шиншилла, называют Шиншилла-оптимальными.
Более формально конкретный закон масштабирования ("масштабирование Chinchilla") утверждает, что для большой языковой модели (LLM), обученной авторегрессивно в течение одной эпохи с косинусным графиком скорости обучения, выполняется:
\[ \begin{cases} C = C_0 N D \\ L = \frac{A}{N^{\alpha}} + \frac{B}{D^{\beta}} + L_0 \end{cases}\]
где переменные:
- \(C\) — затраты на обучение модели в FLOPS.
- \(N\) — количество параметров в модели.
- \(D\) — количество токенов в обучающем наборе.
- \(L\) — средний отрицательный логарифмический loss на токен (negative log-likelihood loss per token - nats/token), достигнутая обученной LLM на тестовом наборе.
- \(L_0\) представляет потери идеального генеративного процесса на тестовых данных.
- \(\frac{A}{N^{\alpha}}\) отражает, что трансформерная языковая модель с \(N\) параметрами уступает идеальному генеративному процессу.
- \(\frac{B}{D^{\beta}}\) отражает, что модель, обученная на \(D\) токенах, уступает идеальному генеративному процессу.
Статистические параметры:
- \(C_0 = 6\), что означает, что обучение одного параметра на одном токене стоит 6 FLOPs. Это оценивается Kaplan et al. Обратите внимание, что затраты на обучение намного выше, чем затраты на инференс, так как обучение включает как прямой, так и обратный проходы, тогда как инференс стоит 1-2 FLOPs на параметр для вывода на одном токене.
- \(\alpha = 0.34\), \(\beta = 0.28\), \(A = 406.4\), \(B = 410.7\), \(L_0 = 1.69\).
Статистические законы были подогнаны по экспериментальным данным с \(N \in [7 \times 10^7, 1.6 \times 10^{10}]\), \(D \in [5 \times 10^9, 5 \times 10^{11}]\), \(C \in [10^{18}, 10^{24}]\).
Так как есть 4 переменные, связанные 2 уравнениями, наложение 1 дополнительного ограничения и 1 дополнительной цели оптимизации позволяет решить все четыре переменные. В частности, для любого фиксированного \(C\) можно единственным образом решить все 4 переменные, минимизирующие \(L\). Это дает нам оптимальные \(D_{opt}(C)\), \(N_{opt}(C)\) для любого фиксированного \(C\):
\[ \begin{cases} N_{opt}(C) = G\left(\frac{C}{6}\right)^{a}, \\ \quad D_{opt}(C) = G^{-1}\left(\frac{C}{6}\right)^{b}, \\ \quad \text{где} \quad G = \left(\frac{\alpha A}{\beta B}\right)^{\frac{1}{\alpha + \beta}}, \\ \quad a = \frac{\beta}{\alpha + \beta}, \\ \quad b = \frac{\alpha}{\alpha + \beta}. \end{cases}\]
Подставляя числовые значения, получаем "эффективный" размер модели и размер обучающей выборки Chinchilla, а также достижимую тестовую потерю:
\[ \begin{cases} N_{opt}(C) = 0.6 C^{0.45} \\ D_{opt}(C) = 0.3 C^{0.55} \\ L_{opt}(C) = 1070 C^{-0.154} + 1.7 \end{cases}\]
Аналогично, можно найти оптимальный размер обучающей выборки и бюджет вычислений для любого фиксированного размера параметров модели и т.д.
Существуют и другие оценки для "эффективного" размера модели и размера обучающей выборки Chinchilla. Вышеуказанное основано на статистической модели \(L = \frac{A}{N^{\alpha}} + \frac{B}{D^{\beta}} + L_0\). Можно также непосредственно подогнать статистический закон для \(D_{opt}(C)\), \(N_{opt}(C)\) без обходных путей, для чего получаем:
\[ \begin{cases} N_{opt}(C) = 0.1 C^{0.5} \\ D_{opt}(C) = 1.7 C^{0.5} \end{cases}\]
или в табличной форме согласно https://en.wikipedia.org/wiki/Neural_scaling_law:
| \(N_{opt}(C)\) | C / FLOP | C / FLOPs of training Gopher | \(D_{opt}(C)\) |
|---|---|---|---|
| 400 million | 1.92e+19 | 1/29968 | 8.0 billion |
| 1 billion | 1.21e+20 | 1/5706 | 20.2 billion |
| 10 billion | 1.23e+22 | 1/2819 | 205.1 billion |
| 67 billion | 5.76e+23 | 1 | 1.5 trillion |
| 175 billion | 3.85e+24 | 6.7 | 3.7 trillion |
| 280 billion | 9.90e+24 | 17.2 | 5.9 trillion |
| 520 billion | 3.43e+25 | 59.5 | 11.0 trillion |
| 1 trillion | 1.27e+26 | 221.3 | 21.2 trillion |
| 10 trillion | 1.30e+28 | 22515.9 | 216.2 trillion |
LLaMA-2 (Meta)
- Архитектура: 7B–70B (7-70 миллиардов) параметров, обучение на 2T (2 триллиона) токенов.
