AWQ (Activation-Aware Weight Quantization) и его отличия от GPTQ квантования LLM
Основные принципы работы
GPTQ (Gradient-based Post-Training Quantization) представляет собой метод пошаговой оптимизации слоев для минимизации ошибки квантования, использующий информацию о градиентах и гессиане для точной настройки весов. Этот подход обрабатывает модель слой за слоем, минимизируя ошибку квантования с использованием калибровочных данных и вторых производных.
AWQ (Activation-aware Weight Quantization) - это технология активационно-зависимого квантования весов, направленная на оптимизацию эффективности выполнения LLM через учет статистики активаций. В отличие от GPTQ, AWQ фокусируется на методе выбора весов с учетом их взаимодействия с активациями нейронной сети.
https://huggingface.co/docs/transformers/main/en/quantization/awq
Ключевые различия
1. Философия квантования
Основное различие между AWQ и GPTQ заключается в том, что AWQ предполагает, что не все веса одинаково важны для сохранения качества модели. В то время как GPTQ применяет однородное квантование ко всем весам слоя с последующей оптимизацией, AWQ идентифицирует критически важные веса и сохраняет их в более высокой точности (обычно 0.1% самых важных весов остаются в FP16).
2. Учет активаций
AWQ анализирует статистику активаций для определения, какие веса имеют наибольшее влияние на выходные значения. Метод не квантует все веса одинаково, а вместо этого сохраняет небольшой процент наиболее важных весов без квантования, основываясь на их взаимодействии с активациями. GPTQ же не учитывает специфику активаций при выборе весов для более точного квантования.
3. Вычислительная сложность
Процесс квантования AWQ обычно быстрее, чем GPTQ, так как избегает решения сложных оптимизационных задач для каждого слоя. GPTQ требует значительных вычислительных ресурсов из-за необходимости вычисления и использования гессиана для оптимизации весов, что делает процесс квантования медленнее.
4. Точность и производительность
GPTQ превосходит AWQ в обеспечении высокой точности при низкобитовом квантовании (особенно на 3-4 бит), но требует больше времени на процесс квантования. В то же время, в некоторых исследованиях AWQ демонстрирует лучшие результаты по сравнению с GPTQ на наборе из 12 тестовых наборов данных. Однако другие исследования показывают, что на реальных бенчмарках GPTQ последовательно превосходит AWQ с более значительными отрывами в 2.9 и 0.8 соответственно.
5. Гибкость и адаптивность
AWQ является более адаптивным методом, так как динамически определяет, какие веса следует квантовать менее агрессивно на основе статистики активаций. GPTQ же применяет более универсальный подход к оптимизации, который может быть менее эффективен для моделей с неоднородной структурой весов.
Практические рекомендации
-
Выбор GPTQ: Предпочтителен, когда критически важна максимальная точность при низкобитовом квантовании (4 бита и ниже), а время на процесс квантования не является ограничивающим фактором.
-
Выбор AWQ: Рекомендуется, когда требуется баланс между скоростью квантования, точностью и скоростью инференса, особенно для развертывания в production-средах с ограниченными ресурсами.
Оба метода представляют собой важные достижения в области квантования LLM, но их эффективность может варьироваться в зависимости от конкретной архитектуры модели и задачи, что подчеркивает необходимость эмпирической проверки для каждого конкретного случая.
Применение AWQ с использованием AutoAWQ
Библиотека AutoAWQ предоставляет удобный интерфейс для применения алгоритма Activation-Aware Weight Quantization (AWQ, квантизация весов с учётом активаций) к моделям Hugging Face Transformers. AWQ минимизирует ошибку квантизации для весов, которые значительно влияют на выход модели. Она определяет такие веса, наблюдая за величиной соответствующих активаций с использованием калибровочных данных. Этот избирательный подход позволяет более эффективно сохранять точность модели, особенно при очень низких битовых скоростях, таких как 4-битная квантизация.
Transformers поддерживает загрузку моделей, квантованных с помощью autoawq, что позволяет легко интегрировать их в существующие рабочие процессы.
Важные замечания
- Для квантования требуется калибровочный датасет, обычно берутся данные из WikiText или других источников.
- AWQ сохраняет 0.1% самых важных весов в высокой точности (FP16), что помогает сохранить качество модели при квантовании.
- Вы можете выбрать одну из более чем 6500 моделей на Hugging Face Hub, уже квантованных с помощью AWQ, или квантовать свои собственные модели.
- AWQ обеспечивает более низкую задержку и использование памяти по сравнению с другими методами квантования, что делает его привлекательным для production-развертывания.
