SeerAttention - динамические разреженное внимание для LLM
Внимание является краеугольным камнем современных крупных языковых моделей (LLM). Однако его квадратичная сложность ограничивает эффективность и масштабируемость LLM, особенно для моделей с длинным контекстом. Перспективный подход, решающий эту проблему, заключается в использовании разреженности в механизме внимания. Однако существующие решения, основанные на разреженности, в основном полагаются на заранее определенные шаблоны или эвристики для аппроксимации разреженности. Этот подход не в полной мере отражает динамическую природу разреженности внимания в языковых задачах. В данной работе утверждается, что разреженность внимания должна быть изучена, а не заранее определена. Для этого мы разрабатываем SeerAttention — новый механизм внимания, который дополнительно использует обучаемый механизм, который адаптивно выбирает значимые блоки в карте внимания и считает остальные блоки разреженными. Такая разреженность на уровне блоков эффективно балансирует точность и ускорение. Для обеспечения эффективного обучения сети управления мы разрабатываем специализированную реализацию FlashAttention, которая извлекает истинные данные на уровне блоков карты внимания с минимальными накладными расходами.
SeerAttention применим не только на стадии постобучения, но и превосходит другие методы разреженного внимания на длинных контекстах. Результаты показывают, что на стадии постобучения SeerAttention значительно превосходит современные методы разреженного внимания, основанные на статике или эвристиках, при этом он более универсален и гибок, адаптируясь к различной длине контекста и коэффициентам разреженности.
При применении SeerAttention для файн-тюнинга на длинных контекстах с YaRN SeerAttention достигает коэффициента разреженности 90% при длине контекста 32k с минимальными потерями перплексии, обеспечивая ускорение в 5,67 раза по сравнению с FlashAttention-2.
По материалам https://arxiv.org/html/2410.13276v1
Код доступен на https://github.com/microsoft/SeerAttention
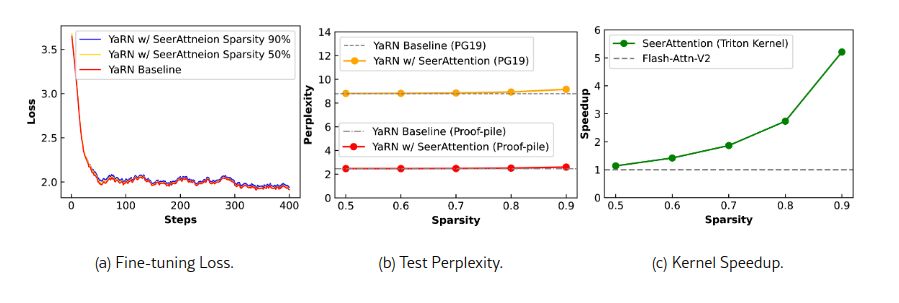
Рис.1. SeerAttention использует основанный на обучении подход для использования разреженности внимания LLM, применимый как на этапе постобучения, так и на этапе тонкой настройки. Благодаря включению SeerAttention с YaRN (Peng et al., 2024) для расширения модели Llama-3-8B с 8 до 32 тыс. байтов контекстной длины, кривые потерь для разреженности 50–90% почти идентичны базовой линии плотной YaRN (a); Для тестовой перплексии разреженность 50% обеспечивает производительность почти без потерь, и даже при разреженности 90% потери остаются минимальными (b); SeerAttention достигает ускорения вывода до 5,67x при разреженности 90% по сравнению с FlashAttention-2 (Dao, 2023);
Общий подход
Внимание является основным механизмом в трансформаторных LLM (Vaswani, 2017). Несмотря на свою эффективность, квадратичная сложность внимания требует значительных вычислительных и ресурсов RAM или VRAM, что ограничивает масштабируемость и эффективность LLM, особенно с длинными окнами контекста. Эта проблема стала активной темой исследований. Одним из возможных решений является замена квадратичного внимания на более дешевые архитектуры, такие как линейное внимание или рекуррентные сети (Katharopoulos et al., 2020; Peng et al., 2023) с субквадратичной сложностью. Эти решения, хотя и эффективны, не могут полностью заменить полноценное внимание, особенно при большом масштабе.
