На пути к большим моделям рассуждений: обзор Reinforced Reasoning with Large Language Models
На основе https://arxiv.org/html/2501.09686v3 Перевод обзора от 01.2025 (до выхода DeepSeek)
Язык давно рассматривается как важный инструмент для человеческого мышления. Прорыв в области больших языковых моделей (LLMs) вызвал значительный исследовательский интерес к использованию этих моделей для решения сложных задач рассуждения. Исследователи пошли дальше простого авторегрессионного генерирования токенов, введя концепцию "мысли" — последовательности токенов, представляющих промежуточные шаги в процессе рассуждения. Этот инновационный подход позволяет LLM имитировать сложные процессы человеческого мышления, такие как поиск по дереву и рефлексивное мышление. В последнее время появилось новое направление в обучении рассуждению, применяющее обучение с подкреплением (RL) для обучения LLM овладению процессами рассуждения. Этот подход позволяет автоматически генерировать высококачественные траектории рассуждений с помощью алгоритмов поиска методом проб и ошибок, значительно расширяя способности LLM к рассуждению за счет предоставления значительно большего объема обучающих данных. Кроме того, недавние исследования показывают, что побуждение LLM "думать" с использованием большего количества токенов во время тестового вывода может значительно повысить точность рассуждений. Таким образом, масштабирование на этапах обучения и тестирования в совокупности открывает новое направление исследований — путь к созданию больших моделей рассуждения. Введение серии o1 от OpenAI знаменует важную веху в этом направлении исследований. В этом обзоре мы представляем всесторонний анализ последних достижений в области рассуждений LLM. Мы начинаем с введения в основополагающие принципы LLM, а затем исследуем ключевые технические компоненты, способствующие развитию больших моделей рассуждения, с акцентом на автоматизированное построение данных, методы обучения рассуждению и масштабирование на этапе тестирования. Мы также анализируем популярные проекты с открытым исходным кодом, направленные на создание больших моделей рассуждения, и заканчиваем обсуждением открытых проблем и будущих направлений исследований.
Благодаря достижениям в области глубокого обучения и доступности веб-масштабных наборов данных, большие языковые модели (LLMs) стали трансформационной парадигмой на пути к искусственному общему интеллекту (AGI). Эти массивные модели ИИ обычно используют архитектуру Трансформер и предварительно обучаются на больших текстовых корпусах с задачей предсказания следующего токена [191]. Закон нейронного масштабирования демонстрирует, что их производительность значительно улучшается по мере увеличения размера модели и объема обучающих данных [59]. Более того, LLM также раскрывают замечательные возникающие способности, отсутствующие в меньших моделях [159], такие как контекстное обучение (few shot in context learning) [33], ролевое моделирование (role play) [124] и рассуждение по аналогии [157]. Эти способности позволяют LLM выходить за рамки задач обработки естественного языка и способствовать более широкому спектру задач, таких как генерация кода [41], робототехническое управление [3] и автономные агенты [28].
Среди этих способностей особое внимание как в академических кругах, так и в индустрии привлекло человекоподобное рассуждение, поскольку оно демонстрирует большой потенциал для LLM в обобщении сложных реальных проблем через абстрактное и логическое мышление. Значительным прорывом в этой области стала техника промптинга CoT Chain-of-Thoughts "цепочка мыслей" [160], которая может вызывать пошаговые процессы человекообразного рассуждения во время инференса без дополнительного обучения. Такие интуитивные техники промтинга доказали свою эффективность в значительном улучшении точности рассуждений предварительно обученных LLM, что также привело к разработке более продвинутых техник промптинга, таких как "дерево мыслей" [172]. Эти подходы вводят концепцию "мысли" как последовательности токенов, представляющих промежуточные шаги в процессе человекообразного рассуждения. Включая такие промежуточные шаги, рассуждения LLM выходят за рамки простого авторегрессионного генерирования токенов, позволяя использовать более сложные когнитивные архитектуры, такие как поиск по дереву [172] и рефлексивное рассуждение [180].
В последнее время наблюдается значительная тенденция в исследованиях, направленных на обучение рассуждению [103], которая стремится обучить LLM овладению процессами человекообразного рассуждения. Основной проблемой в этом направлении исследований является нехватка обучающих данных. Аннотирование человеком часто бывает чрезвычайно дорогим, особенно для пошаговых траекторий рассуждения, которые доказали свою эффективность в обучении рассуждению LLM [75]. Для решения этой проблемы недавние исследования перешли от аннотирования человеком к алгоритмам поиска на основе LLM. Эти подходы используют внешнюю верификацию для задач рассуждения, чтобы автоматически генерировать точные траектории рассуждения через поиск методом проб и ошибок [85]. Более того, исследователи предложили обучать модели вознаграждения процессов (Process Reward Models - PRMs) на этих траекториях рассуждения [183]. PRMs могут предоставлять плотные, пошаговые вознаграждения, которые способствуют обучению с подкреплением для рассуждений LLM. Эти методы в совокупности уменьшают зависимость от данных аннотирования человеком и создают "усиленный цикл" для улучшения рассуждений LLM, эффективно интегрируя "поиск" и "обучение", два метода, которые могут бесконечно масштабироваться, как предсказал Ричард Саттон [139]. Таким образом, эта новая парадигма позволяет масштабировать способности LLM к рассуждению с увеличением вычислительных мощностей на этапе обучения, прокладывая путь к более продвинутым моделям рассуждения.
Более того, недавние исследования показывают, что увеличение вычислительных мощностей на этапе тестирования (инференс) также может улучшить точность рассуждений LLM. В частности, PRMs могут использоваться для руководства LLM в оценке и поиске среди промежуточных "мыслей" [134], что побуждает LLM генерировать обдуманные шаги рассуждения во время вычислений на этапе тестирования и повышает точность рассуждений. Этот подход приводит к закону масштабирования на этапе тестирования, который предсказывает, что использование большего количества токенов для обдуманного рассуждения на этапе тестирования может улучшить точность [103]. Таким образом, масштабирование на этапе обучения, управляемое обучением с подкреплением, и масштабирование на этапе тестирования, основанное на поиске, в совокупности показывают многообещающее направление исследований для полного раскрытия способностей LLM к рассуждению, то есть путь к большим моделям рассуждения. Важной вехой в этом направлении исследований является серия o1 от OpenAI [194], которая демонстрирует эффективность этого подхода и отражает видение OpenAI перехода LLM от разговорного ИИ (уровень 1) к более мощному ИИ рассуждений (уровень 2) в пятиступенчатой дорожной карте на пути к AGI [36]. Несколько проектов с открытым исходным кодом, такие как OpenR [145], LLaMA-Berry [185] и Journey Learning [110], посвящены воспроизведению сильных способностей рассуждения OpenAI o1, предоставляя ценные идеи для разработки больших моделей рассуждения.
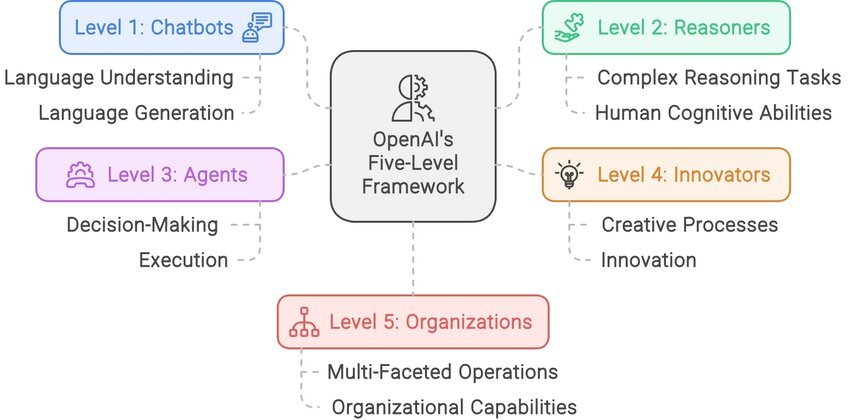
Рис.1. Open AI's Five Level Framework
В этом обзоре представлен анализ недавних исследовательских усилий в прогрессе к большим моделям рассуждения. Раздел 2 предлагает краткое введение в основы рассуждений LLM. В последующих трех разделах рассматриваются ключевые технические компоненты, способствующие развитию больших моделей рассуждения. В частности, Раздел 3 фокусируется на построении обучающих данных, подчеркивая переход от аннотирования человеком к автоматизированному поиску на основе LLM. Раздел 4 рассматривает методы обучения с подкреплением, которые являются ключевыми для масштабирования способностей LLM к рассуждению с увеличением вычислительных мощностей на этапе обучения, в то время как Раздел 5 обсуждает масштабирование на этапе тестирования с особым акцентом на поиск, управляемый PRM. В Разделе 6 анализируется развитие серии o1 от OpenAI и других проектов с открытым исходным кодом, исследуя путь к большим моделям рассуждения. Раздел 7 суммирует дополнительные техники улучшения на этапе тестирования, а Раздел 8 рассматривает бенчмарки рассуждений. Завершается обзор обсуждением открытых проблем и будущих направлений исследований.
2. Общая информация
2.1 Предобучение
Эффективное предобучение является ключевым этапом в развитии способностей к рассуждению у больших языковых моделей (LLM). Прежде чем обсуждать предобучение для рассуждений LLM, рассмотрим основной процесс общего предобучения LLM. В ходе предобучения LLM не только приобретают базовые лингвистические знания, но и получают разнообразные знания о мире, закладывая прочную основу для появления продвинутых способностей и эффективного соответствия ценностям [191]. Обычно предобучение LLM опирается на высококачественные текстовые корпуса [35, 168], включая обширные коллекции веб-контента, книг, кода и других типов данных. Используя эти богатые текстовые корпуса, LLM строятся на архитектуре трансформеров и обучаются с задачей предсказания следующего токена. После предобучения LLM обычно демонстрируют исключительные способности к контекстному пониманию (in context learning) [14], что позволяет им генерировать связный текст и давать точные ответы на широкий спектр вопросов, используя свою обширную базу знаний. Важно отметить, что этап предобучения играет ключевую роль в развитии способностей LLM к рассуждению. Например, исследования [160] показали, что наборы данных, богатые кодом и математическим контентом, служат ключевой основой для развития устойчивых навыков рассуждения. Следуя этим наблюдениям, вновь разработанные LLM [1] начинают использовать тщательно разработанные синтетические данные для улучшения способностей LLM к рассуждению. Во время предобучения критическим вызовом является балансирование пропорции кода и математических данных с общими текстовыми корпусами для поддержания сильных общих лингвистических способностей при раскрытии потенциала LLM к рассуждению.
2.2 Тонкая настройка (supervised fine tuning - SFT)
Хотя предобучение позволяет LLM демонстрировать способности к рассуждению через контекстное обучение, методы тонкой настройки широко применяются для достижения zero-shot режима и улучшения способностей к рассуждению у LLM. Здесь мы сначала описываем основной процесс тонкой настройки, а затем исследуем его потенциал для улучшения способностей к рассуждению. Как описано в [104], после этапа предобучения LLM вступают в фазу контролируемой тонкой настройки (SFT), также известной как этап настройки инструкций. Основная цель этого этапа — уточнить стиль вывода модели, обеспечивая соответствие ее ответов потребностям человека и реальным приложениям. Это достигается за счет обучения на разнообразных наборах данных с инструкциями, отражающими широкий спектр повседневных человеческих взаимодействий, обычно создаваемых с помощью обширной и тщательно подобранной ручной аннотации и уточнения [195]. С появлением ChatGPT появились новые методы генерации разнообразных наборов данных с инструкциями. К ним относятся техники, которые непосредственно дистиллируют данные из мощных LLM [153, 167], и автоматизированные подходы для крупномасштабного построения наборов данных из существующих корпусов [158, 32]. Используя эти хорошо подготовленные наборы данных для настройки инструкций, процесс тонкой настройки продолжает использовать цель предсказания следующего токена, аналогично предобучению. Однако, в отличие от предобучения, тонкая настройка специально рассчитывает loss только для ответов, обычно игнорируя loss для промптов и вопросов. Кроме того, включение наборов данных, содержащих примеры рассуждений по цепочке мыслей (CoT) [160] и решения математических задач, показало значительное улучшение способностей LLM к рассуждению. Следуя общей практике, большинство текущих подходов используют дистилляцию данных из продвинутых больших моделей рассуждения, за которыми следует тонкая настройка для улучшения способностей LLM к рассуждению для получения окончательных больших моделей рассуждения.
2.3 RL Alignment - Выравнивание через обучение с подкреплением
Полное использование прямой дистилляции данных из продвинутых больших моделей рассуждения ограничивает потенциал новых LLM. Более перспективный подход заключается в использовании обучения с подкреплением для построения данных и обучения моделей, что точно соответствует финальной стадии выравнивания в общем обучении LLM. В общем обучении LLM фаза выравнивания обычно включает методы, такие как обучение с подкреплением на основе обратной связи от человека (RLHF) [104], чтобы направлять модель к генерации контента, соответствующего критериям полезности, безвредности и честности. Цель этой фазы — улучшить безопасность и управляемость LLM в реальности. По сравнению с предыдущей фазой SFT, этот этап обычно включает большое количество тщательно подобранных, вручную размеченных данных ранжирования, чтобы точно отражать человеческие предпочтения [35, 168]. Эти данные включают не только правильные демонстрации, но и нежелательные случаи, которых следует избегать. Стандартный RLHF обычно включает модель SFT, модель вознаграждения и выровненную модель, которые итеративно оптимизируются с помощью методов, таких как PPO [121]. Из-за высоких требований к данным и затрат на обучение стандартного RLHF были предложены методы, такие как прямая оптимизация предпочтений (DPO) [112], чтобы уменьшить зависимость от явных моделей вознаграждения. В DPO loss предпочтений определяется как функция политики для прямого руководства оптимизацией модели. Учитывая многоэтапную природу и сложность задач рассуждения, пост-обучение на основе выравнивания стало последним и наиболее критическим шагом в стимулировании способностей LLM к рассуждению. Путем тщательного разложения процесса рассуждения и постепенной обратной связи с моделью различные методы самообучения [45, 64, 183] на основе обучения с подкреплением и обучения предпочтениям достигли значительного успеха.
2.4 Промпты для продвинутого рассуждения
Человекоподобное рассуждение является одной из самых важных способностей, которые проявляются в LLM с достаточно большими параметрами модели [157]. Хотя zero-shot reasoning может оставаться ненадежным для некоторых задач, исследователи обнаружили различные техники промтов для улучшения этих способностей. Эти техники можно широко разделить на три основных подхода: пошаговое рассуждение (step-by-step reasoning), многопутевое исследование (multi-path exploration) и методы на основе декомпозиции.
Подход пошагового рассуждения, примером которого является подсказка "Цепочка мыслей" [160], демонстрирует, что явное показывание промежуточных шагов рассуждения значительно улучшает способности к решению проблем. Даже простые подсказки, такие как "Давайте думать шаг за шагом", могут эффективно направлять процесс рассуждения [62]. Этот подход был дополнительно уточнен с помощью Self-Consistency [153], который генерирует несколько путей рассуждения для достижения более надежных выводов, и Auto-CoT [189], который автоматизирует генерацию эффективных цепочек рассуждения.