- Соответствие scaling laws: LLaMA-2 следует рекомендациям Chinchilla, увеличивая \(D\) и \(N\) согласно закону Шиншиллы.
- Наиболее близка к Шиншилла-оптимальности модель в размере 70B при объеме данных 2T токенов, что подтверждается низкой перплексией на тестах.
LLaMA-3 (Meta)
Но уже Llama 3 https://ai.meta.com/blog/meta-llama-3/ значительно отклоняется от оптимальной точки, предсказанной законами масштабирования Chinchilla. Модель обучается на гораздо большем количестве данных, чем рекомендуется этими законами:
- Llama 3 была обучена на 15 триллионах токенов, что значительно превышает рекомендации Chinchilla для оптимального соотношения данных и параметров.
- Для варианта Llama 3 с 8 миллиардами параметров это соотношение составляет примерно 1875 токенов на параметр, что в 75 раз превышает оптимальную точку Chinchilla. Хотя оптимальное количество вычислительных ресурсов для обучения модели с 8 миллиардами параметров по Шиншилле составляет ~200 миллиардов токенов, было обнаружено, что качество модели продолжает улучшаться даже после того, как модель обучена на два порядка больших данных.
- Обе модели с 8 и 70 миллиардами параметров продолжали улучшаться лог-линейно после обучения на 15 триллионов токенов. Более крупные модели могут соответствовать производительности этих меньших моделей с меньшими вычислительными затратами на обучение, но меньшие модели обычно предпочтительнее, поскольку они намного эффективнее при использовании (в инференсе).
- Такой подход требует примерно в 10-15 раз больше вычислительных ресурсов для обучения, но позволяет достичь лучшей производительности при меньшем количестве параметров.
- Это отклонение от законов Chinchilla объясняется стремлением создать более эффективные модели для инференса, особенно для использования на устройствах с ограниченными ресурсами.
Таким образом, Llama 3 намеренно отходит от оптимальной точки Chinchilla, обучаясь на значительно большем объеме данных, чтобы достичь лучшей производительности при меньшем размере итоговых моделей.
QWEN2.5-Max (Alibaba)
- Особенности: MoE-архитектура, 20T (20 триллионов) токенов предобучения.
- Оптимальность: Использование гигантского \(D\) согласуется с Chinchilla, но особенность архитектуры MoE (Mixture of Experts) усложняет прямое сравнение.
- Эксперименты показывают, что для MoE оптимальное \(D\) на 15-20% выше, чем для dense-моделей типа Шиншилла и LLama2. https://arxiv.org/abs/2405.15052
DeepSeek 67B
- Подход: Собственные scaling laws https://arxiv.org/html/2401.02954v1 с учётом качества данных.
Исследователи обнаружили, что гиперпараметры, оказывающие наибольшее влияние на производительность это размер пакета - batch_size и скорость обучения - learning_rate.
Также размер модели N они заменили на \(M = \text{non-embedding_FLOPs}/token\) для представления масштаба модели, что приводит к более точной оптимальной стратегии распределения ресурсов между моделью и данными и лучшему прогнозу обобщающей потери для крупномасштабных моделей.
И формула \(C = 6ND\) была заменена на \(C = MD\)
Качество данных для предварительного обучения влияет на оптимальную стратегию распределения ресурсов между моделью и данными. Чем выше качество данных, тем больше увеличенного вычислительного бюджета следует выделять на масштабирование модели.
Сначала исследователи провели поиск по сетке для размера батча и скорости обучения в небольших экспериментах с вычислительным бюджетом 1e17 для определенного размера модели (177M FLOPs/token). Результаты демонстрируют, что ошибка обобщения остается стабильной в широком диапазоне значений размеров батча и скоростей обучения. Это указывает на то, что почти оптимальная производительность может быть достигнута в относительно широком пространстве параметров.
