Qwen2.5-Coder - обзор стратегии обучения
Архитектура Qwen2.5-Coder основана на архитектуре Qwen2.5. В таблице 1 представлены гиперпараметры архитектуры модели Qwen2.5-Coder для шести различных размеров: 0.5B, 1.5B, 3B, 7B, 14B и 32B параметров.
Хотя все модели имеют одинаковый размер голов (head size), они различаются по ряду других ключевых параметров. Например, модель 1.5B имеет увеличенный промежуточный размер (intermediate size), а модель 3B — больше слоёв. В целом, большинство параметров увеличиваются по мере роста размера модели. Для сравнения, модель 7B имеет скрытый размер (hidden size) 3 584, тогда как модель 32B — 5 120. Модель 7B использует 28 голов запросов (query heads) и 4 головы ключ-значение (key-value heads), в то время как модель 32B — 40 голов запросов и 8 голов ключ-значение, что отражает её повышенную ёмкость.
Промежуточный размер также масштабируется с увеличением модели: 18 944 для модели 7B и 27 648 для модели 32B.Кроме того, более мелкие модели используют связывание эмбеддингов (embedding tying), в то время как более крупные — нет. Обе модели имеют размер словаря 151 646 токенов и обучаются на 5,5 триллионах токенов.
| Configuration | 0.5B | 1.5B | 3B | 7B | 14B | 32B |
|---|---|---|---|---|---|---|
| Hidden Size | 896 | 1,536 | 2048 | 3,584 | 5120 | 5120 |
| # Layers | 24 | 28 | 36 | 28 | 48 | 64 |
| # Query Heads | 14 | 12 | 16 | 28 | 40 | 40 |
| # KV Heads | 2 | 2 | 2 | 4 | 8 | 8 |
| Head Size | 128 | 128 | 128 | 128 | 128 | 128 |
| Intermediate Size | 4,864 | 8,960 | 4,864 | 18,944 | 13824 | 27648 |
| Embedding Tying | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ |
| Vocabulary Size | 151,646 | 151,646 | 151,646 | 151,646 | 151,646 | 151,646 |
| # Trained Tokens | 5.5T | 5.5T | 5.5T | 5.5T | 5.5T | 5.5T |
Таблица 1.Гиперпараметры архитектуры моделей
Embedding tying
Embedding tying в больших языковых моделях (LLM) означает совместное использование параметров между слоем входных эмбеддингов (word embedding) и выходным слоем модели (часто называемым LM Head или классификатором). Идея заключается в том, что преобразование, используемое для представления входного токена в виде вектора (эмбеддинга), и преобразование, используемое для предсказания следующего токена из последнего скрытого состояния, разделяют одни и те же веса. Почему? А почему бы и нет! Попробовали - хуже не стало, а параметров в модели стало меньше.
В архитектуре языковых моделей обычно используются две матрицы:
- Входной эмбеддинг (U) — преобразует ID токена в его векторное представление (обычно реализуется как nn.Embedding в PyTorch).
- Выходной эмбеддинг (V) — преобразует векторное представление токена в распределение вероятностей по словарю (обычно реализуется как nn.Linear в PyTorch).
Авторы работы отмечают, что к этим матрицам предъявляются схожие требования¹:
- Для U ожидается, что семантически близкие токены будут иметь похожие эмбеддинги.
- Для V ожидается, что взаимозаменяемые токены будут иметь схожие оценки.
Кроме того, матрицы U и V имеют одинаковый размер. Это наводит на интуитивный вопрос: можно ли использовать одну и ту же матрицу весов для входного и выходного эмбеддингов?
Ответ: да. И вот пример как легко это сделать.
in_features, hidden_dim = 3, 4
U = nn.Embedding(in_features, hidden_dim)
V = nn.Linear(hidden_dim, in_features, bias=False)
# Связать матрицы можно простым присваиванием:
U.weight = V.weightПреимущества использования одной матрицы для разных слоев очевидны:
- Сокращается количество параметров модели.