Подходы многопутевого исследования выходят за рамки линейного рассуждения, рассматривая несколько потенциальных путей решения одновременно. "Дерево мыслей" [172] организует альтернативные пути рассуждения в древовидную структуру, позволяя систематически исследовать различные стратегии решения. "Граф мыслей" [11] дополнительно обобщает это до графовой структуры, позволяя более гибкие паттерны рассуждения и возможности возврата. ReAct [173] обогащает эту парадигму, чередуя рассуждения с шагами действий, что позволяет более динамично взаимодействовать с внешними средами.
Для сложных проблем методы на основе декомпозиции оказались особенно эффективными. "Least-to-Most Prompting" [196] и "Algorithm of Thoughts" [122] систематически разбивают сложные проблемы на управляемые компоненты, в то время как "Plan-and-Solve" [147] предоставляет стратегическое руководство для решения этих подзадач. Эти методы особенно ценны при работе с задачами, требующими нескольких шагов или различных уровней анализа.
Эти обширные способности к рассуждению, усиленные структурированными стратегиями промтинга, оказались особенно эффективными для задач, требующих тщательного анализа и систематического мышления, позволяя LLM выполнять широкий спектр сложных социально значимых задач. Успех этих методов демонстрирует, что хотя LLM обладают врожденными способностями к рассуждению, их полный потенциал может быть раскрыт через тщательное руководство и структуру в процессе промтинга.
2.5 Агентный рабочий процесс
Помимо способностей следовать инструкциям и контекстного обучения LLM, исследователи начинают разрабатывать агентные рабочие процессы, которые программируют "паттерны мышления (thinking patterns)" LLM [137]. Такие агентные рабочие процессы позволяют исследователям улучшать способности LLM к рассуждению без дополнительного обучения, но часто требуют больше вычислительных ресурсов на этапе тестирования. Контекстное обучение [33, 25] — это способность улучшать специфическую для задачи производительность LLM, просто предоставляя несколько контекстных демонстраций, что позволяет LLM эффективно обобщать на невиданные проблемы без вычислительно затратного обучения [14]. Хотя происхождение таких способностей остается в значительной степени дискуссионным, недавние исследования предполагают, что контекстное обучение улучшает производительность LLM, позволяя им захватывать пространство меток, распределение входного текста и желаемый формат ответов [97]. Такие желательные особенности позволили исследователям адаптировать LLM общего назначения к разнообразным сценариям задач, таким как моделирование перспективы определенных демографических групп через контекстную ролевую игру [22]. Недавние исследования показывают, что эффективный агентный рабочий процесс может значительно улучшить способности LLM к моделированию человеческого поведения [105, 127], взаимодействию человека с LLM [89] и совместному решению задач [107]. Способность программировать LLM с агентным рабочим процессом закладывает основу для улучшения способностей LLM к рассуждению с помощью сложной когнитивной архитектуры.
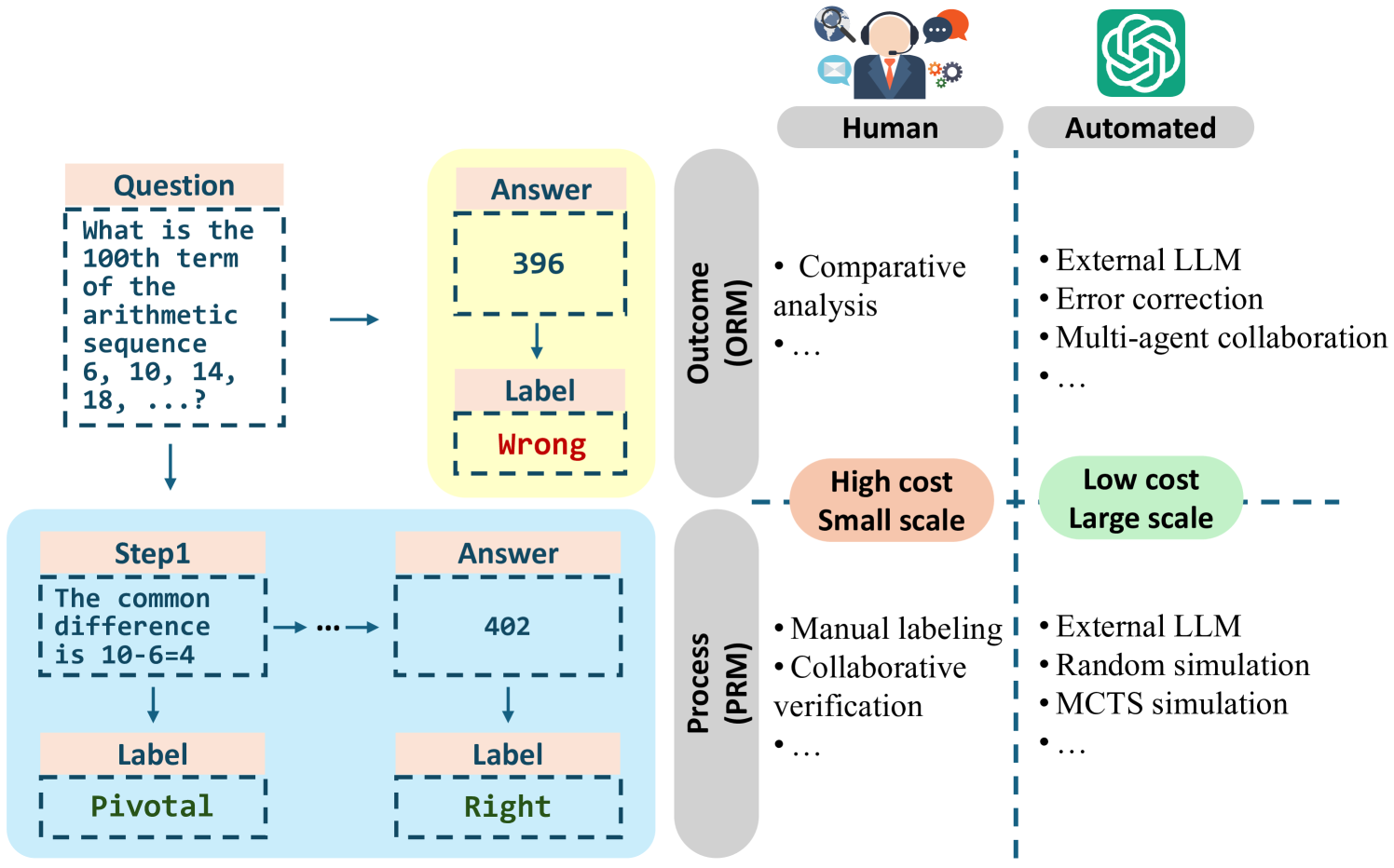
Рис.2. Иллюстрация различных парадигм для аннотирования данных рассуждений LLM.
3 Подготовка данных. От ручной разметки к использованию LLM (Data Construction: from Human Annotation to LLM Automation)
Создание крупномасштабных, высококачественных наборов данных для рассуждений имеет решающее значение для улучшения способностей больших языковых моделей (LLM) к рассуждению. Однако эта задача представляет значительные трудности из-за высокой стоимости. Как показано на рисунке 1, аннотирование человеком широко считается высококачественным, но оно чрезвычайно дорогое и сложное для масштабирования. В свою очередь, автоматизация процесса аннотирования с помощью LLM предлагает более экономически эффективную альтернативу, но сталкивается с проблемой ограниченной валидации, особенно для пошаговых процессов рассуждения. В этом разделе мы рассматриваем последние исследовательские усилия в этой области (обобщено в таблице 1), подчеркивая переход от аннотирования человеком к автоматизации с помощью LLM.
| Method | Label | Paper | Year | Task | Brief Description |
|---|---|---|---|---|---|
| Human Annotation | Outcome | [98] | 2024 | Text classification, Semantic analysis | Voting annotation |
| Human Annotation | Process | [104] | 2022 | Preference Alignment | Preference ranking |
| Human Annotation | Process | [75] | 2023 | Mathematical reasoning | Stepwise annotation |
| Human-LLM Collaboration | Outcome | [42] | 2023 | Semantic analysis | Human correction |
| Human-LLM Collaboration | Outcome | [152] | 2024 | Text classification | Human correction |
| Human-LLM Collaboration | Outcome | [74] | 2023 | Text classification, Semantic analysis | Task allocation, Uncertainty assessment |
| LLM Automation | Outcome | [106] | 2020 | Commonsense reasoning | Text extraction |
| LLM Automation | Outcome | [120] | 2024 | Tool use | Trial and error |
| LLM Automation | Outcome | [65] | 2024 | Embodied tasks | Synthetic augmentation |
| LLM Automation | Outcome | [109] | 2024 | Commonsense reasoning, Domain knowledge reasoning | Multi-agent collaboration |
| LLM Automation | Process | [84] | 2023 | Mathematical reasoning | Stronger LLM |
| LLM Automation | Process | [148] | 2024 | Mathematical reasoning | Monte Carlo simulation |
| LLM Automation | Process | [156] | 2024 | Mathematical reasoning, Programming | Monte Carlo simulation |
| LLM Automation | Process | [85] | 2024 | Mathematical reasoning | MCTS simulation |
| LLM Automation with feedback | Outcome | [70] | 2024 | Text classification, Mathematical reasoning, Domain knowledge reasoning | Self-refining |
| LLM Automation with feedback | Outcome | [135] | 2024 | Embodied tasks | Contrastive learning |
| LLM Automation with feedback | Process | [183] | 2024 | Mathematical reasoning, Domain knowledge reasoning | MCTS simulation, Self-refining |
Таблица 1: Построение обучающих данных для рассуждающих LLM.
3.1 Аннотирование человеком
Роль аннотирования человеком в создании наборов данных для больших языковых моделей (LLM) является неоценимой. Аннотаторы-люди характеризуются своей тщательностью, терпением и точностью, а также своей адаптивностью к новым сценариям и способностью эффективно обрабатывать неоднозначные данные [98]. Чжоу и др. [195] демонстрируют, что даже с минимальным количеством аннотированных человеком данных модели могут достигать высокой производительности, подчеркивая критическую роль тщательно подобранных аннотаций в эффективности модели. Данные, аннотированные человеком, играют ключевую роль в улучшении способностей к рассуждению больших языковых моделей. В контексте обучения с подкреплением на основе обратной связи от человека (RLHF) [104], данные предпочтений от аннотаторов-людей позволяют LLM, изначально обученным на общих текстовых корпусах, соответствовать сложным человеческим ценностям и этическим соображениям. Этот обобщаемый подход к аннотированию помогает в тонкой настройке моделей для конкретных задач. Основываясь на этом фундаменте, Лайтман и др. [75] продемонстрировали эффективность использования аннотаторов-людей для оценки качества рассуждения на каждом этапе процессов математического рассуждения, значительно улучшая точность рассуждений LLM. Это подчеркивает, как аннотирование человеком может преодолеть разрыв между общими обучающими данными и специфическими для домена задачами, такими как сложные задачи рассуждения.
Улучшение способностей к рассуждению в LLM требует супервизии процесса, где аннотаторы-люди руководят каждым шагом процесса рассуждения [75]. Однако такая супервизия требует обширных данных, аннотированных человеком, что делает ее ресурсоемкой и неустойчивой. Учитывая, что обучение LLM обычно требует терабайтов данных, объем которых критичен для производительности модели, создание наборов данных исключительно через ручное аннотирование становится все более непрактичным. Это подчеркивает необходимость альтернативных подходов для улучшения рассуждения без исключительной зависимости от аннотирования человеком. Одним из перспективных подходов является сотрудничество между людьми и LLM для аннотирования, где LLM используются для ускорения процесса при сохранении высокого качества аннотаций, созданных человеком. Конкретно, процесс аннотирования можно разделить на два этапа: этап предварительного аннотирования и этап уточнения. На этапе предварительного аннотирования LLM могут быть использованы для выполнения начального раунда аннотаций, используя несколько предоставленных вручную примеров для быстрой и эффективной настройки [42, 61]. На этапе уточнения аннотаторы-люди могут оценивать качество аннотаций, созданных LLM, и сосредоточиться на исправлении только той части аннотаций, которая имеет низкое качество [61, 152, 96, 42]. Для обеспечения масштабируемых процессов аннотирования последние работы все больше сосредоточены на том, как максимизировать автоматизацию, обеспечивая при этом качество данных, тем самым уменьшая вовлеченность человека без ущерба для точности аннотаций.
3.2 Автоматизированное аннотирование исходов с помощью LLM
Аннотирование данных — это сложная и ресурсоемкая задача, особенно в сценариях, требующих сложных операций, таких как фильтрация, идентификация, организация и реконструкция текстовых данных. Эти задачи часто бывают утомительными, трудоемкими и требуют значительных усилий человека, что делает их дорогостоящим узким местом в крупномасштабных усилиях по созданию данных [142, 31]. Для решения этих проблем использование LLM для аннотирования данных предоставляет экономически эффективную и эффективную альтернативу. С длиной контекстного окна, превышающей 100 000 токенов, LLM могут легко обрабатывать длинные тексты и большие объемы структурированных данных [2], справляясь с сложными требованиями аннотирования данных с замечательной эффективностью. Их сильные способности следовать инструкциям [187] позволяют им гибко адаптироваться к разнообразным и сложным сценариям аннотирования, достигая уровня качества, сравнимого с аннотаторами-людьми. Автоматизируя эти сложные задачи, LLM значительно сокращают зависимость от человеческого труда, оптимизируя процесс аннотирования и повышая общую производительность [181].
LLM способны выполнять широкий спектр задач автоматизированного аннотирования, начиная от простого извлечения вопросов и ответов [106] и заканчивая включением дополнительной целевой информации [161]. Без демонстраций человека LLM полагаются на свои мощные способности к рассуждению и контекстному обучению, чтобы самостоятельно решать более сложные задачи аннотирования. Например, Шик и др. [120] продемонстрировали, как LLM могут быть использованы для создания наборов данных для использования инструментов. Для каждого кандидата на позицию, которая может потребовать вызова API, LLM способны понимать логические связи в окружающем контексте, генерировать соответствующие вопросы и идентифицировать подходящий инструмент API для решения проблемы. Когда демонстрации человека доступны, LLM могут дополнительно улучшить свою производительность, имитируя паттерны и стратегии рассуждения, представленные в этих примерах. Для сложных задач демонстрации человека предоставляют высококачественные траектории — последовательности мыслей, наблюдений или действий, которые руководят LLM в воспроизведении процессов принятия решений человеком.
Существующие исследования показали, что даже LLM с нулевым обучением, руководствуясь агностическими к задаче подсказками на основе демонстраций человека, могут эффективно выполнять задачи аннотирования [65]. Более того, для задач, включающих высоко сложные и нюансированные траектории, LLM могут включать специализированные агенты, такие как Plan-Agent, Tool-Agent и Reflect-Agent, для решения различных аспектов процесса аннотирования, тем самым дополнительно улучшая их способность соответствовать человекообразному рассуждению и поведению [109]. Эти разнообразные способности естественным образом распространяются на задачи аннотирования исходов рассуждения, где LLM не только выводят основные логические структуры, но и систематически документируют промежуточные шаги рассуждения и связанные с ними выводы. Это позволяет создавать аннотированные наборы данных, которые захватывают не только конечные результаты, но и полные процессы рассуждения, ведущие к ним, предлагая более глубокие идеи для последующих приложений.