Затем был использован многоступенчатый планировщик скорости обучения для эффективного обучения нескольких моделей с разными размерами батча, скоростями обучения и вычислительными бюджетами в диапазоне от 1e17 до 2e19, повторно используя первую стадию.
Учитывая избыточность в пространстве параметров, исследователи считали параметры, используемые моделями, ошибка обобщения которых превышала минимальную не более чем на 0.25%, как почти оптимальные гиперпараметры. Затем подогнали размер пакета B и скорость обучения η в зависимости от вычислительного бюджета C.
Результаты подгонки показывают, что оптимальный размер батча \(B\) постепенно увеличивается с увеличением вычислительного бюджета \(C\), тогда как оптимальная скорость обучения \(η\) постепенно уменьшается. Это соответствует интуитивным эмпирическим настройкам размера батча и скорости обучения при масштабировании моделей. Кроме того, все почти оптимальные гиперпараметры попадают в широкий диапазон, что указывает на то, что относительно легко выбрать почти оптимальные параметры в этом интервале. Итоговые формулы, которые мы подогнали для размера пакета и скорости обучения, следующие:
Формулы для оптимальных гиперпараметров:
\[ \begin{split} \eta_{opt} = 0.3118 \cdot C^{-0.125} \\ \quad B_{opt} = 0.292 \cdot C^{0.3271} \end{split}\]
где
- \(C\) — бюджет вычислений в FLOPs.
- \(\eta\) - learning_rate (скорость обучения)
- \(B\) - размер батча
А оптимальный размер модели и данных при заданном размере компьюта C был
\(M_{opt} = M_{base}C^a, \text{где} M_{base} = 0.1715, a = 0.5243\)
\(D_{opt}=D_{base}C^b, \text{где} D_{base} = 5.8316, b = 0.4757\)
На примере DeepSeek v3 - модель имеет архмтектуру MoE и 671B параметров, была обучена на 14.8T токенов. Соотношение данных к параметрам 22:1 или \(D=20N + 20\%\) - вполне по классике Шиншиллы.
GPT-4 (OpenAI)
Мы не знаем публично внутреннюю кухню OpenAi, они не публикуют детали обучения и архитекруры моделей.
- Стратегия: Экстраполяция степенных законов с малых моделей. Тестовый loss предсказывался с точностью выше 95% - по информации компании.
Судя по тому как они привлекают деньги, они видимо умеют предсказывать качество будущих моделей, под что им и дают очередные миллиарды.
Практическое руководство по оценке параметров
Шаг 1: Определение бюджета \(C\)
Если следовать законам Шиншиллы, то вычислительный бюджет в FLOPs рассчитывается как:
\[ C \approx 6N_{opt}D_{opt}.\]
Для примера: при \(C = 10^{24}\) FLOPs (≈1000 GPU-лет):
\[ \begin{split} N_{opt} \approx 0.1715 \cdot (10^{24}/6)^{0.5243} \approx 70 \text{ млрд парам}, \\ D_{opt} \approx 5.8316 \cdot (10^{24}/6)^{0.4757} \approx 1.5 \text{ трлн ток}. \end{split}\]
- Ну или по-простому \(D:N \approx G:1, \text{где } G \sim [20-30]\) - примерно 20-30 токенов на 1 обучаемый параметр.
- Если готовы не экономить на обучении, ради экономии потом на инференсе, то по заветам Ламы3 - можно делать до 1000 токенов на обучающий параметр. У самой Ламы3 там было даже 1875 ток/параметр для маленькой модели 8b. Но в целом делать отношение \(G \sim [200-300]\) это ок, если вы готовы переплатить за претрейн, во имя более высокого качества на инференсе.
Шаг 2: Коррекция под качество данных Если данные содержат шум или дубликаты, коэффициент \(\beta\) в Chinchilla-формулах уменьшается. Например, для датасета с 50% дубликатов:
\[ D_{opt}^{corr} = D_{opt} \cdot (1 - 0.5)^{-0.7} \approx 1.6D_{opt}.\]
Шаг 3: Учёт архитектурных особенностей
- MoE-модели: Требуют увеличения \(D\) на 20% относительно dense-архитектур.