Перспективный подход, который привлекает все больше интереса, заключается в использовании разреженности в внимания - sparse attention. Разреженность часто встречается в картах внимания и становится более выраженной при длинных контекстах. В некоторых головах внимания LLM коэффициент разреженности может достигать 95% или даже 99%, что открывает большие возможности для улучшения эффективности. Однако предыдущие исследования часто полагаются на заранее определенные шаблоны разреженности или эвристики для аппроксимации механизма внимания (Jiang et al., 2024; Fu et al., 2024; Lee et al., 2024; Zhu et al., 2024; Han et al., 2023). Разреженность, обнаруживаемая в картах внимания, значительно различается между различными моделями, языковыми вводами и головами внимания, что делает заранее определенные шаблоны или эвристики недостаточными.
В данной работе утверждается, что разреженность внимания должна быть изучена, а не заранее определена. Для этого вводится SeerAttention — новый механизм внимания, который улучшает стандартное внимание с помощью обучаемого механизма управления. Во время прямого прохода SeerAttention входы Q (query) и K (key) объединяются и обрабатываются обучаемым механизмом управления, который адаптивно выделяет важные блоки, позволяя блочно-разреженному ядру внимания эффективно сокращать ввод-вывод и вычисления за счет пропуска незначимых блоков.
Во время обучения SeerAttention механизм управления учит разреженность внимания на уровне блоков, используя карту внимания, полученную из стандартного внимания. Однако FlashAttention (Dao et al., 2022), передовой механизм вычисления внимания, исключает явный вывод промежуточных карт внимания через слияние операций для повышения эффективности.
Это создает большие проблемы в процессе обучения, особенно в случаях с длинными контекстами, поскольку наивная реализация внимания медленная и требует много памяти. Для решения этой проблемы SeerAttention настраивает ядро FlashAttention для извлечения информации о целевых картах внимания на уровне блоков без сохранения исходной полной карты внимания. Эта новая реализация обеспечивает незначительные накладные расходы и значительно улучшает масштабируемость процесса обучения.
В статье оценивается SeerAttention в двух условиях: постобучение, где обучаются только параметры механизма управления с использованием небольшого набора данных для калибровки; и файн тюнинг - тонкая настройка, где одновременно оптимизируются как параметры механизма управления, так и веса оригинальной модели при расширении контекста. Результаты показывают, что SeerAttention превосходит современные методы разреженного внимания, такие как Minference (Jiang et al., 2024) и MoA (Fu et al., 2024).
Особенно важно, что в отличие от предыдущих методов, которые требуют тщательной калибровки разреженных конфигураций для разных условий, SeerAttention обладает высокой адаптивностью к различным длинам контекста и коэффициентам разреженности. Что еще более важно, внутренние возможности обучения SeerAttention позволяют достичь точности, близкой к полной, при 50% разреженности и минимальных потерь даже при 90% разреженности во время тонкой настройки на длинных контекстах.
Блочно-разреженное ядро также демонстрирует ускорение до 5,67 раз по сравнению с плотным базовым вариантом FlashAttention-2 при размере контекста 32k и разреженности 90%. Примечательно, что с разреженной картой внимания SeerAttention демонстрирует способность обучать более разнообразные шаблоны, включая A-образные и вертикальные слэши, что еще раз подтверждает его универсальность и эффективность.
Результат статьи можно подытожить следующим образом:
- SeerAttention, инновационный механизм внимания, который обучается и использует внутреннюю разреженность внимания для повышения эффективности длинных контекстов LLM.
- Разработано настроенное ядро FlashAttention, которое эффективно извлекает истинные данные о картах внимания на уровне блоков, что позволяет масштабируемое обучение разреженного внимания.
- Эксперименты показывают, что SeerAttention превосходит предыдущие подходы в постобучении, предлагает адаптивность к различным длинам контекста и коэффициентам разреженности и превосходит в тонкой настройке длинных контекстов, сохраняя точность даже при высоких уровнях разреженности.