Помимо аннотирования с демонстрациями человека, LLM могут независимо улучшать свои способности к аннотированию через поиск с обратной связью, процесс, который включает итерационное улучшение за счет обучения в динамической среде. Неудачные данные могут рассматриваться как классическая форма обратной связи, служа ценной обратной связью для модели, чтобы идентифицировать слабые места и разрабатывать целевые корректировки. Путем самокоррекции ошибочных образцов и генерации уточненных обучающих данных LLM участвуют в цикле самосовершенствования, который укрепляет как их понимание, так и рассуждение [70]. Кроме того, LLM могут систематически анализировать причины своих ошибок, извлекая ключевые идеи и кодируя их как самообученные знания для руководства будущими задачами рассуждения [72]. Этот подход, основанный на обратной связи, также может включать сопоставление неудачных траекторий с успешными на основе сходства, позволяя использовать стратегии контрастного обучения для уточнения параметров модели. Через такие итерационные механизмы поиска и уточнения LLM не только исправляют ошибки, но и развивают более устойчивую способность к рассуждению, обеспечивая более глубокую обобщаемость и адаптируемость в сложных задачах [135].
3.3 Автоматизированное аннотирование процессов с помощью LLM
В сложных задачах рассуждения каждый шаг вывода модели может значительно влиять на конечный результат, что делает необходимым маркировать промежуточные решения как "правильные", "неправильные" или присваивать промежуточное вознаграждение, а именно аннотирование процесса. Однако ручная маркировка этих шагов является дорогостоящей и трудоемкой. Например, Лайтман и др. [75] вкладывают значительные усилия вручную для создания крупномасштабного набора данных с аннотациями процессов, то есть PRM800K, который удовлетворяет требованиям в обучении эффективной модели вознаграждения процессов (PRM) и значительно улучшает способность LLM к рассуждению. Поэтому все более необходимы автоматизированные методы для эффективного аннотирования процессов, обеспечивая масштабируемость и экономическую эффективность. Первоначальные автоматизированные подходы используют внешние более мощные LLM для аннотирования промежуточного процесса, сгенерированного меньшими LLM. Кроме того, метод на основе Монте-Карло уменьшает зависимость от внешних более мощных LLM и может использовать более слабые LLM для завершения аннотирования данных и, таким образом, обучать более мощные LLM посредством самоусиления.
Аннотирование с помощью более мощного LLM: В качестве прямого автоматизированного метода маркировки Луо и др. [84] предлагают использовать более мощную внешнюю модель для аннотирования промежуточных результатов процесса вывода генеративной модели. Вместо того чтобы полагаться на ручное аннотирование, этот метод использует предварительно обученную высокопроизводительную модель, такую как серия GPT, для оценки каждого сгенерированного шага. Используя возможности более мощной внешней модели, этот подход улучшает как точность, так и масштабируемость процесса маркировки, делая его более осуществимым для крупномасштабных задач. Однако основным ограничением этого подхода является его зависимость от высокоспособной внешней модели, что означает, что производительность процесса маркировки в конечном итоге ограничена возможностями используемой внешней модели.
Аннотирование с помощью симуляции Монте-Карло: Чтобы уменьшить зависимость от мощных внешних моделей, Ван и др. [148] и Ван и др. [156] предлагают улучшенный метод, который избегает прямого оценивания промежуточных шагов. Вместо этого их подходы используют внешнюю модель для продолжения рассуждения на несколько шагов от данного промежуточного вывода и случайно повторяют этот процесс симуляции несколько раз. Качество промежуточного шага затем оценивается на основе среднего результата этих расширенных выводов. Этот метод Монте-Карло показал многообещающие результаты в таких задачах, как решение математических проблем и генерация кода.
Аннотирование с помощью симуляции поиска по дереву: Подход использования многократной симуляции Монте-Карло с внешней моделью для оценки качества промежуточных шагов на основе средних результатов стал одним из наиболее широко используемых методов для автоматизированного аннотирования процессов. Чтобы еще больше повысить эффективность этого метода, Луо и др. [85] предлагают улучшение, заменяя повторяющиеся симуляции Монте-Карло на стратегию поиска по дереву Монте-Карло (Monte-Carlo Tree Search - MCTS). В этом улучшенном методе несколько листьев узлов, представляющих окончательные результаты вывода, генерируются из промежуточного шага с использованием MCTS. Качество промежуточного шага затем оценивается на основе средних результатов этих листьев узлов. По сравнению с случайными повторяющимися выводами, MCTS использует поиск по дереву для улучшения качества вывода, а также позволяет листьям узлов делиться высококачественными родительскими узлами, уменьшая вычислительные затраты и повышая эффективность. Этот метод продемонстрировал превосходную производительность в решении математических задач, превосходя аннотации человека.
Шаг вперед от симуляции на основе MCTS, Чжан и др. [183] вводят механизм самосовершенствования в аннотирование процессов. Они используют полученные аннотации процессов для обучения функции вознаграждения процесса (PRM), которая, в свою очередь, улучшает производительность большой языковой модели (LLM). Уточненная LLM затем используется для повторения симуляции на основе MCTS, генерируя аннотации более высокого качества. Этот итерационный процесс, включающий повторяющиеся циклы улучшения, приводит к прогрессивно улучшенным аннотациям процессов. Этот метод показал отличную производительность в нескольких задачах, включая решение математических задач, вопросы и ответы, и рассуждения в нескольких доменах, демонстрируя его эффективность в непрерывном уточнении и улучшении качества аннотаций через итерационное улучшение.
4. Обучение рассуждению: от SFT до Reinforcement Fine-tuning
Хотя предобученные модели демонстрируют отличные результаты в различных задачах, они часто сталкиваются с трудностями в сложных рассуждениях и согласовании выходных данных с человеческими ожиданиями. Тонкая настройка имеет решающее значение для преодоления этих ограничений, улучшая производительность модели в конкретных задачах и усиливая её способности к рассуждению. Изначально используется контролируемая тонкая настройка (SFT), где модели обучаются специфическим для задачи паттернам на основе размеченных наборов данных. Однако по мере усложнения задач рассуждения такие методы, как обучение с подкреплением (RL) и прямая оптимизация предпочтений (DPO), предлагают более эффективный подход, используя модели вознаграждения для более эффективного согласования выходных данных модели с человекообразным рассуждением, способствуя созданию более связных, ответственных и контекстуально осведомленных результатов.
4.1 Оптимизация предобученных LLM: контролируемая тонкая настройка
Контролируемая тонкая настройка — это техника обучения, которая уточняет возможности предобученных моделей для конкретных задач или доменов с использованием размеченных данных, сохраняя при этом понимание модели предобученных знаний. В то время как предобучение позволяет моделям изучать широкие, универсальные особенности из огромных объемов неструктурированных данных, тонкая настройка специализирует модель, знакомя её с меньшими, специфичными для задачи наборами данных с четкими соответствиями входных и выходных данных.
SFT является критическим шагом в улучшении способности LLM к рассуждению, позволяя их применение в последующих задачах, адаптируя их от универсальных систем к инструментам, специфичным для домена. Например, LLM, такие как GPT [111], BERT [30] и T5 [113], предобучаются на огромных объемах текстовых данных с использованием самообучения, что наделяет их широкими возможностями понимания и генерации языка. Однако их выходные данные не всегда соответствуют специфическим требованиям задачи. Без тонкой настройки LLM, как правило, плохо справляются с определенными задачами рассуждения, такими как подсчет объектов [182], понимание спутниковых данных [91] и ответы на инженерные вопросы [154]. С помощью SFT мы можем частично решить эти проблемы, уточняя выходные данные модели на основе размеченных, специфичных для задачи наборов данных.
Однако прямое применение SFT может не полностью раскрыть способности модели к рассуждению в желаемых доменах, особенно в задачах, требующих более сложного принятия решений или многоэтапного решения проблем. Введение техник цепочки мыслей (CoT) [160] революционизировало процесс SFT, обучая модель явно генерировать промежуточные шаги рассуждения перед получением ответа. С помощью SFT на основе CoT LLM поощряются к явной генерации промежуточных шагов рассуждения, что усиливает их способность решать задачи, требующие более структурированных и организованных мыслей. Например, ReasonBert [29] показывает, что тонкая настройка моделей с цепочками рассуждений значительно улучшает их производительность в таких задачах, как математические текстовые задачи и логическое рассуждение, за счет включения пошаговых процессов рассуждения. Другое ключевое исследование [80] изучает, как тонкая настройка моделей с рассуждением улучшает их интерпретируемость и уменьшает ошибки в сложных сценариях принятия решений за счет генерации более прозрачных, пошаговых процессов мышления. С помощью тонкой настройки с CoT модели не только улучшают свои окончательные ответы, но и усиливают способность "продумывать" проблему, предоставляя более четкие идеи о процессе рассуждения модели.
Несмотря на разнообразие методов и выдающуюся производительность SFT, она имеет несколько ограничений. Во-первых, SFT сильно зависит от высококачественных размеченных наборов данных, которые могут быть дорогими и трудоемкими для создания, особенно для нишевых доменов или задач, требующих экспертных аннотаций. Во-вторых, SFT может привести к катастрофическому забыванию, когда модель теряет часть своих предобученных универсальных знаний в процессе тонкой настройки, снижая её полезность для задач рассуждения вне домена тонкой настройки. Наконец, вычислительные затраты на тонкую настройку крупномасштабных моделей могут быть запретительными, даже с параметрически эффективными подходами, что создает проблемы для организаций с ограниченными ресурсами. Преодоление этих ограничений требует тщательной курации наборов данных, применения методов регуляризации и исследования альтернативных методов, таких как настройка подсказок или многозадачная тонкая настройка, для баланса между специализацией задачи и обобщением.
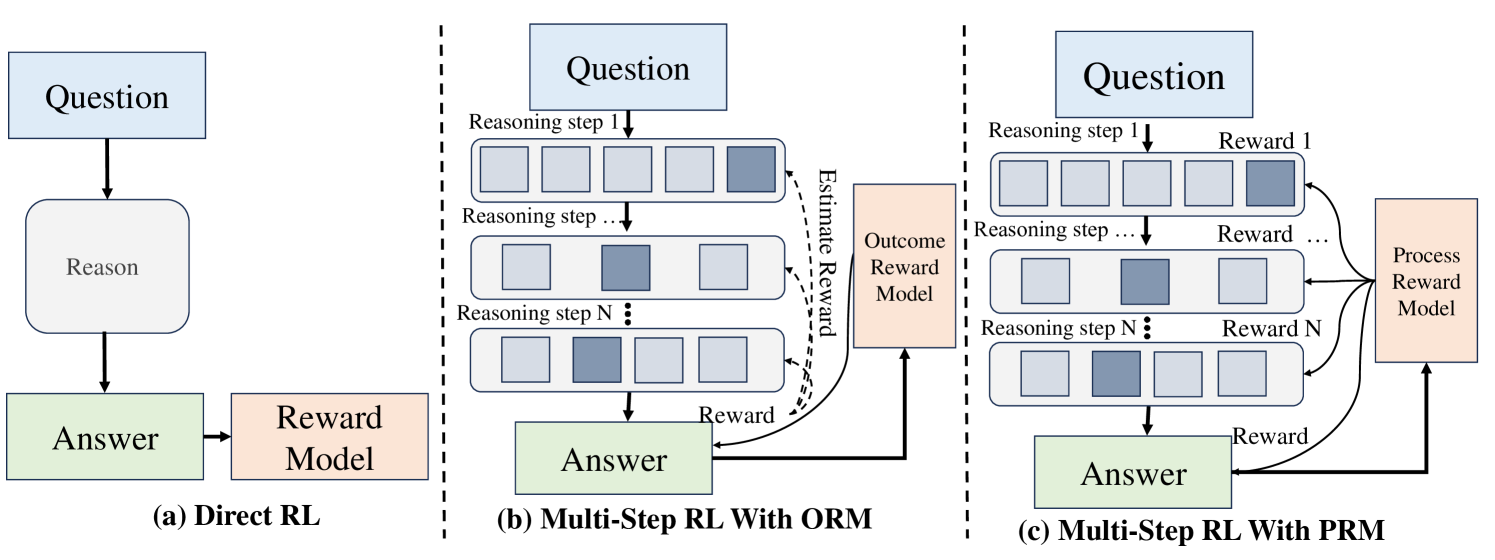
Рис.3. Reward models for Train-time Reinforcement of LLM Reasoning
4.2. Оптимизация предобученных LLM: обучение с подкреплением
Из-за высокой зависимости от дорогих высококачественных размеченных наборов данных и высоких вычислительных затрат на контролируемую тонкую настройку (SFT), обучение с подкреплением (RL) стало мощной альтернативной основой для обучения моделей овладению процессами рассуждения. В отличие от обучения с учителем, RL позволяет моделям учиться методом проб и ошибок с использованием сигналов вознаграждения, обнаруживая оптимальные стратегии для достижения конкретных целей. Как показано на рисунке 3 (a), модель принимает действие на основе своего текущего состояния и получает обратную связь в виде сигнала вознаграждения. Эта обратная связь направляет модель на обновление своих параметров с течением времени, оптимизируя кумулятивные вознаграждения.
Классическое обучение с подкреплением
Обучение с подкреплением стало критическим шагом в развитии LLM. В рамках RL параметры LLM обновляются на основе вознаграждений за их действия. Конкретно, функция ценности или Q-функция обновляется на основе обратной связи модели вознаграждения, приписывая заслугу за результат действия полностью его непосредственному эффекту. Этот подход упрощает структуру, делая её концептуально простой, одновременно улучшая способность модели эффективно реагировать. Два ключевых метода в настоящее время доминируют в обучении RL для LLM: обучение с подкреплением на основе обратной связи от человека (RLHF) и обучение с подкреплением на основе обратной связи от ИИ (RLAIF).
Оуян и др. [104] используют RLHF для согласования LLM с человеческими намерениями. Кроме того, путём тонкой настройки GPT-3 на демонстрациях и ранжировании, размеченных человеком, они разрабатывают модель вознаграждения, предсказывающую предпочтения аннотаторов-людей. Это эффективно согласовывает обученные LLM с человеческими предпочтениями, превосходя GPT-3 в рассуждении и следовании инструкциям, несмотря на меньший размер. Бай и др. [8] также используют RLHF для создания полезных и безопасных языковых моделей. Следуя принципам полезности, честности и безвредности, они тонко настраивают базовую модель, обучают модель предпочтений с использованием выборки отказов и итеративно уточняют её с помощью обратной связи от человека. Этот процесс создаёт ИИ-ассистентов, которые преуспевают в задачах обработки естественного языка и демонстрируют сильное этическое рассуждение.