- Квантование: Методы типа FP16 или FP8 Mixed-Precision training (обучение квантованных моделей, обучение в смешанной точности) позволяют уменьшить бюджет вычислений \(С\) в за счет увеличения скорости вычислений, но требуют увеличения данных \(D\) условно на 30-50%. Чем агрессивнее квантование, тем больше данных может потребоваться, чтобы сгладить шумы от квантования.
Ограничения и нерешённые проблемы
- Emergent Abilities: Способности вроде цепочки рассуждений (chain-of-thought) не следуют степенным законам и проявляются скачкообразно при \(N > 10^{11}\).
- Долгосрочная динамика: Эксперименты DeepSeek показали, что после \(D > 5T\) токенов скорость улучшения замедляется на 40%.
- Энергетическая эффективность: Оптимальные по FLOPs в процессе обучения модели могут быть не оптимальны по энергопотреблению на инференсе. Например, Mistral 7B достигает 90% производительности LLaMA-33B при 5x меньшем энергопотреблении на инференс.
Законы масштабирования работали для плотных моделей, что подтверждается успехами Chinchilla, DeepSeek и GPT-4. Однако растущая сложность архитектур (MoE, мультимодальность) требует адаптации существующих оценок.
Ключевые направления будущих исследований:
- Интеграция энергетических метрик в scaling laws.
- Прогнозирование emergent abilities через теорию фазовых переходов.
Еще исследования
Hestness, Narang, et al, 2017
Статья 2017 года https://arxiv.org/abs/1712.00409 является общей точкой отсчета для законов масштабирования нейронных сетей, полученных путем статистического анализа экспериментальных данных. Ранее работы до 2000-х годов, упомянутые в статье, были либо теоретическими, либо на порядки меньше по масштабу. В то время как ранние работы обычно находили, что показатель масштабирования изменяется как \(L \propto D^{-\alpha}\), где \(\alpha \in \{0.5, 1, 2\}\), статья обнаружила, что \(\alpha \in [0.07, 0.35]\).
Из факторов, которые они варьировали, только задача может изменить показатель \(\alpha\). Изменение архитектуры, оптимизаторов, регуляризаторов и функций потерь изменяло только коэффициент пропорциональности, а не показатель. Например, для одной и той же задачи одна архитектура могла иметь \(L = 1000D^{-0.3}\), в то время как другая могла иметь \(L = 500D^{-0.3}\). Они также обнаружили, что для данной архитектуры количество параметров, необходимых для достижения наименьших уровней потерь при фиксированном размере выборки, растет как \(N \propto D^{\beta}\) для другого показателя \(\beta\).
Henighan, Kaplan, et al, 2020
Анализ 2020 года https://arxiv.org/abs/2010.14701 изучал статистические зависимости между \(C, N, D, L\) в широком диапазоне значений и обнаружил аналогичные законы масштабирования для \(N \in [10^3, 10^9]\), \(C \in [10^{12}, 10^{21}]\) и для нескольких модальностей (текст, видео, изображение, текст в изображение и т.д.).
В частности, обнаруженные законы масштабирования таковы:
- Для каждой модальности они фиксировали одну из двух переменных \(C, N\), варьируя другую (D варьировалась вместе с \(D = C / 6N\)), достижимый тестовый loss удовлетворяет \(L = L_0 + \left(\frac{x_0}{x}\right)^{\alpha}\), где \(x\) — варьируемая переменная, а \(L_0, x_0, \alpha\) — параметры, которые нужно найти статистической подгонкой. Параметр \(\alpha\) является наиболее важным.
- Когда \(N\) является варьируемой переменной, \(\alpha\) варьируется от 0.037 до 0.24 в зависимости от модальности модели. Это соответствует \(\alpha = 0.34\) из статьи о масштабировании Chinchilla.
- Когда \(C\) является варьируемой переменной, \(\alpha\) варьируется от 0.048 до 0.19 в зависимости от модальности модели. Это соответствует \(\beta = 0.28\) из статьи о масштабировании Chinchilla.
- При фиксированном бюджете вычислений оптимальное количество параметров модели составляет примерно \(N_{opt}(C) = \left(\frac{C}{5 \times 10^{-12} \text{ petaFLOP-day}}\right)^{0.7} = 9.0 \times 10^{-7} C^{0.7}\). Параметр \(9.0 \times 10^{-7}\) варьируется в пределах до 10 для различных модальностей. Показатель 0.7 варьируется от 0.64 до 0.75 для различных модальностей. Этот показатель соответствует \(\approx 0.5\) из статьи о масштабировании Chinchilla.