Мотивация создания
Появление механизмов внимания, особенно в архитектуре трансформера (Vaswani, 2017), стало значительным шагом вперед в области обработки естественного языка. Механизм внимания позволяет лучше обрабатывать зависимости на больших расстояниях и лучше понимать контекст, уделяя внимание каждому токену в последовательности относительно всех других токенов, что приводит к квадратичной сложности по времени и памяти O(n²), где n — длина последовательности. Это представляет собой серьезную проблему, поскольку сообщество стремится к созданию LLM, способных обрабатывать все более длинные контексты. Многие исследования изучают альтернативные механизмы внимания для смягчения этой сложности. Архитектура Reformer (Kitaev et al., 2020) уменьшает сложность до O(n*log(n)), а механизм линейного внимания (Katharopoulos et al., 2020) снижает сложность до O(n). Недавно наблюдается тенденция возвращения к рекуррентным нейронным сетям, что привело к предложению новых архитектурных решений, таких как RWKV (Peng et al., 2023), RetNet (Sun et al., 2023) и Mamba (Gu & Dao, 2023). Несмотря на обещания эффективности, эти методы не могут полностью сравниться с производительностью полного внимания, особенно для более крупных моделей и длинных контекстов.
Внутренняя, но динамическая разреженность в механизме внимания
Механизмы внимания по своей природе обладают разреженностью, которая возникает в результате карты внимания 𝐴, генерируемой 𝐐 и 𝐊: 𝐴 = softmax(𝐐𝐊ᵀ / d).
Функция softmax часто выдает множество незначительных значений, которые можно трактовать как нули, не влияя на точность модели (Zaheer et al., 2020; Liu et al., 2021; Wang et al., 2021; Child et al., 2019).
Разреженность внимания становится более выраженной при увеличении длины контекста, что открывает возможности для оптимизации скорости вывода. К сожалению, эта разреженность динамична, варьируется в зависимости от разных входов и голов внимания, каждая из которых имеет различные места разреженности и коэффициенты.
Предыдущие исследования пытались аппроксимировать разреженность внимания с помощью заранее определенных шаблонов и эвристик (Fu et al., 2024; Jiang et al., 2024). Однако эти методы недостаточно универсальны и часто полагаются на ручные особенности, не в состоянии в полной мере захватить поведение разреженности в механизмах внимания.
Динамическая и зависимая от входных данных природа разреженности внимания перекликается с принципами моделей Mixture of Experts (MoE) (Shazeer et al., 2017; Fedus et al., 2022), что предполагает, что разреженность должна быть изучена напрямую из данных в самой модели. Такой подход позволит моделям адаптивно использовать разреженность, улучшая эффективность при сохранении точности.
SeerAttention
Seer Attention использует полностью основанный на обучении подход для адаптивного определения разреженности внимания в LLM и использует изученную разреженность для эффективного вывода. Чтобы обеспечить эффективность на современных аппаратных средствах, таких как GPU, исследователи фокусируются на обучении разреженности на уровне блоков, что может беспрепятственно интегрироваться с вычислительной схемой разбиения FlashAttention (Dao et al., 2022).
Рисунок 2 иллюстрирует общую архитектуру модели SeerAttention, которая дополняет обычное внимание обучаемым модулем управления, называемым Attention Gate (AttnGate). Этот модуль содержит обучаемые параметры, которые определяют расположение значимых блоков в картах внимания. Используя эти индексы блоков, последующие вычисления внимания могут использовать блочно-разреженное ядро FlashAttention, значительно улучшая производительность за счет сокращения накладных расходов на ввод/вывод и вычисления.
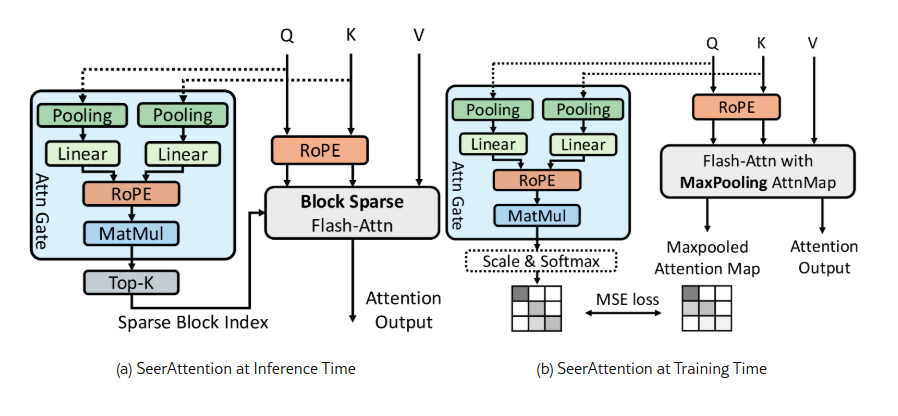
Рис.2. Архитектура SeerAttention. (a) SeerAttention включает в себя эффективный модуль *AttnGate* для адаптивного определения местоположений разреженных блоков на картах внимания. (b) Во время обучения SeerAttention использует максимально объединенную карту полного внимания в качестве наземной истины для управления *AttnGate*.