- Сохраняется или даже улучшается производительность, включая снижение перплексии.
Важно понимать, что даже если веса эмбеддингов и LM Head совпадают, промежуточные слои трансформера модифицируют представление, поэтому выход зависит не только от входа, но и от контекста и полученные на выходе эмбеддинги последнего слоя перед LM-head отличаются от входных эмбеддингов.
Токенизация
Qwen2.5-Coder наследует словарь от Qwen2.5, но добавляет несколько специальных токенов, которые помогают модели лучше понимать код. В Таблице 2 представлен обзор специальных токенов, добавленных в процессе обучения для более эффективного захвата различных форм данных кода. Эти токены выполняют специфические функции в конвейере обработки кода.
Например:
- <|endoftext|> обозначает конец текста или последовательности.
- Токены <|fim_prefix|>, <|fim_middle|> и <|fim_suffix|> используются для реализации техники Fill-in-the-Middle (FIM) (Bavarian et al., 2022), где модель предсказывает отсутствующие части блока кода.
- Токен <|fim_pad|> применяется для дополнения (padding) при операциях FIM.
Другие токены включают:
- <|repo_name|>, который идентифицирует названия репозиториев.
- <|file_sep|>, используемый в качестве разделителя файлов для более эффективного управления информацией на уровне репозитория.
Эти токены играют ключевую роль, помогая модели обучаться на разнообразных структурах кода и обрабатывать более длинные и сложные контексты как на уровне файлов, так и на уровне репозиториев во время предобучения.
| Токен | Token ID | Описание |
|---|---|---|
| <|endoftext|> | 151643 | Конец текста/последовательности |
| <|fim_prefix|> | 151659 | Префикс FIM |
| <|fim_middle|> | 151660 | Средняя часть FIM |
| <|fim_suffix|> | 151661 | Суффикс FIM |
| <|fim_pad|> | 151662 | Заполнение FIM |
| <|repo_name|> | 151663 | Название репозитория |
| <|file_sep|> | 151664 | Разделитель файлов |
Таблица 2. Спец токены Qwen2.5-Coder
Данные для обучения pretraining
Масштабные, высококачественные и разнообразные данные являются основой для предобучения моделей. С этой целью был создан датасет Qwen2.5-Coder-Data. Этот датасет включает пять ключевых типов данных:
- Данные исходного кода (Source Code Data)
- Данные для связывания текста и кода (Text-Code Grounding Data)
- Синтетические данные (Synthetic Data)
- Математические данные (Math Data)
- Текстовые данные (Text Data)
Исходный код
Собрали публичные репозитории с GitHub, созданные до февраля 2024 года, охватывающие 92 языка программирования. Аналогично StarCoder2 (Lozhkov et al., 2024) и DS-Coder (Guo et al., 2024a), применили ряд методов фильтрации на основе правил. Помимо исходного кода, также собрали данные из Pull Requests, коммитов, Jupyter Notebooks и датасетов Kaggle, все из которых прошли аналогичные процедуры очистки на основе правил.
Данные для связывания текста и кода (Text-Code Grounding Data)
Отобрали крупномасштабный и высококачественный датасет, сочетающий текст и код, из Common Crawl. В него вошли документация, руководства, блоги и другие материалы, связанные с кодом. Вместо традиционного многоэтапного метода отбора на основе URL разработали иерархический подход фильтрации "от грубого к точному".
Этот метод фильтрации имеет два ключевых преимущества:
- Позволяет точно контролировать ответственность каждого фильтра, обеспечивая всестороннюю обработку по каждому измерению.
- Естественным образом присваивает датасету оценки качества: данные, сохранённые на финальном этапе, имеют более высокое качество, что даёт ценные сведения для качественного смешивания данных.