- "Сильно предполагается" (но не проверено статистически), что \(D_{opt}(C) \propto N_{opt}(C)^{0.4} \propto C^{0.28}\). Этот показатель соответствует \(\approx 0.5\) из статьи о масштабировании Chinchilla.
Закон масштабирования \(L = L_0 + \left(\frac{C_0}{C}\right)^{0.048}\) был подтвержден во время обучения GPT-3 https://arxiv.org/abs/2005.14165.
Расхождения и несоответствия с Шиншиллой
Анализ закона масштабирования Chinchilla для обучения трансформерных языковых моделей предполагает, что для данного бюджета вычислений (C), чтобы достичь минимальных значений loss на тесте после предобучения для этого бюджета, количество параметров модели (N) и количество обучающих токенов (D) должны масштабироваться в равных пропорциях, \(N_{opt}(C) \propto C^{0.5}\), \(D_{opt}(C) \propto C^{0.5}\). Этот вывод отличается от анализа, проведенного Kaplan et al., который обнаружил, что \(N\) должно увеличиваться быстрее, чем \(D\), \(N_{opt}(C) \propto C^{0.73}\), \(D_{opt}(C) \propto C^{0.27}\).
Это расхождение в основном можно объяснить тем, что в исследованиях использовались разные методы измерения размера модели; Kaplan et al. учитывали только невстраиваемые параметры, что при анализе меньших моделей приводило к смещенным коэффициентам. Вторичные эффекты также возникают из-за различий в настройке гиперпараметров и графиков скорости обучения.
Что еще есть кроме Шиншиллы
Поскольку масштабирование Chinchilla стало ориентиром для многих крупных обучающих запусков, существовала параллельная попытка "выходить за пределы масштабирования Chinchilla", то есть изменять часть пайплайна претрейн обучения, чтобы достичь тех же значений loss с меньшими усилиями или специально обучаться дольше, чем это "оптимально по Chinchilla".
Обычно цель состоит в том, чтобы сделать показатель степени закона масштабирования больше, что означает, что те же значения loss можно обучить за гораздо меньшие вычисления. Например, фильтрация данных может сделать показатель степени закона масштабирования больше.
Другое направление исследований изучает, как справляться с ограниченными данными, так как согласно законам масштабирования Chinchilla, размер обучающей выборки для самых крупных языковых моделей уже приближается к тому, что доступно в Интернете. Было обнаружено https://arxiv.org/abs/2305.16264, что дополнение пайплайна аугментированными (синтетически сгенерированными) данными + различными фильтрами для их очистки и дедупликации улучшает качество модели. Серия небольших языковых моделей Phi обучалась на синтетических данных, похожих на учебники, созданных другими более крупными языковыми моделями, для которых данные ограничены только количеством доступных вычислений.
Также исследуется оптимальное масштабирование, когда все доступные данные уже исчерпаны (например, в редких языках), поэтому нужно обучать несколько эпох на одной и той же выборке (в то время как масштабирование Chinchilla требует только одной эпохи).
Оптимальность Chinchilla была определена как "оптимальная для вычислительного обучения", тогда как в реальных моделях производственного качества будет много инференса после завершения обучения. И как показала Лама3 - изличшнее обучение во время претрейн-обучения может дать более высокое качество модели, что затем окупится в режиме использования модели в прикладных задачах. Модели LLaMA были переобучены по этой причине.
Последующие исследования обнаружили законы масштабирования в режиме переобучения для размеров выборок до 32x больше, чем оптимально по Chinchilla https://arxiv.org/abs/2403.08540
Нарушенные законы масштабирования нейронных сетей (BNSL)

Рис. 4. A Broken Neural Scaling Law (BNSL)
Анализ 2022 года https://arxiv.org/abs/2210.14891 обнаружил, что многие ситуации масштабрования следуют плавно нарушенному степенному закону:
\[ y = a + \left(b x^{-c_0}\right) \prod_{i=1}^{n} \left(1 + \left(\frac{x}{d_i}\right)^{1/f_i}\right)^{-c_i * f_i}\]
где \(x\) относится к масштабируемой величине (например, \(C\), \(N\), \(D\), количество обучающих шагов, количество шагов вывода или размер входных данных модели), а \(y\) относится к метрике оценки производительности (например, ошибка предсказания, перекрестная энтропия, ошибка калибровки, ROCAUС, процент BLEU score, F1 score, награда, рейтинг Elo, процент решенных задач или FID score) в режимах с zero-shot, с few-shot или с дообучением. Параметры \(a, b, c_0, c_1, \ldots, c_n, d_1, \ldots, d_n, f_1, \ldots, f_n\) находятся статистической подгонкой.