Чтобы уменьшить зависимость от больших наборов данных, размеченных человеком, Бай и др. [9] предлагают Конституционный ИИ, основу для обучения ИИ-ассистентов быть полезными и безвредными с использованием принципов вместо дорогой обратной связи от человека. Процесс включает два этапа: обучение с учителем и RLAIF. На этапе обучения с учителем модель критикует и уточняет свои выходные данные на основе конституционных принципов, создавая набор данных для тонкой настройки. На этапе RLAIF модель генерирует самооценки для руководства обучением, обходя необходимость в данных, размеченных человеком, о вредности. Рамамурти и др. [114] сосредоточены на использовании RL для согласования LLM с человеческими предпочтениями. Они представляют RL4LMs, библиотеку для тонкой настройки на основе RL, и бенчмарк GRUE, который оценивает модели с использованием функций вознаграждения, отражающих человеческие предпочтения. Для решения проблем обучения они предлагают алгоритм оптимизации политики на естественном языке, который стабилизирует обучение, ограничивая выборку токенов. Эта работа предоставляет прочную основу для интеграции RL в тонкую настройку LLM для улучшения согласования и производительности.
Классическая оптимизация предпочтений
Классические методы RL полагаются на обучение модели вознаграждения для оценки выходных данных на основе человеческих предпочтений. В то время как DPO упрощает этот процесс, непосредственно используя данные предпочтений без необходимости в явной модели вознаграждения. Вместо оптимизации сложной функции вознаграждения, DPO использует парные сравнения предпочтений, то есть данные, указывающие, какой из двух выходных данных предпочитают люди. Этот прямой подход упрощает конвейер обучения, сохраняя преимущества согласования методов на основе RL, которые часто проще и эффективнее. Рафаилов и др. [112] представляют DPO, новую основу для согласования языковых моделей, которая непосредственно оптимизирует политику для согласования с человеческими предпочтениями через простую функцию потерь классификации. Параметризуя модель вознаграждения для вывода оптимальной политики в закрытой форме, DPO устраняет необходимость в выборке и обширной настройке гиперпараметров во время тонкой настройки. Эксперименты показывают, что DPO соответствует или превосходит методы RLHF, такие как PPO, в задачах, таких как контроль тональности, суммаризация и генерация диалогов, будучи более стабильным, вычислительно эффективным и эффективным в создании рассуждающих выходных данных. Амини и др. [4] предлагают оптимизацию прямых предпочтений со смещением (Direct Preference Optimization with an Offset - ODPO), расширение DPO для согласования языковых моделей с человеческими предпочтениями. ODPO улучшает DPO, учитывая степень предпочтения между ответами, а не рассматривая все пары предпочтений одинаково. Он вводит смещение в разнице правдоподобия между предпочтительными и непредпочтительными ответами, пропорциональное их разнице в качестве. Этот подход не только улучшает согласование, но и укрепляет способность модели к рассуждению, особенно в задачах, таких как контроль тональности, снижение токсичности и суммаризация. Эксперименты демонстрируют, что ODPO достигает лучшего согласования и ответственного поведения, особенно когда данные предпочтений ограничены.
В заключение, методы RL и DPO предлагают простой и эффективный способ развития способности к рассуждению у LLM. Фокусируясь на непосредственных вознаграждениях после каждого действия, эти методы также согласовывают модели с человеческими предпочтениями. Акцент на краткосрочной обратной связи упрощает процесс обучения, избегая сложностей распределения награды по длинным последовательностям. Этот упрощённый подход особенно хорошо подходит для приложений в реальном времени и задач, требующих чётких, кратких рассуждений, в конечном итоге укрепляя способность LLM предоставлять связные и этичные результаты.
4.3. Улучшение многоэтапного рассуждения с моделью вознаграждения за исход
Для сложных задач рассуждения, таких как решение математических задач, LLM необходимо выполнять многоэтапное рассуждение, подобное цепочке мыслей, чтобы в конечном итоге прийти к точному решению. В этих задачах обратная связь о вознаграждении обычно доступна только после завершения всех этапов рассуждения и получения окончательного решения. Как показано на рисунке 3 (b), это известно как модель вознаграждения за исход (Outcome Reward Model - ORM). В таких случаях ключом к улучшению способности LLM к рассуждению является различение правильности и важности промежуточных этапов рассуждения на основе вознаграждений за исходы.
Классическое обучение с подкреплением
ReFT [143] применяет метод PPO (Proximal Policy Optimization) [121] из RLHF [104] к задачам рассуждения. На основе модели вознаграждения за исход функция ценности в PPO способна выводить вклад промежуточных этапов рассуждения. По сравнению с контролируемой тонкой настройкой, ReFT способен изучать более разнообразные пути рассуждения, демонстрируя более сильные способности к обобщению в задачах рассуждения. Однако VinePPO [60] обнаруживает, что сеть ценностей, обученная с ORM в PPO, демонстрирует значительное смещение при идентификации ценности промежуточных этапов рассуждения, известная проблема в RL, называемая проблемой распределения заслуг. Чтобы решить эту проблему, VinePPO отказывается от сети ценностей в PPO и вместо этого использует метод выборки Монте-Карло для вычисления несмещённых оценок функции ценности. Экспериментальные результаты демонстрируют, что VinePPO последовательно превосходит типичный PPO в задачах математического рассуждения. Обучение критическим этапам плана (CPL) — это метод, предназначенный для улучшения обобщения LLM в задачах рассуждения путём поиска в высокоуровневых абстрактных планах [150]. CPL использует поиск по дереву Монте-Карло (MCTS) для исследования различных этапов планирования в многоэтапных задачах рассуждения и использует Step-APO для изучения критически важных этапов плана. Этот подход позволяет моделям изучать более разнообразные пути рассуждения, тем самым улучшая обобщение на различных задачах. Затем модель итеративно обучает политику и модели наград для дальнейшего улучшения производительности. На каждом этапе модель политики генерирует этапы плана и окончательные решения, в то время как модель награды оценивает качество промежуточных этапов. Обучающие данные, сгенерированные MCTS, используются для обновления как модели политики, так и модели награды.
DPO - Прямая оптимизация предпочтений
В задаче математического рассуждения прямое использование метода DPO (Direct Preference Optimization) [112] для оптимизации предпочтений даёт неоптимальные результаты из-за наличия длинных этапов рассуждения в данных предпочтений. Амини и др. [4] представили ODPO, который уточняет DPO, учитывая степень предпочтения между ответами вместо того, чтобы рассматривать все пары предпочтений как равные. ODPO достиг значительных улучшений по сравнению с DPO в задачах математического рассуждения.
В заключение, основная проблема обучения на основе вознаграждений за исход заключается в различении правильности и важности промежуточных этапов рассуждения. Текущие методы, основанные в основном на выборке Монте-Карло или поиске по дереву Монте-Карло, имеют преимущества в оценке значимости этих промежуточных этапов, хотя вычислительные затраты во время поиска остаются высокими. Существующие работы в основном сосредоточены на математических или других задачах рассуждения, где окончательные решения могут быть легко проверены. Эти методы могут быть расширены на более широкий спектр задач рассуждения, включая те, где решения трудно проверить. Потенциальный подход заключается в обучении модели вознаграждения на основе данных аннотаций человека и использовании её для оценки качества окончательного решения. На основе окончательного балла, предоставленного моделью вознаграждения, могут быть использованы методы выборки Монте-Карло или поиска для дальнейшего улучшения производительности.
4.4 Улучшение многоэтапного рассуждения с моделью вознаграждения за процесс
Обучение с подкреплением на основе модели вознаграждения за процесс (PRM) представляет собой значительное продвижение в рассуждении LLM, подчеркивая оценку промежуточных этапов, а не только фокусируясь на конечных результатах. Как показано на рисунке 3 (c), вознаграждение PRM распределяется по каждому этапу рассуждения, а не концентрируется на конечных результатах. Предоставляя нюансированную обратную связь на протяжении всей траектории рассуждения, PRM позволяет моделям оптимизировать поведение с большим соответствием человеческим предпочтениям и сложным требованиям задач. Этот подход важен для задач, включающих последовательное принятие решений, где промежуточные этапы или решения имеют значение для конечной цели. Мы исследуем эволюцию PRM и подчеркиваем их роль в улучшении рассуждения за счет предоставления вознаграждений на уровне этапов во время сложных задач.
Классическое обучение с подкреплением
Серия недавних работ применяет PRM для математического или логического рассуждения, поскольку основополагающая работа OpenAI [75] доказала важность вознаграждения за процесс. SELF-EXPLORE [55] использует PRM для улучшения математического рассуждения, выявляя и исправляя "первые ошибки", которые являются начальными неверными шагами в решении проблем. Вознаграждая шаги, которые исправляют такие ошибки, PRM позволяет самообучающуюся тонкую настройку без необходимости в обширных аннотациях человека. Эта модель достигает значительных улучшений в точности на математических бенчмарках, таких как GSM8K и MATH, используя детализированную обратную связь на уровне шагов. MATH-SHEPHERD [149] представляет собой структуру PRM, разработанную для пошаговой проверки и усиления в задачах математического рассуждения. Автоматизируя процесс супервизии с помощью методов, вдохновленных MCTS, MATH-SHEPHERD устраняет необходимость в аннотациях человека, обеспечивая при этом высокую точность в многоэтапном решении проблем. PRM используются для усиления логического прогресса и правильности, что приводит к улучшению производительности на бенчмарках, таких как GSM8K и MATH. DeepSeekMath интегрирует PRM через групповую относительную оптимизацию политики (GRPO) [128], алгоритм RL, который оптимизирует вознаграждения на уровне шагов. PRM используются для улучшения математического рассуждения и согласованности рассуждений в различных доменах. Фокусируясь на промежуточных этапах рассуждения, DeepSeekMath достигает передовых результатов на нескольких бенчмарках, демонстрируя мощь PRM в математических доменах. Масштабирование автоматизированных верификаторов процессов представляет собой вариант PRM, верификаторы преимущества процессов (PAV), для оценки прогресса на уровне шагов в решении проблем [123]. PAV используют супервизию на уровне шагов для улучшения эффективности и точности алгоритмов поиска и обучения с подкреплением. Фокусируясь на шагах, которые делают значимый прогресс в направлении правильного решения, PAV позволяют добиться существенных улучшений в эффективности выборки, вычислительной эффективности и точности рассуждения по сравнению с моделями вознаграждения за исход. Это демонстрирует важность детализированных вознаграждений за процесс в масштабировании способностей LLM к рассуждению.
Интерактивные модели вознаграждения за процесс
PRM также применяются к интерактивным задачам, таким как беседа и многоходовое отвечающее на вопросы. ArCHer использует иерархический подход RL с использованием PRM для обучения агентов для многоходовых задач с длинным горизонтом [198]. Он реализует двухслойную систему: функция ценности высокого уровня оценивает вознаграждения на уровне высказываний, в то время как PRM низкого уровня оптимизирует генерацию токен за токеном в каждом ходе. Эта иерархическая структура обеспечивает более эффективное распределение заслуг и позволяет для нюансированного обучения языковых моделей для обработки многоходовых взаимодействий и задач рассуждения. Использование PRM позволяет ArCHer эффективно масштабироваться, достигая значительных улучшений в эффективности выборки и производительности в задачах агентов. Многоходовое обучение с подкреплением на основе предпочтений обратной связи от человека [126] интегрирует PRM в многоходовое обучение с подкреплением для оптимизации долгосрочных целей с обратной связью от человека. Алгоритм многоходовой оптимизации предпочтений (MTPO) сравнивает целые многоходовые взаимодействия для генерации сигналов предпочтений, где PRM используются для назначения пошаговых вознаграждений. Это позволяет агентам LLM согласовывать поведение с долгосрочными целями, улучшая общую производительность в динамических многоходовых задачах, таких как беседы и стратегическое принятие решений.
DPO - Прямая оптимизация предпочтений
Несколько недавних исследований используют MCTS для оптимизации многоэтапных задач рассуждения через прямую оптимизацию предпочтений [165, 17, 183, 16]. Например, SVPO [17] использует MCTS для автоматической аннотации предпочтений на уровне шагов для многоэтапных задач рассуждения. С точки зрения обучения ранжированию, он обучает явную модель ценности для воспроизведения поведения неявной модели вознаграждения. Кроме того, SVPO интегрирует явную модель ценности с DPO, где модель ценности не только помогает модели политики находить более эффективные пути рассуждения, но и направляет обучение предпочтений. Однако эти работы в основном сосредоточены сначала на сборе данных предпочтений или обучении модели вознаграждения, а затем на выполнении оптимизации политики на основе статических данных и предобученной модели вознаграждения. Си и др. [165] продвинули эти подходы, интегрировав сбор данных и оптимизацию предпочтений политики в итеративный процесс. Этот метод можно рассматривать как онлайн-версию прямой оптимизации предпочтений, где обновлённая политика итеративно используется для сбора предпочтений через MCTS.
Эволюция многоэтапных методов RL для LLM отражает переход от разреженной обратной связи на основе исходов к детализированной супервизии, ориентированной на процесс. PRM теперь являются центральным элементом прогресса в способности LLM к рассуждению, предлагая нюансированные, пошаговые вознаграждения, которые приводят к существенным улучшениям в задачах рассуждения. Будущие исследования могут сосредоточиться на уточнении этих моделей и расширении их применимости в различных доменах задач.
4.5. Reinforcement Fine-tuning
Reinforcement Fine-tuning (RFT) [101] — это техника, недавно предложенная OpenAI для настройки экспертных LLM, адаптированных к конкретным вертикальным доменам. В настоящее время RFT остаётся частью исследовательской программы, и технические детали не были полностью раскрыты. Доступная информация предполагает, что RFT использует небольшое количество данных предпочтений, предоставленных пользователями, вместе с моделью оценщика для оценки выходных данных LLM. Эта техника позволяет итеративно оптимизировать способности LLM к многоэтапному рассуждению. В результате техника RFT может улучшить стратегию рассуждения LLM при решении подобных проблем в оптимизированных доменах.
Модель оценщика
RFT вводит концепцию модели оценщика для оценки выходных данных LLM. Учитывая, что обучение с подкреплением обычно требует модели вознаграждения для предоставления обратной связи, оценщик, вероятно, аналогичен модели вознаграждения, преобразуя текстовые входные данные (например, вопросы и ответы) в скалярные значения качества рассуждения. Это предполагает, что оценщик может действовать как модель вознаграждения, обученная на данных предпочтений, предоставленных пользователем, потенциально работая либо как модель вознаграждения за исход, либо как модель вознаграждения за процесс [76].
Эффективность данных
В живых сессиях OpenAI было упомянуто, что RFT может обеспечить обучение в новых доменах с использованием всего нескольких десятков данных предпочтений пользователей. Это предполагает, что RFT способствует исследованию разнообразных путей рассуждения для решения задач на основе ограниченных данных предпочтений. Такой подход демонстрирует замечательно высокую эффективность выборки, одновременно снижая риск переобучения [56].
Стабильность обучения
Стабильность обучения с подкреплением — это известная сложная проблема, которая представляет значительные вызовы для её более широкого применения. Вариации в случайных начальных условиях или изменения определённых гиперпараметров могут значительно повлиять на результаты обучения RL. В контексте проекта RFT, OpenAI объявила о планах сделать эту технологию доступной для общественности через API, позволяя пользователям тонко настраивать доменно-специфичные экспертные модели с использованием своих собственных данных. Это заявление потенциально указывает на то, что RFT достиг уровня стабильности, достаточного для надёжной тонкой настройки языковых моделей с использованием методов RL.