Модуль Attention Gate
Модуль AttnGate предназначен для обучения информации на уровне блоков с минимальными накладными расходами. Он принимает исходные матрицы 𝐐 и 𝐊 на входе и уменьшает их размер с помощью пулинга вдоль размерности последовательности. Как показано на Рисунке 2(a), для заданной головы внимания размеры уменьшенных 𝐐 и 𝐊 становятся [seq/B, d], где B — размер блока. Уменьшенные 𝐐 и 𝐊 затем обрабатываются через линейный слой и перемножаются, аналогично стандартной операции внимания. Это приводит к матрице размера [seq/B, seq/B], где каждый элемент соответствует одному блоку в полной карте внимания. При типичном размере блока 64 выход модуля AttnGate составляет всего 1/4096 от размера исходной карты внимания. Во время вывода, выбирая Top-k блоков в каждой строке, блочно-разреженное ядро FlashAttention может эффективно загружать и обрабатывать только активные блоки.
Выбор пулинга
В SeerAttention можно комбинировать различные методы пулинга для тензоров 𝐐 и 𝐊, в настоящее время поддерживаются комбинации среднего, максимального и минимального пулинга. Несколько операций пулинга могут быть применены к каждой матрице, а затем полученные уменьшенные матрицы конкатенируются перед тем, как попасть в линейный слой. Экспериментальные результаты показывают, что оптимальной комбинацией является использование среднего пулинга для 𝐐 и комбинации максимального и минимального пулинга для 𝐊 (подробности см. на Рисунке 10).
Дополнительный RoPE в Attention Gate
Современные LLM обычно используют RoPE (Su et al., 2024) для кодирования позиционной информации. Если AttnGate полагается только на оригинальный RoPE в модели, то есть, если в AttnGate подаются 𝐐 и 𝐊 после применения RoPE, свойства относительного позиционного кодирования будут утрачены из-за операции пулинга. Это компрометирует способность AttnGate экстраполировать на более длинные контексты во время обучения. В частности, если AttnGate обучается на последовательностях длиной 8k, он испытывает трудности с входами длиннее 16k. Чтобы решить эту проблему, мы вводим отдельный RoPE в рамках AttnGate. Этот RoPE может использовать параметры из исходного RoPE, но присваивает идентификаторы позиций, основываясь на стартовых позициях каждого блока. Это эквивалентно использованию уменьшенного угла вращения θ′=θ/B, но с кодированием позиции каждого блока.
Блочно-разреженное ядро вывода FlashAttention
Блочная разреженность официально не поддерживается в FlashAttention-2 (Dao, 2023), поэтому был реализовано блочно-разреженное ядро FlashAttention с использованием Triton (Tillet et al., 2019) для ускорения вывода SeerAttention. Оно использует аналогичный поток данных, как в FlashAttention-2, где 𝐐 разбивается по различным варпам. Каждый варп читает разреженные индексы блоков, сгенерированные AttnGate, и загружает соответствующие блоки 𝐊 и 𝐕 в кэш для вычислений. Этот подход эффективно снижает как накладные расходы на ввод/вывод, так и вычислительные затраты, пропуская неактивные блоки.
Обучение SeerAttention
Хотя архитектура SeerAttention достаточно простая, ее обучение является сложной задачей. Совместное обучение модуля управления (gate) и внимания с нуля, как в MoE, является затратным и трудным процессом. К счастью, в отличие от MoE, где сеть управления должна учить выбор экспертов с нуля, AttnGate в Seer Attention имеет истинные данные в стандартном внимании для направления обучения.
Обучение Attention Gate
Обучаем AttnGate для изучения разреженности на уровне блоков, используя 2D карту внимания с максимальным пулингом из полного внимания в качестве истинных данных, как показано на Рисунке 2. Для выравнивания распределений выход AttnGate масштабируется и проходит через softmax, аналогично стандартным механизмам внимания. Кроме того, карта внимания с максимальным пулингом нормализуется по строкам, чтобы сумма всех элементов в строке была равна 1, что соответствует выходу softmax. В процессе обучения используется ошибка среднеквадратичного отклонения (MSE). Эта авто-регрессионная схема обучения также позволяет гибко использовать Seer Attention, давая пользователям возможность регулировать соотношение Top-k для баланса точности и эффективности с помощью одной модели.