Если вы предпочитаете использовать готовые квантованные модели, на Hugging Face Hub доступно множество моделей с постфиксом "AWQ" в названии, таких как TheBloke/CodeLlama-7B-Python-AWQ.
Это позволяет пропустить этап квантования и сразу начать использовать оптимизированную модель.
Понимание процесса работы AutoAWQ
Библиотека AutoAWQ значительно упрощает процесс. Она автоматически рассчитывает масштабные коэффициенты и выполняет квантизацию весов на основе метода AWQ, плавно интегрируясь с экосистемой Hugging Face. Типичные шаги включают:
- загрузку модели,
- выполнение квантизации с использованием калибровочных данных,
- сохранение артефактов квантизованной модели.
Установка
Сначала убедитесь, что у вас установлена библиотека AutoAWQ и все необходимые зависимости. Обычно требуются PyTorch и Transformers. Установка через pip:
pip install autoawqПри необходимости установите конкретную версию PyTorch (например, для CUDA 11.8):
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Всегда сверяйтесь с официальным репозиторием AutoAWQ для получения актуальных инструкций по установке и требований к совместимости (например, версия CUDA, версия PyTorch).
Квантизация модели с помощью AutoAWQ
Рассмотрим процесс квантизации предобученной языковой модели с использованием AutoAWQ.
-
Загрузка модели и токенайзера: Начните с загрузки предобученной модели и соответствующего токенайзера с помощью класса
AutoAWQForCausalLMи стандартногоAutoTokenizerиз Transformers. -
Определение конфигурации квантизации: Укажите параметры для AWQ-квантизации. Основные параметры:
w_bit: целевая битовая глубина для весов (например, 4).q_group_size: количество весов, использующих общие параметры квантизации (масштаб и нулевая точка). Меньший размер группы может улучшить точность, но может незначительно увеличить размер модели и вычислительные накладные расходы. Типичные значения: 64, 128.zero_point: логическое значение, указывающее, использовать ли нулевую точку (асимметричная квантизация) или нет (симметричная). AWQ часто работает лучше сzero_point=True.
-
Подготовка калибровочных данных: AWQ использует калибровочные данные для выявления значимых весов. Как обсуждалось ранее, это должен быть небольшой, но репрезентативный набор данных, с которым модель столкнётся во время инференса. Данные необходимо токенизировать перед передачей в метод
quantize. Часто достаточно списка строк, которые затем токенизируются. -
Выполнение квантизации: Вызовите метод
quantizeдля загруженной модели, передав токенайзер, конфигурацию квантизации и подготовленные калибровочные данные. AutoAWQ выполнит анализ и квантизацию на месте. -
Сохранение квантизованной модели: Используйте метод
save_quantizedдля сохранения квантизованных весов и необходимых конфигурационных файлов. Токенайзер также должен быть сохранён вместе с моделью.
Пример кода на Python:
import torch
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
# Путь к модели и куда сохранить квантизованную модель
model_path = "meta-llama/Llama-2-7b-hf" # Пример ID модели из Hugging Face Hub
quant_path = "models/llama-2-7b-awq" # Локальный путь для сохранения квантизованной модели
quant_config = {
"w_bit": 4, # Целевая битовая глубина для весов
"q_group_size": 128, # Размер группы для параметров квантизации
"zero_point": True # Использовать асимметричную квантизацию
}
# Загрузка неквантизованной модели и токенайзера
print(f"Загрузка модели: {model_path}...")
model = AutoAWQForCausalLM.from_pretrained(
model_path,
safetensors=True, # Предпочтительно использовать safetensors
device_map="auto" # Автоматическое распределение по доступным GPU
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
print("Модель и токенайзер загружены.")
# Подготовка калибровочных данных
calibration_texts = [
"Область больших языковых моделей быстро развивается.",
"Квантизация помогает снизить вычислительные затраты на инференс.",
"AWQ — это метод пост-обучающей квантизации.",
"Калибровочные данные важны для точной квантизации."
]
print("Подготовка калибровочных данных...")
# Выполнение квантизации
print("Начало AWQ-квантизации...")
model.quantize(
tokenizer=tokenizer,
quant_config=quant_config,
calibration_data=calibration_texts # Передаём список строк напрямую
)
print("Квантизация завершена.")
# Сохранение квантизованной модели
print(f"Сохранение квантизованной модели в: {quant_path}")
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path) # Сохраняем токенайзер вместе с моделью
print("Квантизованная модель и токенайзер успешно сохранены.")
# Очистка памяти (опционально)
# del model
# torch.cuda.empty_cache()Этот скрипт квантизует указанную модель с помощью алгоритма AWQ и сохраняет результаты, обычно включая файлы .safetensors для весов и JSON-файлы конфигурации. Основное преимущество — значительное сокращение размера модели на диске.