Для очистки данных Text-Code Grounding разработали конвейер, где каждый уровень фильтрации строится на основе небольших моделей, таких как fastText. Хотя исследователи экспериментировали с более крупными моделями, они не показали значительных преимуществ. Вероятно, это связано с тем, что небольшие модели сосредоточены на поверхностных признаках, избегая излишней семантической сложности.
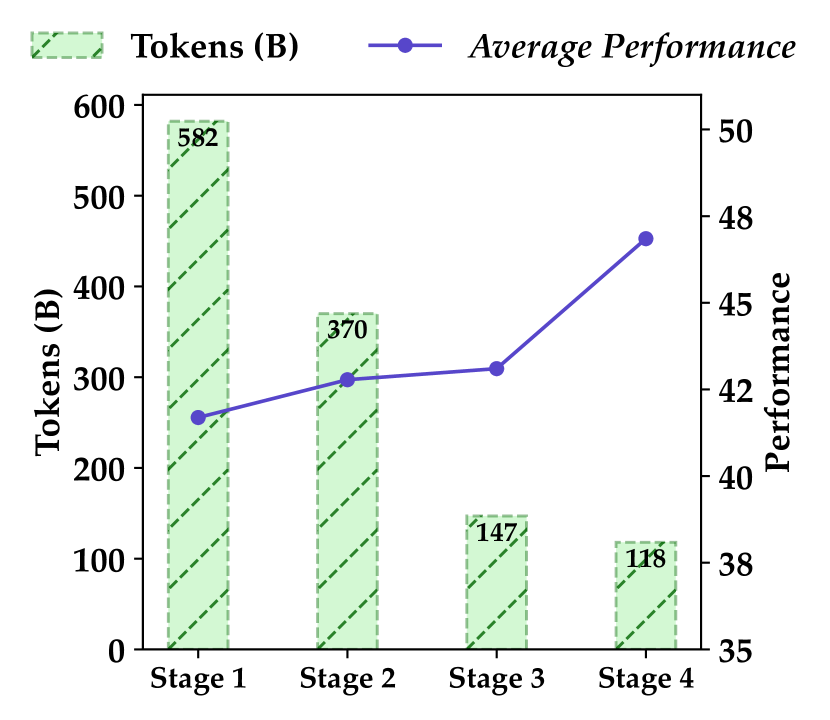
В Qwen2.5-Coder применили этот процесс итеративно. Как показано на Рисунке 1, каждая итерация улучшала показатели модели Qwen2.5-Coder-1.5B. После 4-этапной фильтрации средние результаты на HumanEval и MBPP выросли с 41.6% до 46.8% по сравнению с базовой моделью, что подтверждает ценность высококачественных данных Text-Code Grounding для генерации кода.
Синтетические данные (Synthetic Data)
Синтетические данные предлагают перспективный способ решения проблемы нехватки обучающих данных. Исследователи использовали CodeQwen1.5 — предшественника Qwen2.5-Coder — для генерации крупномасштабных синтетических датасетов. Чтобы снизить риск "галлюцинаций" (некорректных генераций), внедрили исполнитель (executor) для валидации, гарантируя, что сохраняется только исполняемый код.
Математические данные (Math Data)
Для улучшения математических способностей Qwen2.5-Coder интегрировали предобучающий корпус из Qwen2.5-Math в датасет Qwen2.5-Coder. Важно отметить, что включение математических данных не ухудшило производительность модели на задачах, связанных с кодом. Подробнее о процессе сбора и очистки можно узнать в техническом отчёте Qwen2.5-Math.
Текстовые данные (Text Data)
Аналогично математическим данным, включили высококачественные общие текстовые данные из предобучающего корпуса Qwen2.5, чтобы сохранить общие возможности Qwen2.5-Coder. Эти данные уже прошли строгий контроль качества на этапе очистки датасета Qwen2.5, поэтому дополнительная обработка не требовалась. Однако все фрагменты кода были удалены из общих текстовых данных, чтобы избежать дублирования с данными по коду и обеспечить независимость источников.