5. Масштабирование на этапе тестирования: от цепочек мыслей к поиску с руководством PRM
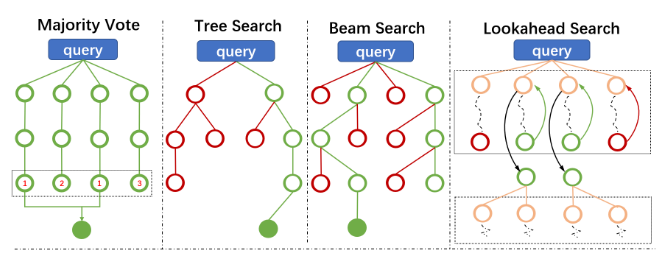
Рис.4. Diagrams of Different Search Algorithms for Test-time Reasoning Enhancement
5.1. Стимулирование осознанного мышления с помощью подсказок
Помимо оптимизации на этапе обучения с использованием таких методов, как обучение с подкреплением, исследователи обнаружили, что методы подсказок на этапе тестирования, такие как "Цепочка мыслей" и "Дерево мыслей", могут дополнительно улучшить возможности языковых моделей [160, 153]. В то время как простое требование от моделей прямых ответов часто дает неоптимальные результаты, руководство ими через явные процессы рассуждения на этапе тестирования значительно улучшает их производительность [62]. Эти стратегии подсказок показали замечательную эффективность в различных областях, от математических рассуждений до сложных задач принятия решений [173, 196]. Появление структурированных методов подсказок, таких как ReAct и "Подсказки от простого к сложному", продемонстрировало, что языковые модели могут извлечь выгоду из явного руководства в организации своих мыслительных процессов, что приводит к более надежным и интерпретируемым результатам [189]. Хотя эти подходы обычно увеличивают потребление токенов и вычислительные накладные расходы, они предоставляют убедительное дополнение к методам этапа обучения, улучшая способности языковых моделей к рассуждению и точность решений без необходимости изменения параметров модели [172, 11]. Это указывает на перспективное направление для улучшения производительности языковых моделей через сложные вмешательства на этапе тестирования, а не только за счет изменений в архитектуре модели или обучении.
5.2. Поиск с руководством PRM
Как упоминалось ранее, PRM знаменует значительный сдвиг от разреженной обратной связи на основе результатов к детальному процессуальному надзору. Более того, важно, что PRM также может использоваться на этапе тестирования, где он может дополнительно усилить способности модели к рассуждению. Модели серии OpenAI o1 являются ярким примером продвинутого применения PRM. Новые законы масштабирования на этапе тестирования предполагают, что способности к выводу могут быть эффективно улучшены за счет увеличения вычислительных мощностей на этапе тестирования, предоставляя четкое направление для будущего развития языковых моделей. Мы представляем некоторые методы, применяемые на этапе вывода, как показано на рисунке 3. Красные пустые кружки представляют пути рассуждений, отброшенные в процессе исследования алгоритма на этапе вывода, зеленые пустые кружки обозначают пути рассуждений, принятые в процессе исследования, а зеленые заполненные кружки отмечают конечные точки путей рассуждений после того, как правильный ответ идентифицирован.
Голосование большинством: Голосование большинством является одной из самых простых стратегий для генерации окончательного ответа из плотных вычислений на этапе тестирования. Во время вывода каждый след вывода производит предсказание для данного входа. Основная идея заключается в выборе ответа, с которым согласны большинство следов вывода. Предсказания от всех моделей затем агрегируются, и класс, который появляется наиболее часто (голосование большинством), выбирается в качестве окончательного вывода: \(f^* = \arg\max_f \sum_y \mathbb{I}_{\text{final\_ans}(y)=f}\), где \(\mathbb{I}\) — индикаторная функция, а \(y\) — каждый след оценки.
Поиск по дереву [15]: Поиск по дереву — это классический алгоритм, который систематически исследует различные варианты, рекурсивно строя дерево поиска. Он обычно используется в сложных задачах принятия решений, таких как настольные игры и задачи планирования. Поиск по дереву Монте-Карло (MCTS) является одним из наиболее широко используемых методов поиска по дереву. Он состоит из четырех основных шагов: выбор, расширение, симуляция и распространение. Постепенно расширяя пространство поиска, MCTS постепенно улучшает процесс принятия решений. Поиск по дереву уже применялся в некоторых задачах вывода языковых моделей, достигая заметного успеха. Например, фреймворк "Дерево мыслей" [172] позволяет языковым моделям рассматривать несколько путей рассуждений, структурированных как дерево. Он включает самооценку для принятия обдуманных решений, определяя оптимальный курс действий для следующего шага. Этот подход значительно улучшает производительность вывода модели.
Поиск по пучку [133]: Поиск по пучку — это улучшенная версия жадного поиска, обычно используемая в задачах генерации для выбора оптимальной выходной последовательности. Основная идея заключается в сохранении топ-K наивысших оцениваемых путей (называемых пучками) на каждом временном шаге из всех кандидатов для дальнейшего расширения. В отличие от жадного поиска, поиск по пучку поддерживает несколько кандидатов, тем самым расширяя пространство поиска и улучшая качество генерации. Поиск по пучку широко применяется в выводе языковых моделей. Например, BART [71] использует поиск по пучку в качестве своей основной стратегии вывода, демонстрируя его выдающуюся эффективность в задачах генерации текста.
Поиск с упреждением [134]: Поиск с упреждением — это еще один многообещающий метод, который имеет потенциал значительно улучшить вывод языковых моделей. Он модифицирует механизм оценки на каждом шаге поиска по пучку. Вместо выбора лучших кандидатов только на основе оценок текущего шага, поиск с упреждением выполняет прямые симуляции, разворачивая до k шагов вперед. Если конечная точка решения достигается во время прямой симуляции, процесс останавливается раньше. Во время поиска с упреждением используется предварительно обученная и замороженная модель предсказания вознаграждения для оценки каждого шага симуляции. Кумулятивные оценки, полученные от модели предсказания вознаграждения за k-шаговую симуляцию, затем используются для определения того, сохранять или отбрасывать ветвь пучка. Эта стратегия улучшает процесс принятия решений, включая больше контекста в каждый этап оценки. По сравнению с поиском по пучку, поиск с упреждением увеличивает глубину пространства исследования, позволяя судить о текущем принятии решений на основе результатов более далеких симулированных решений. Однако он также увеличивает потребность в вычислительных ресурсах, что также приводит к плохой производительности при ограниченных вычислительных ресурсах.
6. Путь к созданию крупных моделей рассуждения
6.1. Разработка серии OpenAI o1
В сентябре 2024 года OpenAI представила o1, революционную языковую модель, представляющую значительный прогресс в возможностях искусственного интеллекта в области рассуждений, особенно в сложных задачах, таких как математика, программирование и решение научных проблем. 20 декабря 2024 года OpenAI открыла тестирование заявок на o3, улучшенную версию o1 [102], которая считается обладающей интеллектом на уровне доктора наук [7]. Эти модели достигают выдающихся результатов по различным сложным бенчмаркам, включая получение золотого медального уровня на Международной математической олимпиаде [73] и соответствие уровню PhD в вопросах по физике, химии и биологии [48]. Обширные оценки показывают уникальные модели рассуждений серии o1 через систематический анализ её базовых возможностей рассуждения. Мы приводим ключевые выводы существующих исследований:
Эффективная интеграция знаний.
Первоначальные всесторонние оценки [194] демонстрируют структурированный аналитический подход o1 и интеграцию знаний в задачах фундаментального решения проблем, достигая 83,3% успеха в конкурентном программировании через пошаговое логическое выведение, где модель демонстрирует явную способность использовать свои знания для декомпозиции сложных проблем и следовать формальным процессам вывода. Структурированное понимание модели и взаимосвязанное применение знаний дополнительно подтверждается в специализированных областях, таких как радиология и проектирование микросхем, где точный диагноз и анализ сложных схем требуют интеграции множества концепций домена. Систематические оценки [68] количественно подтверждают эту модель, показывая 150% производительности на уровне человека в задачах структурированного аналитического мышления и вычислительного рассуждения. Это преимущество особенно заметно в сценариях, требующих интеграции знаний из разных областей, таких как применение физических принципов к биологическим системам или комбинирование статистических методов с ограничениями, специфичными для домена, что указывает на фундаментальную способность в синтезе и применении знаний.
Систематическая декомпозиция проблем.
o1 поддерживает стабильную производительность в задачах различного уровня сложности, демонстрируя систематическую декомпозицию проблем при увеличении сложности. В математических рассуждениях детальные исследования [27] показывают её систематический подход к декомпозиции проблем, достигая почти идеальных результатов на экзамене по математике B в Нидерландах через структурированные шаги решения. Модель демонстрирует способность идентифицировать ключевые математические принципы, строить формальные доказательства и проверять валидность решения шаг за шагом. Эта последовательность распространяется на более сложные сценарии, что подтверждается исследованиями [26] по 105 задачам по науке и математике возрастающей сложности, где модель сохраняет высокую точность даже при увеличении сложности проблем как в концептуальной глубине, так и в вычислительных требованиях. В задачах программирования эта модель дополнительно демонстрируется через систематическую отладку [52] на бенчмарке QuixBugs, где o1 поддерживает стабильную производительность в исправлении ошибок различной сложности через структурированный трёхэтапный подход: идентификация ошибок, анализ первопричин и целевая коррекция.
Надёжные и связные рассуждения в сложных задачах.
Рассуждения модели эффективно адаптируются к различным типам проблем, всегда демонстрируя последовательность цепочек рассуждений в различных задачах. В задачах планирования оценки PlanBench [144] демонстрируют её систематическое обращение как с детерминированными, так и с вероятностными сценариями, показывая значительное улучшение в удовлетворении ограничений и управлении состояниями. Модель демонстрирует особую силу в обработке проблем с неполной информацией и динамическими ограничениями, поддерживая стабильную производительность как в стандартных, так и в редких вариантах задач [94]. Эта адаптивность указывает на устойчивые возможности обобщения в различных формулировках проблем. Исследования по сложному планированию [146] дополнительно показывают способность o1 поддерживать связность рассуждений в задачах с длинным горизонтом, эффективно управляя расширенными цепочками зависимостей и переходами контекста. Это подтверждается её производительностью в многоэтапных задачах планирования, где промежуточные цели должны быть правильно последовательны, а зависимости тщательно управляемы, демонстрируя продвинутые возможности во временных рассуждениях и причинно-следственном понимании.
Новые законы масштабирования для крупных моделей рассуждения.
Эмпирические исследования демонстрируют уникальные модели масштабирования o1 как на этапах обучения, так и вывода. Во время обучения алгоритм обучения модели с подкреплением в большом масштабе учит её продуктивно мыслить, используя цепочку мыслей в высокоэффективном процессе [103]. Исследования [134] показывают, что благодаря оптимизированным стратегиям вычислительных ресурсов на этапе тестирования модель достигает значительных улучшений производительности в различных задачах рассуждения. Всесторонние оценки [194, 68] показывают, что возможности рассуждения o1 могут быть эффективно усилены за счёт продвинутого распределения вычислительных ресурсов на этапе вывода, особенно в сценариях сложного решения проблем. Ограничения на масштабирование этого подхода существенно отличаются от тех, что применяются при предобучении LLM, с постоянным улучшением производительности при увеличении времени, затрачиваемого на размышления [103]. Это подтверждается в задачах программирования, где разрешение 10,000 отправок на проблему позволяет модели достичь значительно лучших результатов, превышая порог золотой медали даже без стратегий выбора на этапе тестирования. Способность модели эффективно использовать дополнительные вычислительные ресурсы как на этапе обучения, так и на этапе вывода указывает на фундаментальное продвижение в архитектуре рассуждений, демонстрируя особую силу в сценариях, где традиционные подходы могут потребовать значительно больших размеров моделей.
6.2. Попытки открытого исходного кода в создании крупных моделей рассуждения
Фреймворки с открытым исходным кодом также сделали существенные шаги в развитии продвинутых возможностей рассуждения для языковых моделей. Эти фреймворки служат бесценными справочниками для исследователей и разработчиков, стремящихся воспроизвести или приблизить возможности рассуждения проприетарных моделей, таких как OpenAI o1. В этом разделе мы представляем четыре значимых усилия с открытым исходным кодом, каждое из которых использует различные стратегии для улучшения рассуждений языковых моделей (обобщено в Таблице 2). Исследуя их уникальные реализации, мы стремимся предоставить представление о разнообразных методологиях, используемых для усиления способностей к рассуждению в языковых моделях.
Таблица 2: Попытки открытого исходного кода в создании крупных моделей рассуждения: точка зрения вклада.
| Конструирование данных | Предобучение | Постобучение | Улучшение на этапе тестирования | |
|---|---|---|---|---|
| OpenR[145] | MCTS | - | GRPO | Best-of-N |
| Rest-MCTS*[183] | MCTS (в цикле) | - | SFT | Поиск по дереву |
| Journey Learning[110] | - | - | SFT | Поиск по дереву |
| LLaMA-Berry[185] | MCTS | - | DPO | Подсчёт Борда |
Проект OpenR[145].
Проект заявил, что это первый фреймворк с открытым исходным кодом, исследующий основные методы модели OpenAI o1 с использованием техник обучения с подкреплением. Основой репликации OpenR является конструирование данных пошаговых рассуждений, где получается более точная и детализированная обратная связь вместо чисто конечных ответов. Автоматизированный алгоритм увеличения данных OmegaPRM [85] используется путём выбора траекторий рассуждений из построенного дерева поиска. На основе увеличенных процессных данных с контролем на каждом шаге рассуждения, модель вознаграждения процесса дополнительно обучается в схеме контролируемого обучения, основанной на предобученной модели Qwen2.5-Math-7B-Instruct [168]. Модель вознаграждения процесса может быть непосредственно развёрнута на этапе вычислений при тестировании, интегрированная либо с голосованием большинства, либо с лучшими из N, либо с методами поиска по пучку. Она также может быть использована для тонкой настройки языковой модели на этапе постобучения с использованием обучения с подкреплением. Проводятся эксперименты для демонстрации эффективности модели вознаграждения процесса на этапе вычислений при тестировании и постобучении.
*Rest-MCTS[183].**
Вместо того чтобы обучать модель вознаграждения процесса и модель политики тонкой настройки отдельно, они интегрируют эти два обновления в один взаимный цикл самообучения. Вознаграждение процесса в качестве контроля для обучения модели вознаграждения процесса и траектории рассуждений для обучения модели политики собираются заранее на основе аналогично разработанного алгоритма MCTS. Затем начинается итеративный процесс обучения на основе начальной политики π и начальных значений модели вознаграждения процесса Vθ. Политика далее итеративно выполняет MCTS и генерирует решения, в то время как значения влияют на процесс поиска по дереву. Их обновления дополняют друг друга итеративно.
Проект Replication Journey o1[110].