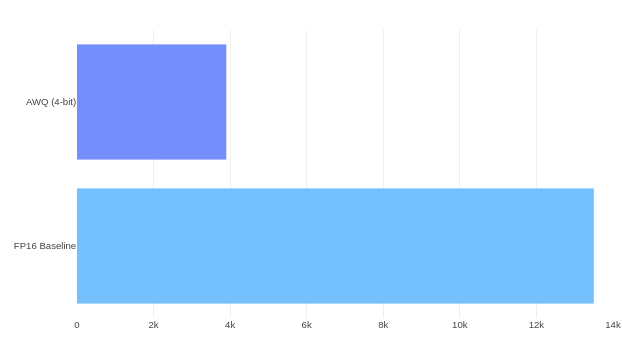
Рис. 1. Примерное сокращение объёма модели с 7 миллиардами параметров при квантизации с FP16 до AWQ 4-бит. Фактический размер зависит от размера группы и метаданных.
Загрузка и использование квантизованной модели
После сохранения квантизованную модель можно загрузить для инференса с помощью метода AutoAWQForCausalLM.from_quantized. Этот метод ожидает путь, по которому сохранены артефакты квантизации.
Пример кода:
import torch
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer, pipeline
quant_path = "models/llama-2-7b-awq"
device_map = "auto" # Или укажите конкретное устройство, например "cuda:0"
# Загрузка квантизованной модели и токенайзера
print(f"Загрузка квантизованной модели из: {quant_path}")
model = AutoAWQForCausalLM.from_quantized(quant_path, device_map=device_map, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(quant_path, trust_remote_code=True)
print("Квантизованная модель и токенайзер загружены.")
# Настройка пайплайна для инференса (опционально, для демонстрации)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer, device=device_map)
# Пример инференса
prompt = "Что такое Activation-Aware Weight Quantization (AWQ)?"
print(f"\nВыполнение инференса с промптом: '{prompt}'")
outputs = pipe(prompt, max_new_tokens=60, do_sample=True, temperature=0.7)
print("Сгенерированный текст:")
print(outputs[0]['generated_text'])
# Очистка памяти (опционально)
# del model
# del pipe
# torch.cuda.empty_cache()Это демонстрирует, как загрузить оптимизированную модель обратно в память и использовать её для задач, таких как генерация текста. Преимущества в производительности (задержка, пропускная способность, использование памяти) будут подробно рассмотрены в главе 3.
Использование AutoAWQ: ключевые моменты
- Качество калибровочных данных: Эффективность AWQ зависит от того, насколько точно калибровочные данные отражают паттерны активаций, с которыми модель столкнётся во время инференса. Использование разнообразных и репрезентативных образцов важно для сохранения точности модели.
- Аппаратное обеспечение и ядра: Для достижения максимального ускорения от AWQ-квантизованных моделей часто требуются специализированные вычислительные ядра, оптимизированные для матричного умножения с низкой битностью и выбранным размером группы. AutoAWQ часто включает оптимизированные ядра, а фреймворки для деплоя, такие как vLLM, также предоставляют высокооптимизированные реализации, совместимые с форматами AWQ. Убедитесь, что ваша среда деплоя использует эти ядра.
- Совместимость моделей: Хотя AutoAWQ поддерживает многие популярные архитектуры LLM, всегда проверяйте документацию библиотеки на предмет совместимости с конкретными моделями или известными ограничениями.
Используя библиотеку AutoAWQ, вы получаете доступ к мощной технике квантизации LLM, значительно снижающей требования к ресурсам при сохранении высокой точности. Это подготавливает модели к более эффективному деплою, что является темой последующих глав.
vLLM поддерживает AWQ, что позволяет напрямую использовать предоставленные AWQ-модели или те, что квантованы с помощью AutoAWQ.
Поддержка AWQ в vLLM в настоящее время недостаточно оптимизирована, и для лучшей точности может быть рекомендовано использование не квантованной версии модели. AWQ в vLLM лучше подходит для низколатентного вывода с небольшим количеством одновременных запросов. Реализация AWQ в vLLM имеет более низкую пропускную способность по сравнению с не квантованной версией модели.
from vllm import LLM, SamplingParams
# Настройка параметров генерации
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=512
)
# Загрузка AWQ-квантованной модели
llm = LLM(
model="TheBloke/Llama-2-7B-AWQ",
quantization="awq", # обязательный параметр для активации AWQ
dtype="float16", # тип данных для вычислений
tensor_parallel_size=1 # количество GPU для параллельной обработки
)
# Выполнение инференса
outputs = llm.generate(["Как работает квантование LLM?"], sampling_params)
for output in outputs:
print(output.outputs[0].text)