Смешивание данных
Баланс между кодом, математическими и текстовыми данными имеет решающее значение для создания базовой модели. Хотя исследовательское сообщество уже изучало этот вопрос, доказательств масштабируемости таких подходов на крупных датасетах недостаточно. Чтобы решить эту проблему, исследователи провели эмпирические эксперименты с разными пропорциями кода, математических и текстовых данных, разработав несколько тестов для быстрого определения оптимального сочетания.
В частности, как показано в Таблице 3, сравнили три различных соотношения для Qwen2.5-Coder-7B:
- 100:0:0 (только код),
- 85:10:5 (код, текст, математика),
- 70:20:10 (код, текст, математика).
Интересно, что соотношение 7:2:1 (70% кода, 20% текста, 10% математики) показало лучшие результаты, чем другие варианты, превзойдя даже группы с большей долей кода. Возможное объяснение заключается в том, что математические и текстовые данные могут положительно влиять на производительность модели в задачах, связанных с кодом, но только при достижении определённого порога концентрации.
В будущих исследованиях планируется изучить более эффективные механизмы подбора пропорций и глубже исследовать причины этого явления. В итоге выбрали финальное соотношение: 70% кода, 20% текста и 10% математики. Финальный обучающий датасет включает 5,2 триллиона токенов.
| Token Ratio (Код:Текст:Математика) | Coding | Math | General | Средний показатель | ||||
|---|---|---|---|---|---|---|---|---|
| Common | BCB | MATH | GSM8K | MMLU | CEval | HellaSwag | ||
| 100:0:0 | 49.8 | 40.3 | 10.3 | 23.8 | 42.8 | 35.9 | 58.3 | 31.3 |
| 85:15:5 | 43.3 | 36.2 | 26.1 | 52.5 | 56.8 | 57.1 | 70.0 | 48.9 |
| 70:20:10 | 48.3 | 38.3 | 33.2 | 64.5 | 62.9 | 64.0 | 73.5 | 55.0 |
Таблица 3. Эффективность обучения Qwen2.5-Coder при различных вариантах смешивания данных
Процесс обучения
Как показано на рисунке 2, использовали трёхэтапный подход к обучению модели Qwen2.5-Coder, который включает:
- Предобучение на уровне файлов (file-level pretraining),
- Предобучение на уровне репозиториев (repo-level pretraining),
- Настройку на инструкциях (instruction tuning).

Предобучение на уровне файлов (File-Level Pretraining)
На этом этапе модель обучается на индивидуальных файлах с кодом. Максимальная длина обучающей последовательности составляет 8 192 токена, а объём высококачественных данных — 5,2 триллиона токенов. Основные задачи обучения:
- Предсказание следующего токена (next token prediction),
- Fill-in-the-Middle (FIM) (Bavarian et al., 2022).
Формат FIM на уровне файлов представлен на Рисунке 3.

Предобучение на уровне репозиториев (Repo-Level Pretraining)
После предобучения на уровне файлов перешли к предобучению на уровне репозиториев, целью которого является улучшение способности модели работать с длинными контекстами. На этом этапе:
- Длина контекста увеличивается с 8 192 до 32 768 токенов.
- Базовая частота RoPE (Rotary Position Embedding) изменяется с 10 000 до 1 000 000.
- Для дальнейшего расширения возможностей модели по экстраполяции применяется механизм YARN (Peng et al., 2023), что позволяет модели обрабатывать последовательности длиной до 131 072 токенов (128K).
На этом этапе используется большой объём высококачественных данных с длинным контекстом (≈ 300 млрд токенов). Метод FIM расширяется с уровня файлов до уровня репозиториев в соответствии с подходами, описанными в работе Lozhkov et al. (2024). Формат FIM на уровне репозиториев представлен на Рисунке 4.