FlashAttention с максимальным пулингом: кастомизированное ядро для обучения
Получение карты внимания с максимальным пулингом для обучения — не тривиальная задача, особенно в сценариях с длинным контекстом. Современные LLM полагаются на FlashAttention, который объединяет операции и не вычисляет явным образом карту внимания. Наивная реализация с вручную прописанным кодом непрактична из-за квадратичной сложности памяти. Для решения этой проблемы кастомизировали эффективное ядро, которое непосредственно выводит карту внимания с максимальным пулингом, модифицируя FlashAttention, но в значительной степени повторно используя его исходный поток вычислений. Рисунок 3 показывает псевдокод и диаграмму этого кастомизированного ядра.
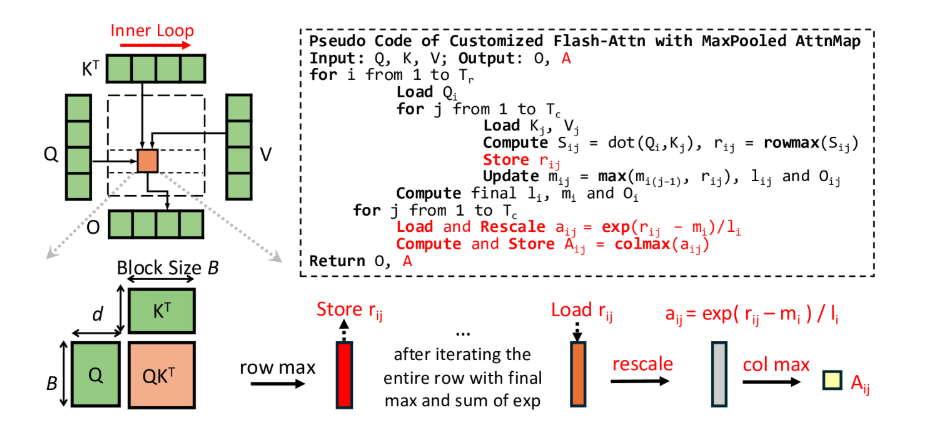
Рис.3. Эффективное ядро FlashAttention с пулингом карты внимания.
Обычно функция softmax обеспечивает числовую стабильность, вычитая максимальное значение перед применением экспоненциальной операции. FlashAttention вычисляет локальное максимальное значение по строкам каждого блока и постепенно обновляет глобальное максимальное значение через итерации:
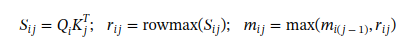
где ri,j считается временным результатом. Однако мы сохраняем его в HBM и позже масштабируем с использованием итогового глобального максимума mi и суммы exp(li) после итерации:
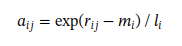
Где ai,j представляет собой правильное локальное максимальное значение оригинального блока внимания. Таким образом, достигается 2D максимальный пулинг путем применения максимума по столбцам над ai,j. Это влечет лишь незначительные накладные расходы (сохранение и масштабирование ri,j), но значительно улучшает эффективность получения истинных данных.
Подробный код доступен в Приложении A, а анализ накладных расходов приведен на Рисунке 8.
Применение SeerAttention на этапах пост-тренировки и тонкой настройки
Пост-тренировка
Можно напрямую применять SeerAttention к предварительно обученной модели. В этом случае обучаются и обновляются только веса AttnGate, а исходные веса модели остаются неизменными. Этот метод является высокоэффективным и экономичным, так как требует вычисления градиентов только для AttnGate и быстро сходится при использовании минимального объема данных для калибровки. Обученный гейт также позволяют регулировать коэффициенты Top-k во время вывода, предоставляя гибкий компромисс между точностью и эффективностью.
Файн тюнинг
SeerAttention также может быть применен для файнтюнинга модели с увеличением длины контекста, что обеспечивает улучшение производительности модели и более высокие коэффициенты разреженности. На практике для обеспечения стабильной тренировки AttnGate сначала инициализируется методом пост-тренировки, после чего доучивается вся модель. В процессе тонкой настройки фиксируют коэффициент Top-k и используют как исходную функцию потерь, так и регуляризацию в виде функции потерь MSE для карты внимания.