Вместо того чтобы тщательно рассматривать улучшения реализации на обоих этапах, проект направлен на репликацию способностей рассуждения модели OpenAI o1, сосредотачиваясь на всеобъемлющих стратегиях обучения. Он делает акцент на структурированной схеме обучения, которая включает метод проб и ошибок, размышления и откат для построения глубоких причинных рассуждений. Основным аспектом проекта является генерация данных, с высококачественными обучающими примерами, предназначенными для моделирования сложных путей рассуждений. Используя метод обучения путешествием, Replication Journey o1 знакомит модель с различными логическими последовательностями и коррекциями, поощряя исследование и адаптивность на этапе обучения. Однако Replication Journey o1 менее изощрён на этапе вывода, не имея продвинутых техник постобучения, что ограничивает его адаптивность во время реального рассуждения. Этот акцент на обучении над выводом подчёркивает его фундаментальный подход по сравнению с моделями с динамическими оптимизациями вывода.
LLaMA-Berry[185].
Проект направляет своё внимание на оптимизацию способностей к рассуждению на этапе вывода, используя архитектуру LLaMA-3.1-8B для предоставления более сложных корректировок рассуждений в реальном времени. Он использует уникальный подход парной оптимизации, который сочетает поиск по дереву Монте-Карло с самоулучшением (SR-MCTS), позволяя модели динамически исследовать и улучшать пути решений на этапе вывода. Эта конфигурация предоставляет LLaMA-Berry высокий уровень адаптивности, позволяя эффективно и гибко решать сложные, открытые задачи рассуждения. Ключевым компонентом этого фреймворка является модель вознаграждения парных предпочтений (PPRM), которая оценивает пути решений парами, обеспечивая приоритет высококачественным путям рассуждений. Улучшенный подсчёт Борда (EBC) LLaMA-Berry затем консолидирует эти рейтинги предпочтений для руководства принятием решений моделью, дополнительно повышая её сложность на этапе вывода. Эта устойчивая архитектура позиционирует LLaMA-Berry как ведущий пример усиления вывода, отличая её от подхода O1 Replication Journey, ориентированного на обучение.
Эти четыре фреймворка с открытым исходным кодом не только демонстрируют различные стратегии реализации для усиленных рассуждений, но и играют важную роль в улучшении понимания модели OpenAI o1. Вместе они расширяют спектр техник, доступных сообществу открытого исходного кода, продвигая коллективную цель разработки сложных, прозрачных и адаптируемых моделей рассуждения, которые приносят возможности уровня проприетарных систем в общедоступные системы.
7 Другие методы улучшения на этапе тестирования
Помимо поиска, управляемого PRM, существует множество других методов, предназначенных для улучшения способностей LLM к рассуждению с использованием дополнительных вычислительных мощностей на этапе тестирования. Эти методы динамически уточняют результаты рассуждений без изменения самой модели. Подходы, такие как поиск с вербальным подкреплением, подкрепление на основе памяти и поиск в агентских системах, показанные на Рисунке 4, демонстрируют, что значительные улучшения в рассуждениях могут быть достигнуты с использованием готовых LLM. Выборка представительных работ, исследующих эти методы, суммирована в Таблице 3. Хотя эти методы не используют PRM, они предлагают основу для будущих исследований по изучению гибридных моделей для дальнейшего продвижения способностей к рассуждению.
Ссылка на подпись Рисунок 4: Типичные методы улучшения на этапе тестирования без обучения: поиск с вербальным подкреплением, подкрепление на основе памяти и поиск в агентских системах. Таблица 3: Список представительных работ по методам усиления на этапе тестирования без обучения.
| Метод | Категория | Представительная литература |
|---|---|---|
| Поиск с вербальным подкреплением | Индивидуальный агент | Romera et al.[115], Shojaee et al.[130], Mysocki et al.[162], Ma et al.[88] |
| Многоагентный | Chen et al.[20], Zhou et al.[199], Le et al.[69], Yu et al.[176] | |
| Воплощенный агент | Boiko et al.[13] | |
| Подкрепление на основе памяти | Опытное обучение | Zhang et al.[184], Gao et al.[39], Qian et al.[108] |
| Рефлексивное обучение | Shinn et al.[129], Sun et al.[138], Sun et al.[190] | |
| Обучение концептам | Zhang et al.[188], Gao et al.[40], Guan et al.[44] | |
| Поиск в агентских системах | Уровень подсказок | Madaan et al.[90], Fernando et al.[38], Yang et al.[169] |
| Уровень модулей | Shang et al.[125], Zhang et al.[186] | |
| Уровень агентов | Huot et al.[54], Zhuge et al.[200] |
7.1 Поиск с вербальным подкреплением
Поиск с вербальным подкреплением (VRS) использует предварительно обученные рассуждения и семантические способности LLM для исследования и оптимизации пространств решений. В отличие от традиционного обучения с подкреплением или методов, требующих интенсивного обучения, VRS работает исключительно через инференцию на этапе тестирования, используя итеративные циклы обратной связи для уточнения решений без необходимости дополнительного обучения. Опираясь на семантические знания, закодированные в LLM, и их способность следовать сложным инструкциям, VRS предоставляет универсальный подход для навигации по разнообразным пространствам проблем. Этот фреймворк, основанный на инференции, находит применение в индивидуальных агентах, многоагентных системах и воплощенных агентах, поддерживая широкий спектр задач, включая программную оптимизацию, совместное принятие решений и взаимодействия в реальных условиях. В этом разделе анализируется VRS через эти три ключевых аспекта, углубляясь в методологии и уникальные идеи, представленные в каждой категории.
В настройках индивидуальных агентов VRS полагается на итеративные рассуждения и механизмы обратной связи для уточнения решений в структурированных пространствах проблем. Этот подход хорошо подходит для задач, таких как математическая оптимизация, символьные рассуждения и открытия, основанные на гипотезах, где систематическое уточнение значительно улучшает результаты решения проблем. Исследования математических открытий иллюстрируют, как VRS преобразует процесс решения проблем в динамический итеративный цикл. Например, исследования комбинаторных проблем, включая проблемы с множеством и онлайн-упаковку, подчеркивают, как программные решения развиваются через оценку, основанную на обратной связи. Аналогично, исследования символьной регрессии рассматривают уравнения как динамические конструкции, итеративно генерируя, оценивая и оптимизируя математические выражения. Эти подходы показывают, как VRS навигарует по ограниченным пространствам, превосходя традиционные методы оптимизации по эффективности и точности. В научных открытиях VRS показал свою полезность в интеграции рассуждений с эмпирическими данными и симуляциями. Исследователи разработали системы для уточнения биомедицинских гипотез, синтезируя разнообразные источники данных. Например, приложения в онкологии используют итеративный синтез для решения сложностей многомасштабных данных. В физических науках VRS используется для уточнения гипотез через обратную связь симуляции, продвигая такие области, как молекулярный дизайн и открытие физических законов. Эти результаты подчеркивают роль VRS в соединении абстрактных рассуждений с реальной валидацией, поддерживая задачи, которые являются как интенсивными по данным, так и основанными на гипотезах. Рефлексивные процессы в эвристической оптимизации дополнительно демонстрируют гибкость VRS. Например, исследователи изучили итеративное создание и оценку стратегий для решения комбинаторных проблем. Этот подход фокусируется на создании адаптивных гипер-эвристик, которые эффективно обобщаются в различных доменах, непрерывно уточняя решения через циклы обратной связи. В целом, VRS применяет итеративные рассуждения и обратную связь для соединения абстрактного решения проблем с реальными приложениями, решая вызовы в математике, науке и оптимизации с точностью и адаптивностью.
В многоагентных системах VRS способствует сотрудничеству между агентами на основе LLM через общение на естественном языке. Эти системы используют совместные рассуждения и итеративное уточнение для решения сложных пространств решений, позволяя агентам обмениваться идеями и достигать общих целей. Открытие мета-структур в гетерогенных информационных сетях (HIN) иллюстрирует, как VRS применяется в многоагентных контекстах. Недавние исследования соединили рассуждения LLM с эволюционной оптимизацией для уточнения мета-структур, улучшая их объяснимость и точность предсказания. Аналогично, в социально-экономическом предсказании, многоагентные системы интегрируют графы знаний и рассуждения по мета-путям для извлечения межзадачных идей для таких приложений, как оценка населения и предсказание экономической активности. Этот подход способствует сотрудничеству между агентами LLM и улучшает производительность в многозадачных средах. Открытие причинно-следственных связей также выигрывает от многоагентных фреймворков, поддерживаемых VRS. Например, системы, использующие LLM в качестве рассуждающих агентов, совместно обсуждают и предлагают причинно-следственные связи. Интегрируя статистические методы и взаимодействия на естественном языке, эти фреймворки генерируют точные причинно-следственные графы, одновременно решая неоднозначности в причинно-следственных связях. В финансовом принятии решений VRS улучшает иерархическое сотрудничество. Фреймворк FINCON использует систему менеджер-аналитик для уточнения финансовых стратегий с использованием концептуального вербального подкрепления. Снижая избыточное общение и улучшая уточнение стратегий, FINCON демонстрирует полезность VRS в оптимизации процессов финансового принятия решений. С итеративным уточнением и совместными рассуждениями VRS поддерживает многоагентные системы в решении сложных задач, таких как уточнение мета-структур, социально-экономическое предсказание и финансовое принятие решений.
В настройках воплощенных агентов VRS используется для решения реальных задач путем интеграции рассуждений с физическими взаимодействиями, поддерживая такие деятельности, как планирование и выполнение экспериментов в лабораторных условиях. Эти системы расширяют VRS в динамические среды, сочетая семантические рассуждения с практическим экспериментированием. Например, автономные химические исследования продемонстрировали использование систем на основе LLM для независимого проектирования, выполнения и уточнения экспериментов. Эти агенты интегрируют инструменты, такие как роботизированные обработчики жидкостей, спектрометрические устройства и веб-модули исследований для выполнения задач, таких как оптимизация реакций и синтез соединений. Одно из приложений включает оптимизацию палладий-катализируемых реакций кросс-сочетания, где система использует подсказки на естественном языке для определения условий, расчета стехиометрии и автономного выполнения экспериментов. При столкновении с ошибками, такими как неправильные вызовы модулей, система пересматривает свой подход, ссылаясь на документацию и итерируя задачу. Этот итеративный процесс демонстрирует, как VRS поддерживает адаптивность и точность в экспериментальных рабочих процессах. Сочетая рассуждения и обратную связь в реальном времени, воплощенные агенты иллюстрируют способность VRS уточнять и оптимизировать сложные процессы в динамических средах. Эти системы уменьшают вмешательство человека, ускоряя научные открытия, что делает их ценным инструментом для реального экспериментирования и инноваций.
В целом, предыдущие исследования продемонстрировали адаптивность и эффективность VRS в индивидуальных агентах, многоагентных системах и воплощенных агентах. Используя семантические рассуждения и итеративные возможности обратной связи LLM, VRS решает широкий спектр задач без необходимости дополнительного обучения. От структурированной оптимизации в математических и научных контекстах до совместного исследования в многоагентных фреймворках и динамического экспериментирования в реальных приложениях, VRS предоставляет унифицированный подход к решению проблем. VRS как универсальный фреймворк, способный решать сложные вызовы в вычислительных и физических доменах, продвигая достижения в различных областях.
7.2 Подкрепление на основе памяти
При применении к открытым задачам, таким как творческое письмо, сложные логические рассуждения и игры в открытом мире, пространство решений имеет тенденцию к драматическому расширению, часто становясь неограниченным или плохо определенным. Эти задачи обычно требуют непрерывного взаимодействия с окружающей средой для получения соответствующей информации, что делает простые поиски в пространстве решений неэффективными. Для решения этих проблем некоторые исследования включают внешний модуль памяти для агентов LLM. Этот модуль хранит информацию, такую как наблюдения, успешные и неудачные действия из предыдущих попыток. Агенты исследуют свои окружения итеративно, используя память как основу для обучения с вербальным подкреплением. В этом процессе они суммируют опыт, извлекают интерпретируемые высокоуровневые идеи из пространства решений и уточняют свои действия в последующих попытках, тем самым улучшая производительность инференции. Эти исследования не только сосредоточены на исследовании внешнего пространства решений, но и подчеркивают внутреннюю способность агентов LLM развивать понимание пространства решений из памяти. По мере того как агенты накапливают память через исследование окружающей среды, их способности прогрессивно усиливаются и обобщаются на невиданные задачи. Конкретно, мы классифицируем исследования в этой области на следующие три категории.
Опытное обучение. Методы в этой категории побуждают агентов LLM просто эмулировать благоприятные опыты, хранящиеся в памяти, избегая неблагоприятных. REMEMBERER [184] представляет собой полупараметрического агента RL-LLM, который записывает прошлые пары наблюдение-действие в памяти и использует традиционный алгоритм Q-обучения вне политики для динамического поддержания и обновления Q-значения (ожидаемого будущего вознаграждения) каждой пары наблюдение-действие. При столкновении с новой задачей агент извлекает соответствующие действия с наивысшими и наинизшими Q-значениями из памяти, включая их как поощряемые и не поощряемые примеры в подсказку. Обмен памятью [39] использует концепции из многоагентного обучения с подкреплением для повышения эффективности обучения. Множественные агенты выполняют задачи одновременно в общей среде и вносят высококачественные пары подсказка-ответ в общий пул памяти. Каждый агент может извлекать наиболее релевантные примеры из этого пула для облегчения обучения с несколькими примерами. Аналогично, совместное опытное обучение [108] использует многоагентный фреймворк, в котором агенты Инструктор и Ассистент поочередно предоставляют инструкции и решения во время многоэтапной генерации кода. Этот динамический обмен помогает извлекать сокращения для уменьшения избыточности и предотвращения повторяющихся ошибок. При столкновении с новыми задачами эти агенты извлекают соответствующие воспоминания поочередно для улучшения обучения в контексте.
Рефлексивное обучение. Хотя использование памяти в качестве примеров с несколькими примерами эффективно, этот подход не полностью использует способности LLM к семантическому пониманию. Некоторые исследования утверждают, что агенты LLM должны непосредственно размышлять о успехах и неудачах, хранящихся в памяти, чтобы суммировать основные причины явно, принимая эти идеи в качестве руководств. Reflexion [129] является пионерским усилием в этой области, размышляя о причинах успеха или неудачи семантически на основе сигналов обратной связи задачи. Он интегрирует рефлексивный текст и прошлые траектории в подсказки для улучшения принятия решений в последующих попытках. ExpeL [190] сочетает имитацию и рефлексию, извлекая наиболее релевантные успешные опыты из памяти, суммируя паттерны успешных траекторий и выявляя идеи из сравнений пар успех-неудача. RAHL [138], вдохновленный иерархическим обучением с подкреплением, организует память в модули целей и подзадач, позволяя рефлексировать и суммировать опыт на разных уровнях. Для новых задач он извлекает соответствующий опыт для формулирования высокоуровневых целей и низкоуровневых подзадач отдельно.