Пост-обучение (Post-training) - создание инструктивных данных
Идентификация мультиязычного программного кода
Дообучили модель CodeBERT (Feng et al., 2020) для классификации документов по почти 100 языкам программирования. Исследователи сохранили инструкционные данные для основных языков программирования и случайным образом отбрасывали часть данных для редких языков. Если образец содержит очень мало кода или не содержит фрагментов кода вообще, он может быть классифицирован как "Без языка программирования". Поскольку слишком большое количество инструкционных образцов без фрагментов кода ухудшает производительность модели на задачах генерации кода (например, MultiPL-E, McEval, MdEval), удалили большинство таких образцов, чтобы сохранить способность модели генерировать код.
Синтез инструкций из GitHub
Для неразмеченных данных (фрагментов кода), массово представленных на многих сайтах (например, GitHub), пытались создать размеченный инструкционный датасет с помощью LLM. Конкретно:
- Используем LLM для генерации инструкций из фрагментов кода (до 1024 токенов).
- Затем используем специализированную кодовую LLM для генерации ответов (Wei et al., 2024; Sun et al., 2024; Yu et al., 2024).
- В конце применяем LLM-оценщик для фильтрации низкокачественных пар и получения финального набора данных.
На основе фрагментов кода на разных языках программирования создаём инструкционный датасет. Чтобы полностью раскрыть потенциал такого метода, также включаем открытые инструкционные датасеты (например, McEval-Instruct для массовой мультиязычной генерации и отладки кода) в начальный набор инструкций. В итоге объединяем инструкционные данные из фрагментов кода GitHub и открытых источников для контролируемого дообучения SFT.
Мультиязычные инструкционные данные по коду
Для преодоления разрыва между разными языками программирования предлагатся использовать мультиязычную мультиагентную коллаборативную платформу для синтеза мультиязычных инструкционных корпусов. Исследователи ввели агентов, специализирующихся на языках программирования, где каждый агент отвечает за определённый язык. Эти агенты инициализируются данными, специфичными для языка, полученными из ограниченных существующих мультиязычных инструкционных корпусов.
Процесс генерации мультиязычных данных можно разделить на следующие этапы:
- Языково-специфичные интеллектуальные агенты: Создаются специализированные агенты, каждый из которых посвящён определённому языку программирования. Они инициализируются данными, специфичными для языка, полученными из отобранных фрагментов кода.
- Протокол коллаборативного обсуждения: Несколько языково-специфичных агентов участвуют в структурированном диалоге для формулировки новых инструкций и решений. Этот процесс может привести к улучшению существующих языковых возможностей или генерации инструкций для нового языка программирования.
- Адаптивная система памяти: Каждый агент поддерживает динамическую базу памяти, хранящую историю генераций, чтобы избежать создания похожих образцов.
- Межъязыковое обсуждение: внедряем новую технику дистилляции знаний, позволяющую агентам делиться идеями и паттернами между языками, способствуя более глубокому пониманию концепций программирования.
- Метрика оценки синергии: разрабатываем новую метрику для количественной оценки степени обмена знаниями и синергии между разными языками программирования в модели.
- Адаптивная генерация инструкций: Платформа включает механизм для динамической генерации новых инструкций на основе выявленных пробелов в знаниях между языками.
Оценка качества инструкционных данных на основе чек-листа
Для полной оценки качества созданной пары инструкций вводится несколько критериев оценки для каждого образца:
- Согласованность вопроса и ответа: Насколько вопрос и ответ логичны и корректны для дообучения.
- Релевантность вопроса и ответа: Насколько вопрос и ответ связаны с компьютерной областью.
- Сложность вопроса и ответа: Насколько вопрос и ответ достаточно сложны.
- Наличие кода: Присутствует ли код в вопросе или ответе.
- Корректность кода: Оценка отсутствия синтаксических ошибок и логических недочётов в коде.
- Соблюдение лучших практик: Учитываются ли такие факторы, как правильное именование переменных, отступы и соблюдение стандартов.
- Читаемость кода: Насколько код понятен и хорошо структурирован. Оценивается использование осмысленных имён переменных, комментариев и последовательного стиля кодирования.