Эксперименты
Была оценена точность и эффективность SeerAttention. Точность проверяется в двух различных сценариях:
- (1) этап пост-тренировки
- (2) этап тонкой настройки с расширением длины контекста.
Для оценки эффективности представлены результаты ускорения на уровне ядра и от начала до конца для различных конфигураций разреженности.
В проведенных экспериментах размер блока B для модели и ядра фиксирован на уровне 64, а AttnGate применяется исключительно на этапе предзаполнения.
Модели, задачи и базовые методы
Исследователи применяют SeerAttention к предварительно обученным моделям Llama-3.1-8B (Dubey и др., 2024) и Mistral-7B-v0.3 (Jiang и др., 2023), чтобы оценить его влияние на перплексию моделей при различных дизайнах AttnGate и конфигурациях разреженности. Для оценки перплексии используются тестовые выборки PG19 (Rae и др., 2019) и Proof-pile (Azerbayev и др.). В соответствии с YaRN (Peng и др., 2024), из Proof-pile выбираются 10 документов объемом более 128k токенов, а из PG19 отбираются все документы, превышающие 128k токенов. Входные последовательности обрезаются до длины контекста перед подачей в модель.
Также проводятся эксперименты с моделью, настроенной на выполнение инструкций, Llama-3.1-8B-Instruct, и сравнение SeerAttention с двумя современными методами разреженного внимания — MoA (Fu и др., 2024) и MInference (Jiang и др., 2024) на бенчмарке LongBench (Bai и др., 2023), включая показатели перплексии и эффективности. MoA использует поиск для применения статических разреженных шаблонов в различных головах внимания, тогда как MInference динамически генерирует разреженные индексы с помощью эвристических методов для каждой головы на основе предопределенных шаблонов разреженности.
Post-training Setup
Для калибровки используется датасет RedPajama (Computer, 2023), разбитый на сегменты по 64k и 32k для Llama-3.1 и Mistral соответственно. Применяется скорость обучения 1×10−3 с косинусным снижением learning rate и глобальный размер батча 16.
AttnGate обучается за 500 шагов с использованием истинных значений из кастомизированного ядра FlashAttention и оптимизацией DeepSpeed (Rasley и др., 2020) stage 2 на 4 GPU A100. Так как обновляются только параметры AttnGate, этот процесс завершается в течение нескольких часов.
Fine Tuning на расширение контекста
Контекст модели Llama-3.1-8B расширяется с 8K до 32K, согласно настройкам YaRN (Peng и др., 2024), с введением разреженности внимания через SeerAttention. Во время прямого прохода число Top-k в AttnGate фиксируется, чтобы модель могла адаптироваться к разреженности. Скорость обучения составляет 1×10−5 с линейным спадом, а глобальный размер батча равен 8. Обучение всех весов модели проводится на 4 GPU A100 с использованием оптимизации DeepSpeed stage 3.
Точность после обучения
Перплексия на предварительно обученных моделях.
На рисунке 4 представлены результаты перплексии на наборе данных Proof-pile для моделей Llama-3.1-8B и Mistral-7B-v0.3 при различных длинах контекста и коэффициентах разреженности. Следует отметить, что результаты для каждой модели получены из одного и того же чекпоинта с обученными AttnGates, а различные коэффициенты разреженности достигаются путем изменения значения k в отборе Top-k.
Результаты показывают, что SeerAttention лишь незначительно увеличивает перплексию при увеличении разреженности по сравнению с полной матрицей внимания. Например, для модели Mistral-7B с размером контекста 32k SeerAttention достигает перплексии 2,45, по сравнению с базовым значением 2,29, несмотря на значительную разреженность внимания в 90%. Рисунок 4 также демонстрирует, что более длинные контексты позволяют использовать большую разреженность с минимальным ухудшением точности.