Обучение концептам. Явная рефлексия значительно улучшает способности LLM к инференции. Основываясь на этом, некоторые исследования направлены на то, чтобы позволить агентам LLM развивать обобщенные "концепции", которые выходят за рамки конкретных задач, способствуя более широкому пониманию окружающей среды и задач. Эта обобщенность помогает агентам усваивать когнитивные способности из памяти и непрерывно развиваться по мере роста памяти. Например, Agent-Pro [188] позволяет агентам устанавливать убеждения о себе и своей среде в карточных играх. Вместо того чтобы размышлять о отдельных действиях, он оценивает рациональность и последовательность этих убеждений, итеративно уточняя стратегии. Аналогично, Richelieu [44] снабжает агентов пониманием среды в стратегических военных играх. Он извлекает наиболее релевантные состояния из памяти для формулирования планов и оценки их осуществимости. Используя самоигру, он собирает опыт автономно, принимая роли всех игроков для продвижения своих знаний. Self-Evolving GPT [40], вдохновленный механизмами человеческой памяти, разрабатывает фреймворк автономного обучения на основе памяти для LLM. Он категоризирует задачи для определения соответствующих извлечений памяти и выявляет различия между хранящимися воспоминаниями и текущей задачей для извлечения общего опыта. Кроме того, он генерирует невиданные задачи для практики, консолидируя свои знания на основе результатов извлечения памяти.
7.3 Поиск в агентских системах
Дизайн агентских систем играет ключевую роль в использовании мощности LLM для многих задач. Важная ветвь методов улучшения на этапе тестирования заключается в использовании LLM для поиска в агентских системах. Исследования в этой области могут быть классифицированы на три уровня поиска: уровень подсказок, уровень модулей и уровень агентов. Обратите внимание, что этот подход не направлен на прямой поиск в пространстве решений, а скорее использует эмпирические данные для оптимизации самой агентской системы, что аналогично проблеме мета-обучения. Мы суммируем соответствующие работы в этой области следующим образом.
Уровень подсказок. Процесс "верификации и коррекции" улучшает подсказки путем итеративной интеграции полезного опыта обратной связи. Сигнал верификации может исходить из внешней обратной связи, самооценки LLM и других источников. С другой стороны, сами подсказки также заслуживают поиска и оптимизации. Автоматизированная инженерия подсказок, такая как эволюционная оптимизация подсказок и итерации мета-подсказок, может достигать лучших результатов, чем ручные подсказки, но также вводит большее потребление токенов.
Уровень модулей. Agentsquare [125] предлагает использовать LLM для поиска модульного дизайна агентской системы, где модули по сути являются блоками подсказок, имеющими специфические функции планирования, рассуждения, использования инструментов и памяти. Основные единицы этих агентских модулей имеют стандартный интерфейс ввода-вывода, который позволяет им хорошо взаимодействовать друг с другом. Преимущество поиска на уровне модулей заключается в том, что он позволяет новым агентам легко повторно использовать классический дизайн агентов, таких как CoT и ToT, через рекомбинацию модулей. Кроме того, Aflow [186] соединяет различные вызывающие узлы LLM через ребра, представленные кодом. Помимо метода поиска, необходимо оценивать производительность найденных агентов. Функция, используемая для оценки производительности агентов, также может быть основана на LLM для улучшения эффективности поиска, одновременно тесно соответствуя их реальной производительности.
Уровень агентов. ADAS предлагает использовать LLM для поиска всей агентской системы, определенной в пространстве кода Python. Кроме того, многоагентные системы принимают решения и достигают целей в общей среде. На уровне поиска многоагентных систем ключевые аспекты включают создание агентов, восприятие окружающей среды, действие, взаимодействие и эволюцию системы. Поиск в многоагентных системах достиг хороших результатов в задачах, таких как создание длинных историй. Унифицированный механизм поиска и оптимизации для многоагентных систем в настоящее время исследуется. GPTSwarm улучшает способность агентов к сотрудничеству через оптимизацию графов.
Поиск в агентских системах предоставляет агентам способность к самоулучшению, позволяя им оптимизировать себя для улучшения своих способностей к рассуждению без необходимости вносить изменения в структуру LLM. Указанные три уровня поиска имеют обширные пространства поиска. Общий вызов, с которым сталкиваются эти три уровня поиска, заключается в улучшении эффективности поиска, снижении затрат на поиск и обеспечении автоматизации при сохранении рациональности поиска.
7.4 Итог
Методы улучшения на этапе тестирования, рассмотренные в этом разделе, в настоящее время не включены в реализации больших моделей рассуждения. Однако они имеют огромный потенциал для дальнейшего повышения способностей LLM к рассуждению через более комплексное "мышление" на этапе тестирования, способствуя стратегическому рассуждению LLM в пространстве решений, использованию прошлого опыта и динамической оптимизации рабочих процессов агентов. Поэтому обучение LLM для освоения этих методов на этапе тестирования представляет собой многообещающее направление будущих исследований с потенциалом возвысить LLM с уровня "рассуждающих" до полностью функциональных "агентов".
References
- [1] Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report. arXiv preprint arXiv:2412.08905, 2024.
- [2] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [3] Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022.
- [4] Afra Amini, Tim Vieira, and Ryan Cotterell. Direct preference optimization with an offset. arXiv preprint arXiv:2402.10571, 2024.
- [5] Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms, 2019.
- [6] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- [7] AXIOS. Openai’s new o3 model freaks out computer science majors. 2025.
- [8] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- [9] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- [10] Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. Phyre: A new benchmark for physical reasoning. Advances in Neural Information Processing Systems, 32, 2019.
- [11] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690, 2024.
- [12] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- [13] Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models. Nature, 624(7992):570–578, 2023.
- [14] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [15] Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods. IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012.
- [16] Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Alphamath almost zero: process supervision without process. arXiv preprint arXiv:2405.03553, 2024.
- [17] Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. Step-level value preference optimization for mathematical reasoning. arXiv preprint arXiv:2406.10858, 2024.
- [18] Jiaqi Chen, Tong Li, Jinghui Qin, Pan Lu, Liang Lin, Chongyu Chen, and Xiaodan Liang. Unigeo: Unifying geometry logical reasoning via reformulating mathematical expression, 2022.
- [19] Jiaqi Chen, Jianheng Tang, Jinghui Qin, Xiaodan Liang, Lingbo Liu, Eric P. Xing, and Liang Lin. Geoqa: A geometric question answering benchmark towards multimodal numerical reasoning, 2022.
- [20] Lin Chen, Fengli Xu, Nian Li, Zhenyu Han, Meng Wang, Yong Li, and Pan Hui. Large language model-driven meta-structure discovery in heterogeneous information network. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 307–318, 2024.
- [21] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [22] Nuo Chen, Yan Wang, Haiyun Jiang, Deng Cai, Yuhan Li, Ziyang Chen, Longyue Wang, and Jia Li. Large language models meet harry potter: A dataset for aligning dialogue agents with characters. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 8506–8520, 2023.
- [23] Wenhu Chen, Ming Yin, Max Ku, Pan Lu, Yixin Wan, Xueguang Ma, Jianyu Xu, Xinyi Wang, and Tony Xia. Theoremqa: A theorem-driven question answering dataset, 2023.
- [24] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- [25] Julian Coda-Forno, Marcel Binz, Zeynep Akata, Matt Botvinick, Jane Wang, and Eric Schulz. Meta-in-context learning in large language models. Advances in Neural Information Processing Systems, 36, 2024.
- [26] Ernest Davis. Testing gpt-4-o1-preview on math and science problems: A follow-up study. arXiv preprint arXiv:2410.22340, 2024.
- [27] Joost CF de Winter, Dimitra Dodou, and Yke Bauke Eisma. System 2 thinking in openai’s o1-preview model: Near-perfect performance on a mathematics exam. Computers, 13(11):278, 2024.
- [28] Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems, 36, 2024.
- [29] Xiang Deng, Yu Su, Alyssa Lees, You Wu, Cong Yu, and Huan Sun. Reasonbert: Pre-trained to reason with distant supervision. arXiv preprint arXiv:2109.04912, 2021.
- [30] Jacob Devlin. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [31] Bosheng Ding, Chengwei Qin, Ruochen Zhao, Tianze Luo, Xinze Li, Guizhen Chen, Wenhan Xia, Junjie Hu, Anh Tuan Luu, and Shafiq Joty. Data augmentation using llms: Data perspectives, learning paradigms and challenges. arXiv preprint arXiv:2403.02990, 2024.
- [32] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233, 2023.
- [33] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey on in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- [34] Igor Douven. Abduction. In Edward N. Zalta, editor, The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Summer 2021 edition, 2021.
- [35] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- [36] Tom Duenas and Diana Ruiz. The path to superintelligence: A critical analysis of openai’s five levels of ai progression. ResearchGate, 2024b. doi, 10, 2024.
- [37] Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625–630, 2024.
- [38] Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797, 2023.
- [39] Hang Gao and Yongfeng Zhang. Memory sharing for large language model based agents. arXiv preprint arXiv:2404.09982, 2024.
- [40] Jinglong Gao, Xiao Ding, Yiming Cui, Jianbai Zhao, Hepeng Wang, Ting Liu, and Bing Qin. Self-evolving gpt: A lifelong autonomous experiential learner. arXiv preprint arXiv:2407.08937, 2024.
- [41] Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning. arXiv preprint arXiv:2410.02089, 2024.
- [42] Akshay Goel, Almog Gueta, Omry Gilon, Chang Liu, Sofia Erell, Lan Huong Nguyen, Xiaohong Hao, Bolous Jaber, Shashir Reddy, Rupesh Kartha, et al. Llms accelerate annotation for medical information extraction. In Machine Learning for Health (ML4H), pages 82–100. PMLR, 2023.
- [43] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023.
- [44] Zhenyu Guan, Xiangyu Kong, Fangwei Zhong, and Yizhou Wang. Richelieu: Self-evolving llm-based agents for ai diplomacy. arXiv preprint arXiv:2407.06813, 2024.
- [45] Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998, 2023.
- [46] Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alex Wardle-Solano, Hannah Szabo, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander R. Fabbri, Wojciech Kryscinski, Semih Yavuz, Ye Liu, Xi Victoria Lin, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev. Folio: Natural language reasoning with first-order logic, 2024.
- [47] James Hawthorne. Inductive Logic. In Edward N. Zalta and Uri Nodelman, editors, The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Summer 2024 edition, 2024.
- [48] Kadhim Hayawi and Sakib Shahriar. A cross-domain performance report of open ai chatgpt o1 model. 2024.
- [49] Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938, 2021.
- [50] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset, 2021.
- [51] Mohammad Javad Hosseini, Hannaneh Hajishirzi, Oren Etzioni, and Nate Kushman. Learning to solve arithmetic word problems with verb categorization. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 523–533, Doha, Qatar, October 2014. Association for Computational Linguistics.
- [52] Haichuan Hu, Ye Shang, Guolin Xu, Congqing He, and Quanjun Zhang. Can gpt-o1 kill all bugs? an evaluation of gpt-family llms on quixbugs. arXiv e-prints, pages arXiv–2409, 2024.
- [53] Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. arXiv preprint arXiv:2408.08435, 2024.
- [54] Fantine Huot, Reinald Kim Amplayo, Jennimaria Palomaki, Alice Shoshana Jakobovits, Elizabeth Clark, and Mirella Lapata. Agents’ room: Narrative generation through multi-step collaboration. arXiv preprint arXiv:2410.02603, 2024.
- [55] Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, and Minjoon Seo. Self-explore to avoid the pit: Improving the reasoning capabilities of language models with fine-grained rewards. arXiv preprint arXiv:2404.10346, 2024.
- [56] interconnects.ai. blob reinforcement fine-tuning. (Accessed: 2025-12-6).
- [57] Albert Q. Jiang, Wenda Li, Jesse Michael Han, and Yuhuai Wu. Lisa: Language models of isabelle proofs. 6th Conference on Artificial Intelligence and Theorem Proving, 2021.
- [58] Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770, 2023.
- [59] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- [60] Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment. arXiv preprint arXiv:2410.01679, 2024.
- [61] Hannah Kim, Kushan Mitra, Rafael Li Chen, Sajjadur Rahman, and Dan Zhang. Meganno+: A human-llm collaborative annotation system. arXiv preprint arXiv:2402.18050, 2024.
- [62] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- [63] Kazushi Kondo, Saku Sugawara, and Akiko Aizawa. Probing physical reasoning with counter-commonsense context. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 603–612, 2023.
- [64] Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. Training language models to self-correct via reinforcement learning. arXiv preprint arXiv:2409.12917, 2024.
- [65] Teyun Kwon, Norman Di Palo, and Edward Johns. Language models as zero-shot trajectory generators. IEEE Robotics and Automation Letters, 2024.
- [66] Philippe Laban, Wojciech Kryściński, Divyansh Agarwal, Alexander R Fabbri, Caiming Xiong, Shafiq Joty, and Chien-Sheng Wu. Llms as factual reasoners: Insights from existing benchmarks and beyond. arXiv preprint arXiv:2305.14540, 2023.
- [67] Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning, pages 18319–18345. PMLR, 2023.
- [68] Ehsan Latif, Yifan Zhou, Shuchen Guo, Yizhu Gao, Lehong Shi, Matthew Nayaaba, Gyeonggeon Lee, Liang Zhang, Arne Bewersdorff, Luyang Fang, et al. A systematic assessment of openai o1-preview for higher order thinking in education. arXiv preprint arXiv:2410.21287, 2024.
- [69] Hao Duong Le, Xin Xia, and Zhang Chen. Multi-agent causal discovery using large language models. arXiv preprint arXiv:2407.15073, 2024.
- [70] Nicholas Lee, Thanakul Wattanawong, Sehoon Kim, Karttikeya Mangalam, Sheng Shen, Gopala Anumanchipalli, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. Llm2llm: Boosting llms with novel iterative data enhancement. arXiv preprint arXiv:2403.15042, 2024.
- [71] M Lewis. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
- [72] Chengpeng Li, Guanting Dong, Mingfeng Xue, Ru Peng, Xiang Wang, and Dayiheng Liu. Dotamath: Decomposition of thought with code assistance and self-correction for mathematical reasoning. arXiv preprint arXiv:2407.04078, 2024.
- [73] Leo Li, Ye Luo, and Tingyou Pan. Openai-o1 ab testing: Does the o1 model really do good reasoning in math problem solving? arXiv preprint arXiv:2411.06198, 2024.
- [74] Minzhi Li, Taiwei Shi, Caleb Ziems, Min-Yen Kan, Nancy F Chen, Zhengyuan Liu, and Diyi Yang. Coannotating: Uncertainty-guided work allocation between human and large language models for data annotation. arXiv preprint arXiv:2310.15638, 2023.
- [75] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023.
- [76] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023.
- [77] Alisa Liu, Swabha Swayamdipta, Noah A. Smith, and Yejin Choi. Wanli: Worker and ai collaboration for natural language inference dataset creation, 2022.
- [78] Chengwu Liu, Jianhao Shen, Huajian Xin, Zhengying Liu, Ye Yuan, Haiming Wang, Wei Ju, Chuanyang Zheng, Yichun Yin, Lin Li, Ming Zhang, and Qun Liu. Fimo: A challenge formal dataset for automated theorem proving, 2023.
- [79] Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688, 2023.
- [80] Elita Lobo, Chirag Agarwal, and Himabindu Lakkaraju. On the impact of fine-tuning on chain-of-thought reasoning. arXiv preprint arXiv:2411.15382, 2024.
- [81] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024.