- Комментарии в коде: Наличие и полезность комментариев для объяснения функциональности кода.
- Лёгкость обучения: Определение образовательной ценности для студента, изучающего базовые концепции программирования.
После получения всех оценок (s₁, ..., sₙ) финальная оценка вычисляется как: s = w₁s₁ + ... + wₙsₙ, где (w₁, ..., wₙ) — заранее определённые веса.
Мультиязыковая пессочница для проверки кода
Для дополнительной проверки корректности синтаксиса кода используем статическую проверку кода для всех извлечённых фрагментов на разных языках программирования (например, Python, Java, C++) преобразуем фрагменты кода в дерево абстрактного синтаксиса (AST) и отфильтровываем те фрагменты, в которых обнаружены ошибки разбора.
Была создана мультиязыковая пессочница, поддерживающая статическую проверку кода для основных языков программирования. Кроме того, мультиязыковая пессочница — это комплексная платформа, предназначенная для валидации фрагментов кода на нескольких языках программирования. Она автоматизирует процесс генерации релевантных юнит-тестов на основе языково-специфичных образцов и оценивает, могут ли предоставленные фрагменты кода успешно пройти эти тесты. Особенно важно, что в пессочницу поступают только самодостаточные фрагменты кода (например, задачи по алгоритмам).
Мультиязыковая пессочница для проверки состоит из пяти основных частей:
- Модуль поддержки языков:
- Обеспечивает поддержку нескольких языков (например, Python, Java, C++, JavaScript).
- Поддерживает языково-специфичные среды разбора и исполнения.
- Осуществляет синтаксический и семантический анализ для каждого поддерживаемого языка.
- Репозиторий образцов кода:
- Хранит разнообразную коллекцию образцов кода для каждого поддерживаемого языка.
- Организует образцы по языку, уровню сложности и концепциям программирования.
- Регулярно обновляется и курируется экспертами по языкам.
- Генератор юнит-тестов:
- Анализирует образцы кода для выявления ключевых функций и пограничных случаев.
- Автоматически генерирует юнит-тесты на основе ожидаемого поведения.
- Создаёт тестовые случаи, охватывающие различные сценарии ввода и ожидаемые результаты.
- Движок исполнения кода:
- Предоставляет изолированные среды для безопасного исполнения фрагментов кода.
- Поддерживает параллельное исполнение нескольких тестовых случаев.
- Управляет распределением ресурсов и механизмами тайм-аута.
- Анализатор результатов:
- Сравнивает результат исполнения фрагментов кода с ожидаемыми результатами юнит-тестов.
- Генерирует детальные отчёты об успехах и неудачах тестовых случаев.
- Предлагает рекомендации по улучшению на основе неудачных тестов.
Стратегия процесса обучения
Постепенное уточнение (Coarse-to-fine Fine-tuning)
На первом этапе синтезировали десятки миллионов низкокачественных, но разнообразных инструкционных образцов для дообучения базовой модели. На втором этапе используем миллионы высококачественных инструкционных образцов, чтобы улучшить производительность модели с помощью метода отбора (rejection sampling) и контролируемого дообучения (supervised fine-tuning). Для одного и того же запроса используем LLM для генерации нескольких кандидатов, а затем применяем LLM для оценки и выбора лучшего из них для контролируемого дообучения.
Смешанное обучение (Mixed Tuning)
Поскольку большинство инструкционных данных имеют короткую длину, формируем пары инструкций в формате FIM (Fill-in-the-Middle), чтобы сохранить способность базовой модели работать с длинными контекстами. Вдохновившись правилами синтаксиса языков программирования и привычками пользователей в реальных сценариях, была использована библиотека tree-sitter-languages для разбора фрагментов кода и извлечения базовых логических блоков, которые затем используются в качестве центрального кода для заполнения.