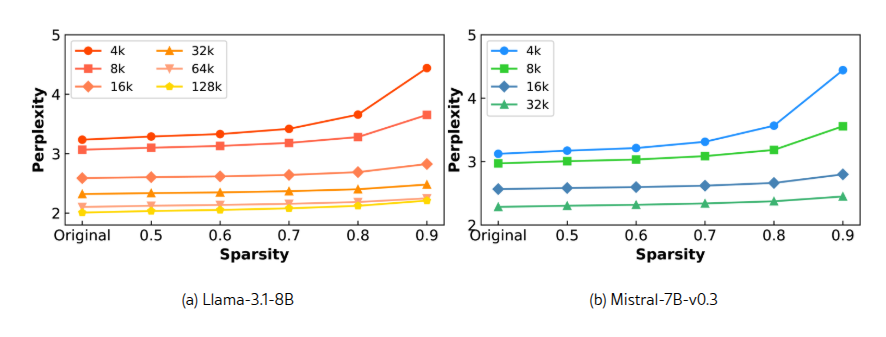
Рис.4. Результаты перплексии на наборе данных Proof-pile при различных длинах контекста и коэффициентах разреженности. Отметим, что результаты для различных коэффициентов разреженности получены с использованием одних и тех же обученных AttnGates путем изменения значения k в методе Top-k. Более длинные контексты позволяют достигать большей разреженности при минимальной потере производительности.
Сравнение перплексии с аналогичными методами.
В таблице 1 представлено сравнение перплексии SeerAttention после обучения с MoA и MInference, используя модель Llama-3.1-8B-Instruct на наборе данных PG19. Для MoA используется их метод "KV Sparsity" со значением 0.5, что эквивалентно "Attention Sparsity" со значением 0.35. Для MInference применяется их официальная настройка, где все головы внимания используют шаблон разреженности "Vertical-Slash" для Llama-3.1-8B-Instruct. Поскольку MInference динамически генерирует разреженные индексы для каждого входа, для сравнения учитывалась их средняя разреженность внимания при разных длинах контекста.
SeerAttention превосходит MoA и MInference даже при более высокой разреженности в большинстве случаев, за исключением длины контекста 128k. Это, вероятно, связано с тем, что MInference использует изменяющуюся разреженность для каждой головы внимания, в то время как SeerAttention применяет фиксированный коэффициент разреженности ко всем головам. Применение изменяющейся разреженности для каждой головы в SeerAttention может улучшить результаты, что остается темой для будущих исследований.
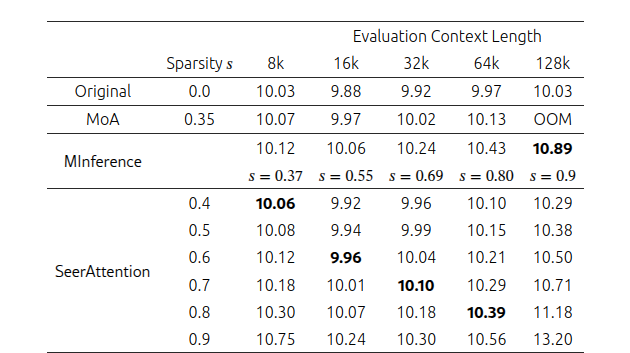
Таблица 1. Сравнение перплексии SeerAttention после обучения с MoA и MInference, используя модель Llama-3.1-8B-Instruct на наборе данных PG19.
Оценка на LongBench.
Для оценки производительности на задачах, связанных с выполнением инструкций, мы проводим эксперименты на LongBench, тестовом наборе для понимания длинных контекстов, и сравниваем результаты с MoA и MInference, используя модель Llama-3.1-8B-Instruct. Как показано в таблице 2, SeerAttention стабильно превосходит как MoA, так и MInference при аналогичных или более высоких коэффициентах разреженности.
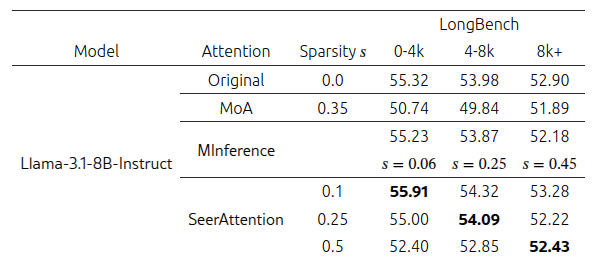
Таблица 2. Сравнение точности SeerAttention после обучения с MoA и MInference на наборе LongBench.
Точность дообучения с расширением длины контекста
Согласно подходу YaRN (Peng и др., 2024) для увеличения размера контекста модели Llama-3-8B с 8k до 32k. SeerAttention интегрируется в YaRN, и результаты сравниваются с базовым dense вариантом YaRN и SeerAttention, примененным после дообучения в YaRN.
На рисунке 1(a) показаны кривые потерь для базового dense варианта YaRN и SeerAttention с разреженностью 50% и 90%. Кривая при разреженности 50% почти полностью совпадает с базовой, тогда как при разреженности 90% наблюдается небольшое увеличение потерь.