- [82] Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning, 2021.
- [83] Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning, 2023.
- [84] Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583, 2023.
- [85] Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, et al. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592, 2024.
- [86] Man Luo, Shrinidhi Kumbhar, Ming shen, Mihir Parmar, Neeraj Varshney, Pratyay Banerjee, Somak Aditya, and Chitta Baral. Towards logiglue: A brief survey and a benchmark for analyzing logical reasoning capabilities of language models, 2024.
- [87] Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn llm agents. arXiv preprint arXiv:2401.13178, 2024.
- [88] Pingchuan Ma, Tsun-Hsuan Wang, Minghao Guo, Zhiqing Sun, Joshua B Tenenbaum, Daniela Rus, Chuang Gan, and Wojciech Matusik. Llm and simulation as bilevel optimizers: A new paradigm to advance physical scientific discovery. arXiv preprint arXiv:2405.09783, 2024.
- [89] Carey Maas, Saatchi Wheeler, Shamash Billington, et al. To infinity and beyond: Show-1 and showrunner agents in multi-agent simulations. To infinity and beyond: Show-1 and showrunner agents in multi-agent simulations, 2023.
- [90] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36, 2024.
- [91] Utkarsh Mall, Cheng Perng Phoo, Meilin Kelsey Liu, Carl Vondrick, Bharath Hariharan, and Kavita Bala. Remote sensing vision-language foundation models without annotations via ground remote alignment. arXiv preprint arXiv:2312.06960, 2023.
- [92] Yujun Mao, Yoon Kim, and Yilun Zhou. Champ: A competition-level dataset for fine-grained analyses of llms’ mathematical reasoning capabilities, 2024.
- [93] Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning, 2022.
- [94] R Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D Hardy, and Thomas L Griffiths. When a language model is optimized for reasoning, does it still show embers of autoregression? an analysis of openai o1. arXiv preprint arXiv:2410.01792, 2024.
- [95] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2381–2391, 2018.
- [96] Marie Mikulová, Milan Straka, Jan Štěpánek, Barbora Štěpánková, and Jan Hajič. Quality and efficiency of manual annotation: Pre-annotation bias. arXiv preprint arXiv:2306.09307, 2023.
- [97] Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837, 2022.
- [98] Arbi Haza Nasution and Aytug Onan. Chatgpt label: Comparing the quality of human-generated and llm-generated annotations in low-resource language nlp tasks. IEEE Access, 2024.
- [99] Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial nli: A new benchmark for natural language understanding, 2020.
- [100] Timothy Niven and Hung-Yu Kao. Probing neural network comprehension of natural language arguments, 2019.
- [101] OpenAI. Reinforcement fine-tuning. (Accessed: 2025-12-6).
- [102] OpenAI. Early access for safety testing. 2024.
- [103] OpenAI. Learning to reason with llms. 2024.
- [104] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- [105] Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22, 2023.
- [106] Raul Puri, Ryan Spring, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Training question answering models from synthetic data. arXiv preprint arXiv:2002.09599, 2020.
- [107] Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. Communicative agents for software development. arXiv preprint arXiv:2307.07924, 2023.
- [108] Chen Qian, Yufan Dang, Jiahao Li, Wei Liu, Zihao Xie, Yifei Wang, Weize Chen, Cheng Yang, Xin Cong, Xiaoyin Che, et al. Experiential co-learning of software-developing agents. arXiv preprint arXiv:2312.17025, 2023.
- [109] Shuofei Qiao, Ningyu Zhang, Runnan Fang, Yujie Luo, Wangchunshu Zhou, Yuchen Eleanor Jiang, Chengfei Lv, and Huajun Chen. Autoact: Automatic agent learning from scratch via self-planning. arXiv preprint arXiv:2401.05268, 2024.
- [110] Yiwei Qin, Xuefeng Li, Haoyang Zou, Yixiu Liu, Shijie Xia, Zhen Huang, Yixin Ye, Weizhe Yuan, Hector Liu, Yuanzhi Li, et al. O1 replication journey: A strategic progress report–part 1. arXiv preprint arXiv:2410.18982, 2024.
- [111] Alec Radford. Improving language understanding by generative pre-training. 2018.
- [112] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024.
- [113] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- [114] Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, and Yejin Choi. Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. arXiv preprint arXiv:2210.01241, 2022.
- [115] Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468–475, 2024.
- [116] Subhro Roy and Dan Roth. Solving general arithmetic word problems, 2016.
- [117] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8732–8740, 2020.
- [118] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4463–4473, 2019.
- [119] Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought, 2023.
- [120] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
- [121] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- [122] Bilgehan Sel, Ahmad Al-Tawaha, Vanshaj Khattar, Ruoxi Jia, and Ming Jin. Algorithm of thoughts: Enhancing exploration of ideas in large language models. arXiv preprint arXiv:2308.10379, 2023.
- [123] Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for llm reasoning. arXiv preprint arXiv:2410.08146, 2024.
- [124] Murray Shanahan, Kyle McDonell, and Laria Reynolds. Role play with large language models. Nature, 623(7987):493–498, 2023.
- [125] Yu Shang, Yu Li, Keyu Zhao, Likai Ma, Jiahe Liu, Fengli Xu, and Yong Li. Agentsquare: Automatic llm agent search in modular design space. arXiv preprint arXiv:2410.06153, 2024.
- [126] Lior Shani, Aviv Rosenberg, Asaf Cassel, Oran Lang, Daniele Calandriello, Avital Zipori, Hila Noga, Orgad Keller, Bilal Piot, Idan Szpektor, et al. Multi-turn reinforcement learning from preference human feedback. arXiv preprint arXiv:2405.14655, 2024.
- [127] Chenyang Shao, Fengli Xu, Bingbing Fan, Jingtao Ding, Yuan Yuan, Meng Wang, and Yong Li. Beyond imitation: Generating human mobility from context-aware reasoning with large language models. arXiv preprint arXiv:2402.09836, 2024.
- [128] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- [129] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
- [130] Parshin Shojaee, Kazem Meidani, Shashank Gupta, Amir Barati Farimani, and Chandan K Reddy. Llm-sr: Scientific equation discovery via programming with large language models. arXiv preprint arXiv:2404.18400, 2024.
- [131] Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768, 2020.
- [132] Koustuv Sinha, Shagun Sodhani, Jin Dong, Joelle Pineau, and William L. Hamilton. Clutrr: A diagnostic benchmark for inductive reasoning from text, 2019.
- [133] W Smoke and E Dubinsky. A program for the machine translation of natural languages. Mech. Transl. Comput. Linguistics, 6:2–10, 1961.
- [134] Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024.
- [135] Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration-based trajectory optimization for llm agents. arXiv preprint arXiv:2403.02502, 2024.
- [136] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
- [137] Theodore R Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents. arXiv preprint arXiv:2309.02427, 2023.
- [138] Chuanneng Sun, Songjun Huang, and Dario Pompili. Retrieval-augmented hierarchical in-context reinforcement learning and hindsight modular reflections for task planning with llms, 2024.
- [139] Richard Sutton. The bitter lesson. Incomplete Ideas (blog), 13(1):38, 2019.
- [140] Oyvind Tafjord, Bhavana Dalvi Mishra, and Peter Clark. Proofwriter: Generating implications, proofs, and abductive statements over natural language, 2021.
- [141] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, 2019.
- [142] Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, and Huan Liu. Large language models for data annotation: A survey. arXiv preprint arXiv:2402.13446, 2024.
- [143] Luong Trung, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. Reft: Reasoning with reinforced fine-tuning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7601–7614, 2024.
- [144] Karthik Valmeekam, Kaya Stechly, and Subbarao Kambhampati. Llms still can’t plan; can lrms? a preliminary evaluation of openai’s o1 on planbench. arXiv preprint arXiv:2409.13373, 2024.
- [145] Jun Wang, Meng Fang, Ziyu Wan, Muning Wen, Jiachen Zhu, Anjie Liu, Ziqin Gong, Yan Song, Lei Chen, Lionel M Ni, et al. Openr: An open source framework for advanced reasoning with large language models. arXiv preprint arXiv:2410.09671, 2024.
- [146] Kevin Wang, Junbo Li, Neel P Bhatt, Yihan Xi, Qiang Liu, Ufuk Topcu, and Zhangyang Wang. On the planning abilities of openai’s o1 models: Feasibility, optimality, and generalizability. arXiv preprint arXiv:2409.19924, 2024.
- [147] Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091, 2023.
- [148] Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024.
- [149] Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu, and Zhifang Sui. Math-shepherd: A label-free step-by-step verifier for llms in mathematical reasoning. arXiv preprint arXiv:2312.08935, 2023.
- [150] Tianlong Wang, Xueting Han, and Jing Bai. Cpl: Critical planning step learning boosts llm generalization in reasoning tasks. arXiv preprint arXiv:2409.08642, 2024.
- [151] Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. Scibench: Evaluating college-level scientific problem-solving abilities of large language models, 2024.
- [152] Xinru Wang, Hannah Kim, Sajjadur Rahman, Kushan Mitra, and Zhengjie Miao. Human-llm collaborative annotation through effective verification of llm labels. In Proceedings of the CHI Conference on Human Factors in Computing Systems, pages 1–21, 2024.
- [153] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- [154] Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. arXiv preprint arXiv:2406.01574, 2024.
- [155] Zhiruo Wang, Shuyan Zhou, Daniel Fried, and Graham Neubig. Execution-based evaluation for open-domain code generation. arXiv preprint arXiv:2212.10481, 2022.
- [156] Zihan Wang, Yunxuan Li, Yuexin Wu, Liangchen Luo, Le Hou, Hongkun Yu, and Jingbo Shang. Multi-step problem solving through a verifier: An empirical analysis on model-induced process supervision. arXiv preprint arXiv:2402.02658, 2024.
- [157] Taylor Webb, Keith J Holyoak, and Hongjing Lu. Emergent analogical reasoning in large language models. Nature Human Behaviour, 7(9):1526–1541, 2023.
- [158] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- [159] Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- [160] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- [161] Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V Le. Simple synthetic data reduces sycophancy in large language models. arXiv preprint arXiv:2308.03958, 2023.
- [162] Oskar Wysocki, Magdalena Wysocka, Danilo Carvalho, Alex Teodor Bogatu, Danilo Miranda Gusicuma, Maxime Delmas, Harriet Unsworth, and Andre Freitas. An llm-based knowledge synthesis and scientific reasoning framework for biomedical discovery. arXiv preprint arXiv:2406.18626, 2024.
- [163] Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey. arXiv preprint arXiv:2309.07864, 2023.
- [164] Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Dingwen Yang, Chenyang Liao, Xin Guo, Wei He, et al. Agentgym: Evolving large language model-based agents across diverse environments. arXiv preprint arXiv:2406.04151, 2024.
- [165] Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning. arXiv preprint arXiv:2405.00451, 2024.
- [166] Jing Xiong, Jianhao Shen, Ye Yuan, Haiming Wang, Yichun Yin, Zhengying Liu, Lin Li, Zhijiang Guo, Qingxing Cao, Yinya Huang, Chuanyang Zheng, Xiaodan Liang, Ming Zhang, and Qun Liu. TRIGO: Benchmarking Formal Mathematical Proof Reduction for Generative Language Models, October 2023. arXiv:2310.10180 [cs].
- [167] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- [168] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024.
- [169] Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. In The Twelfth International Conference on Learning Representations, 2024.
- [170] Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. Leandojo: Theorem proving with retrieval-augmented language models, 2023.
- [171] Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems, 35:20744–20757, 2022.
- [172] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- [173] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- [174] Haoran Ye, Jiarui Wang, Zhiguang Cao, Federico Berto, Chuanbo Hua, Haeyeon Kim, Jinkyoo Park, and Guojie Song. Reevo: Large language models as hyper-heuristics with reflective evolution. arXiv preprint arXiv:2402.01145, 2024.
- [175] Nathan Young, Qiming Bao, Joshua Bensemann, and Michael Witbrock. Abductionrules: Training transformers to explain unexpected inputs, 2022.
- [176] Yangyang Yu, Zhiyuan Yao, Haohang Li, Zhiyang Deng, Yupeng Cao, Zhi Chen, Jordan W Suchow, Rong Liu, Zhenyu Cui, Zhaozhuo Xu, et al. Fincon: A synthesized llm multi-agent system with conceptual verbal reinforcement for enhanced financial decision making. arXiv preprint arXiv:2407.06567, 2024.
- [177] Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, and Songfang Huang. How well do large language models perform in arithmetic tasks?, 2023.
- [178] Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. Swag: A large-scale adversarial dataset for grounded commonsense inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 93–104, 2018.
- [179] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019.
- [180] Qingbin Zeng, Qinglong Yang, Shunan Dong, Heming Du, Liang Zheng, Fengli Xu, and Yong Li. Perceive, reflect, and plan: Designing llm agent for goal-directed city navigation without instructions. arXiv preprint arXiv:2408.04168, 2024.
- [181] Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. Evaluating large language models at evaluating instruction following. In International Conference on Learning Representations (ICLR), 2024.
- [182] Chenhui Zhang and Sherrie Wang. Good at captioning, bad at counting: Benchmarking gpt-4v on earth observation data. arXiv preprint arXiv:2401.17600, 2024.
- [183] Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search. arXiv preprint arXiv:2406.03816, 2024.
- [184] Danyang Zhang, Lu Chen, Situo Zhang, Hongshen Xu, Zihan Zhao, and Kai Yu. Large language models are semi-parametric reinforcement learning agents. Advances in Neural Information Processing Systems, 36, 2024.
- [185] Di Zhang, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, Shufei Zhang, Marco Pavone, Yuqiang Li, et al. Llama-berry: Pairwise optimization for o1-like olympiad-level mathematical reasoning. arXiv preprint arXiv:2410.02884, 2024.
- [186] Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. Aflow: Automating agentic workflow generation. arXiv preprint arXiv:2410.10762, 2024.
- [187] Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792, 2023.
- [188] Wenqi Zhang, Ke Tang, Hai Wu, Mengna Wang, Yongliang Shen, Guiyang Hou, Zeqi Tan, Peng Li, Yueting Zhuang, and Weiming Lu. Agent-pro: Learning to evolve via policy-level reflection and optimization. arXiv preprint arXiv:2402.17574, 2024.
- [189] Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493, 2022.
- [190] Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024.
- [191] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- [192] Yilun Zhao, Yunxiang Li, Chenying Li, and Rui Zhang. Multihiertt: Numerical reasoning over multi hierarchical tabular and textual data, 2022.
- [193] Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. Minif2f: a cross-system benchmark for formal olympiad-level mathematics, 2022.
- [194] Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu, et al. Evaluation of openai o1: Opportunities and challenges of agi. arXiv preprint arXiv:2409.18486, 2024.
- [195] Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36, 2024.
- [196] Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.
- [197] Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023.
- [198] Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. Archer: Training language model agents via hierarchical multi-turn rl. arXiv preprint arXiv:2402.19446, 2024.
- [199] Zhilun Zhou, Jingyang Fan, Yu Liu, Fengli Xu, Depeng Jin, and Yong Li. Synergizing llm agents and knowledge graph for socioeconomic prediction in lbsn. arXiv preprint arXiv:2411.00028, 2024.
- [200] Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. In Forty-first International Conference on Machine Learning.