Например, дерево абстрактного синтаксиса (AST) представляет структуру кода на Python в виде дерева, где каждый узел отражает конструкцию исходного кода. Иерархическая природа дерева отражает синтаксическую вложенность конструкций в коде и включает различные элементы, такие как выражения, операторы и функции. Путем обхода и манипуляции с AST мы можем случайным образом извлекать узлы разных уровней и использовать контекст кода из того же файла, чтобы восстановить скрытые узлы.
В итоге мы оптимизируем инструкционную модель, используя большинство стандартных данных SFT и небольшую часть инструкционных образцов в формате FIM.
DPO - Оптимизация предпочтений для кода (Direct Preference Optimization for Code)
После получения модели SFT дополнительно выравниваем Qwen2.5-Coder с помощью автономной оптимизации предпочтений (DPO) (Rafailov et al., 2023). Учитывая, что обратная связь от человека требует значительных трудозатрат, используется мультиязыковая песочница для кода, чтобы предоставлять обратную связь на основе исполнения кода, а LLM — для оценки качества кода с точки зрения человека.
Для алгоритмических и самодостаточных фрагментов кода генерируются тестовые случаи, чтобы проверить корректность кода и использовать результаты исполнения в качестве обратной связи. Это касается таких языков, как Python, Java и других. Для более сложных фрагментов кода используется подход "LLM как судья" (Zheng et al., 2023), чтобы определить, какой фрагмент кода лучше.
Далее объединяются данные DPO для кода и общие данные для автономного обучения с использованием DPO.
Абстрактное синтаксическое дерево (AST, Abstract Syntax Tree) — это древовидная структура данных, представляющая синтаксическую структуру исходного кода программы без деталей, несущественных для семантики. Оно строится на этапе синтаксического анализа (парсинга) и используется компиляторами, интерпретаторами и инструментами для анализа и преобразования кода. В отличие от полного синтаксического дерева (parse tree), AST упрощает структуру, убирая вспомогательные элементы (например, скобки, точки с запятой), оставляя только логические конструкции языка.
Деконтаминация данных в Qwen Coder
Чтобы гарантировать, что Qwen2.5-Coder не показывает завышенные результаты из-за утечки данных тестового набора, провели деконтаминацию всех данных, включая как наборы для предварительного обучения, так и для дообучения. Исследователи удалили ключевые наборы данных, такие как HumanEval, MBPP, GSM8K и MATH. Фильтрация осуществлялась с использованием метода перекрытия 10-грамм: любые обучающие данные с перекрытием на уровне 10 слов с тестовыми данными были удалены.
Лирическое отступление о том, что такое AST
Как строится AST?
-
Лексический анализ (токенизация)
Исходный код разбивается на токены (лексемы): ключевые слова, операторы, идентификаторы, литералы.
Пример: Для кода if (x > 0) { y = 1; } токены: if, (, x, >, 0, ), {, y, =, 1, ;, }. -
Синтаксический анализ (парсинг)
Токены объединяются в структуру согласно грамматике языка. На этом этапе формируется синтаксическое дерево (parse tree), содержащее все детали грамматики (включая скобки, разделители). -
Преобразование в AST
Парсер упрощает parse tree, удаляя «шум» (например, скобки вокруг условия if), и оставляет только семантически значимые узлы. Это и есть AST.
Примеры AST
- Арифметическое выражение
Код:
2 + 3 * 4Синтаксическое дерево (parse tree):
program
|
expression
|
binary_expression
/ | \
operand '+' operand
| |
2 binary_expression
/ | \
operand '*' operand
| |
3 4AST:
BinaryExpression (+)
/ \
Literal(2) BinaryExpression (*)
/ \
Literal(3) Literal(4)Пояснение:
- В AST отражён приоритет операций: выполняется раньше +, поэтому узел является подузлом +.
- Узлы Literal хранят значения (2, 3, 4), а BinaryExpression — операторы (+, *).
- Скобки не указаны, так как в данном случае они не влияют на приоритет (в отличие от (2 + 3) * 4).