На логарифмическом графике, когда \(f_i\) не слишком велико и \(a\) вычитается из оси \(y\), эта функциональная форма выглядит как серия линейных сегментов, соединенных дугами; \(n\) переходов между сегментами называются "разрывами", отсюда и название нарушенные законы масштабирования нейронных сетей (BNSL).
Сценарии, в которых масштабирующее поведение нейронных сетей следовало этой функциональной форме, включают компьютерное зрение, языковые модели, аудио, видео, диффузию, генеративное моделирование, многомодальное обучение, контрастное обучение и много другое.
Архитектуры, для которых масштабирующее поведение нейронных сетей следовали этой функциональной форме, включают сетки с ResNet, трансформеры, полносвязные сетки MLP, рекуррентные нейронные сети, сверточные нейронные сети, графовые нейронные сети, U-nets, модели кодировщик-декодировщик (и только кодировщик) (и только декодировщик), MoE (смесь экспертов).
Масштабирование инференса
Помимо масштабирования вычислений обучения, можно также масштабировать вычисления инференса (или "вычисления в режиме применения"). Например, рейтинг Elo AlphaGo устойчиво улучшается по мере увеличения времени, которое он тратит на свой поиск Монте-Карло за игру. Для AlphaGo Zero увеличение Elo на 120 требует либо удвоения размера модели и обучения, либо удвоения поиска в режиме применения. Аналогично, языковая модель для решения соревновательных задач по программированию AlphaCode постоянно улучшала (логарифмически) производительность с увеличением времени поиска решения на инференсе.
Для игры Hex 10x вычислений в режиме обучения можно обменять на 15x вычислений в режиме применения. Для Libratus в безлимитный техасский холдем покер и Cicero в Diplomacy, а также для многих других абстрактных игр с частичной информацией, поиск в режиме инференса улучшает производительность с аналогичным коэффициентом обмена, до 100 000x фактического увеличения вычислений в режиме обучения.
В 2024 году отчет OpenAI o1 документировал, что производительность o1 постоянно улучшалась как с увеличением вычислений в режиме обучения, так и с увеличением вычислений в режиме применения, и привел многочисленные примеры масштабирования вычислений в режиме применения в математике, научных рассуждениях и задачах программирования.
Один из методов масштабирования вычислений в режиме инференса — это контроль на основе процесса, когда модель генерирует пошаговую цепочку рассуждений для ответа на вопрос, а другая модель (человек или ИИ) предоставляет оценку награды на некоторых промежуточных шагах, а не только на окончательном ответе. Контроль на основе процесса можно масштабировать произвольно, используя синтетическую оценку награды без другой модели, например, запуская развертывания Монте-Карло и оценивая каждый шаг в рассуждениях в зависимости от того, насколько вероятно, что он приведет к правильному ответу. Другой метод — это модели пересмотра, которые обучены решать задачу несколько раз, каждый раз пересматривая предыдущую попытку.
Vision-Трансформеры
Vision-Трансформеры, аналогично языковым трансформерам, демонстрируют законы масштабирования. Исследование 2022 года https://arxiv.org/abs/2106.04560 обучало трансформеры зрения с количеством параметров \(N \in [5 \times 10^6, 2 \times 10^9]\) на наборах изображений размером \(D \in [3 \times 10^7, 3 \times 10^9]\) для вычислений \(C \in [0.2, 10^4]\) (в единицах TPUv3-core-days).
После обучения модели она дообучается на обучающем наборе ImageNet. Пусть \(L\) — вероятность ошибки дообученной модели при классификации тестового набора ImageNet. Они обнаружили \(\min_{N, D} L = 0.09 + \frac{0.26}{(C + 0.01)^{0.35}}\).