- Функция в JavaScript
Код:
function add(a, b) {
return a + b;
}AST (упрощённо):
FunctionDeclaration (name: "add")
|
├── Parameters
│ ├── Identifier (name: "a")
│ └── Identifier (name: "b")
│
└── Body (BlockStatement)
└── ReturnStatement
└── BinaryExpression (+)
├── Identifier (name: "a")
└── Identifier (name: "b")Пояснение:
- Узел FunctionDeclaration содержит имя функции, параметры и тело.
- Parameters — список идентификаторов a и b.
- ReturnStatement ссылается на выражение a + b, представленное как BinaryExpression.
- Нет узлов для {, }, ; — они не нужны для семантики.
- Условный оператор
Код:
if x > 0:
y = 1
else:
y = -1AST:
IfStatement
|
├── Condition: BinaryExpression (>)
│ ├── Identifier (x)
│ └── Literal (0)
│
├── ThenBlock: Assignment (y = 1)
│ ├── Identifier (y)
│ └── Literal (1)
│
└── ElseBlock: Assignment (y = -1)
├── Identifier (y)
└── Literal (-1)Пояснение:
- Узел IfStatement включает условие, блок then и блок else.
- Операторы присваивания представлены как Assignment с левой и правой частями.
- Отступы и ключевые слова (if, else) не отображаются — AST фокусируется на логике.
Отличие AST от синтаксического дерева (Parse Tree)
| Критерий | Parse Tree | AST |
|---|---|---|
| Детализация | Содержит все элементы грамматики (скобки, точки с запятой). | Удаляет «шум», оставляя только логические конструкции. |
| Размер | Больше из-за технических узлов. | Компактнее. |
| Цель | Проверка синтаксической корректности. | Анализ и преобразование кода. |
| Пример для a + b | Узел expression → term → a + b. | Прямой узел BinaryExpression (+). |
AST — это «каркас» программы, отражающий её логику без синтаксического «мусора». Он позволяет инструментам понимать код так, как это делает компилятор, и является ключевым элементом современных систем обработки программ. Понимание AST необходимо для разработки компиляторов, линтеров, форматтеров и других инструментов, работающих с исходным кодом.
Артефакты
| Artifact | Public link |
|---|---|
| Qwen2.5-Coder-0.5B | https://hf.co/Qwen/Qwen2.5-Coder-0.5B |
| Qwen2.5-Coder-1.5B | https://hf.co/Qwen/Qwen2.5-Coder-1.5B |
| Qwen2.5-Coder-3B | https://hf.co/Qwen/Qwen2.5-Coder-3B |
| Qwen2.5-Coder-7B | https://hf.co/Qwen/Qwen2.5-Coder-7B |
| Qwen2.5-Coder-14B | https://hf.co/Qwen/Qwen2.5-Coder-14B |
| Qwen2.5-Coder-32B | https://hf.co/Qwen/Qwen2.5-Coder-32B |
| CodeQwen1.5-7B | https://hf.co/Qwen/CodeQwen1.5-7B |
| StarCoder2-3B | https://hf.co/bigcode/starcoder2-3b |
| StarCoder2-7B | https://hf.co/bigcode/starcoder2-7b |
| StarCoder2-15B | https://hf.co/bigcode/starcoder2-15b |
| DS-Coder-1.3B-Base | https://hf.co/deepseek-ai/deepseek-coder-1.3b-base |
| DS-Coder-6.7B-Base | https://hf.co/deepseek-ai/deepseek-coder-6.7b-base |
| DS-Coder-33B-Base | https://hf.co/deepseek-ai/deepseek-coder-33b-base |
| DS-Coder-V2-Lite-Base | https://hf.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Base |
| DS-Coder-V2-Base | https://hf.co/deepseek-ai/DeepSeek-Coder-V2-Base |
Детальные метрики моделей на бенчмарках написания кода и остальные технические детали вы можете посмотреть в оригинальной статье https://arxiv.org/html/2409.12186v3
Хорошего вам кода!