Нейронный машинный перевод
Ghorbani, Behrooz et al. https://arxiv.org/abs/2109.07740 изучали законы масштабирования для нейронного машинного перевода (в частности, с английского на немецкий) в моделях трансформеров кодировщик-декодировщик, обученных до сходимости на одних и тех же наборах данных (таким образом, они не подгоняли законы масштабирования для вычислительных затрат \(C\) или размера выборки \(D\)). Они варьировали \(N \in [10^8, 3.5 \times 10^9]\). Они обнаружили три результата:
- \(L\) — это функция закона масштабирования от \(N_E, N_D\), где \(N_E, N_D\) — количество параметров кодировщика и декодировщика. Это не просто функция от общего количества параметров \(N = N_E + N_D\). Функция имеет вид \(L(N_e, N_d) = \alpha \left(\frac{\bar{N}_e}{N_e}\right)^{p_e} \left(\frac{\bar{N}_d}{N_d}\right)^{p_d} + L_{\infty}\), где \(\alpha, p_e, p_d, L_{\infty}, \bar{N}_e, \bar{N}_d\) — подгоночные параметры. Они обнаружили, что \(N_d / N \approx 0.55\) минимизирует потери при фиксированном \(N\).
- \(L\) "насыщается" (то есть достигает \(L_{\infty}\)) для меньших моделей, когда обучающие и тестовые наборы данных "естественны для источника" по сравнению с "естественными для цели". "Естественный для источника" элемент данных означает пару предложений на английском и немецком языках, и модель должна перевести английское предложение на немецкое, при этом английское предложение написано естественным английским автором, а немецкое предложение переведено с английского машинным переводчиком. Чтобы создать два типа наборов данных, авторы собрали естественные английские и немецкие предложения в интернете, а затем использовали машинный перевод для генерации их переводов.
- По мере роста моделей, модели, обученные на наборах данных с оригиналами источников, могут достигать низких потерь, но плохого BLEU score. В то же время модели, обученные на наборах данных с оригиналами целей, достигают низких потерь и хорошего BLEU score одновременно.
Авторы предполагают, что наборы данных, естественные для источника, имеют однообразные и скучные целевые предложения, и модель, обученная предсказывать целевые предложения, быстро переобучается.
Трансферное обучение - transfer learning
Hernandez, Danny et al. https://arxiv.org/abs/2102.01293 изучали законы масштабирования для трансферного обучения в языковых моделях. Они обучали семейство трансформеров тремя способами:
- предобучение на английском, дообучение на Python
- предобучение на равной смеси английского и Python, дообучение на Python
- обучение на Python
Идея в том, что предобучение на английском должно помочь модели достичь низких потерь на тестовом наборе текстов на Python. Предположим, что модель имеет количество параметров \(N\), и после дообучения на \(D_F\) токенах Python она достигает некоторых потерь \(L\). Говорят, что у нее "переданное количество токенов" \(D_T\), если другая модель с тем же \(N\) достигает тех же \(L\) после обучения на \(D_F + D_T\) токенах Python.
Они обнаружили \(D_T = 1.9e4 \left(D_F\right)^{0.18} \left(N\right)^{0.38}\) для предобучения на английском тексте и \(D_T = 2.1e5 \left(D_F\right)^{0.096} \left(N\right)^{0.38}\) для предобучения на английском и не Python коде.
Точность и квантование
Kumar et al. https://arxiv.org/abs/2411.04330 изучали законы масштабирования для числовой точности при обучении языковых моделей. Они обучали семейство языковых моделей с весами, активациями и кэшем KV в различной числовой точности как в целочисленном, так и в формате с плавающей запятой, чтобы измерить влияние точности на loss в зависимости от точности. Для обучения их закон масштабирования учитывает более низкую точность, оборачивая эффекты точности в "общее эффективное количество параметров", которое управляет масштабированием loss, используя параметризацию \(N \mapsto N_{\text{eff}}(P) = N(1 - e^{-P / \gamma})^3\). Это иллюстрирует, как обучение в более низкой точности ухудшает производительность, уменьшая реальную емкость модели по экспоненте с битами.
Для инференса они обнаруживают, что чрезмерное обучение языковых моделей за пределами оптимальности Chinchilla может привести к тому, что модели будут более чувствительны к квантованию, стандартной технике для эффективного глубокого обучения. Это проявляется в том, что ухудшение loss из-за квантования весов увеличивается как приближенный степенной закон в соотношении токенов/параметров \(D / N\), наблюдаемом во время предобучения, так что модели, предобученные на больших корпусах, могут работать хуже в терминах валидационных потерь, чем те, которые обучались на более скромных корупсах и близки к Шиншилла оптимальности, если после обучения применяется квантование.
Другие работы, исследующие эффекты чрезмерного обучения, включают Sardana et al https://arxiv.org/abs/2401.00448 и Gadre et al. https://arxiv.org/abs/2403.08540