В таблице 3 представлены результаты тестовой перплексии на наборах данных PG19 и ProofPile при длине контекста 32k. Плотный базовый вариант YaRN достигает перплексии 8.79 и 2.46 соответственно. SeerAttention, применяемый после обучения, увеличивает значения перплексии. Однако использование SeerAttention во время дообучения с расширением контекста в YaRN сохраняет практически безпотерьную производительность при разреженности 50% (с результатами 8.81 и 2.47) и минимальные потери даже при разреженности 90%.

Таблица 3. Перплексия для базового варианта YaRN, SeerAttention после YaRN и YaRN с интегрированным SeerAttention.
Оценка эффективности
Эффективность SeerAttention оценивается с использованием авторской реализации ядер Triton (Tillet и др., 2019). Производительность анализируется как на уровне ядер, так и для полного процесса выполнения на модели Llama-3.1-8B-Instruct на одном графическом процессоре A100. Результаты сравниваются с FlashAttention-2 (плотный базовый вариант), MoA и MInference.
Оценка ядер
Незначительные накладные расходы AttnGate и Top-k.
На рисунке 5 представлено разбиение задержки SeerAttention на уровне ядер. Показано, что нагрузка, вызванная операциями AttnGate и Top-k во время выполнения, минимальна. Например, при длине контекста 32k и разреженности 0.5 вклад AttnGate и Top-k составляет всего 1% и 2% от общей задержки выполнения соответственно. При длине последовательности 128k дополнительная нагрузка практически исчезает.
Ускорение с использованием блочно-разреженного ядра FlashAttention.
Рисунок 5 также демонстрирует, что SeerAttention ядро обеспечивает линейное ускорение на различных уровнях разреженности. При длине последовательности 128k и разреженности 90% SeerAttention достигает ускорения в 5.47x по сравнению с FlashAttention-2 на одном графическом процессоре A100. Хотя текущая реализация основана на Triton, дальнейшее увеличение производительности возможно за счет оптимизации ядра с использованием CUDA в будущем.
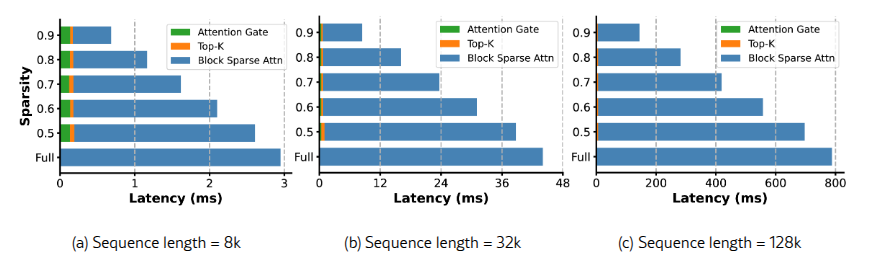
Рис. 5. Разбиение времени выполнения SeerAttention по сравнению с FlashAttention-2. При длине последовательности 128k и коэффициенте разреженности 90% SeerAttention ускоряет вычисление внимания в 5.47x по сравнению с FlashAttention-2.
Сравнение с похожими подходами
Сравнивнение ускорения SeerAttention с MoA и MInference. MInference использует офлайн-калибровку для определения заранее заданного разреженного шаблона для каждого слоя. Для модели Llama-3.1-8B-Instruct MInference стабильно использует шаблон "Vertical-slash" для всех слоев. Во время выполнения MInference динамически генерирует ненулевые индексы на основе их алгоритма аппроксимации. С другой стороны, MoA использует блоки в форме "A" как разреженный шаблон и проводит калибровку параметров формы офлайн в условиях заданной разреженности.
Рисунок 6 показывает графики зависимости разреженности от ускорения для различных методов при длинах последовательности 8k, 32k и 128k, где базой для ускорения является FlashAttention-2. Статистика по разреженности была собрана на наборе данных PG19. Для MoA мы сгенерировали разреженные конфигурации в рамках их 0.5 общей разреженности "KV-sparsity", что соответствует среднему значению разреженности 0.35 для внимания. Результаты показывают, что SeerAttention превосходит как MoA, так и MInference в большинстве случаев. При длине последовательности 128k производительность всех трех методов сходится, где преимущества разреженности значительно перевешивают связанные с этим накладные расходы.
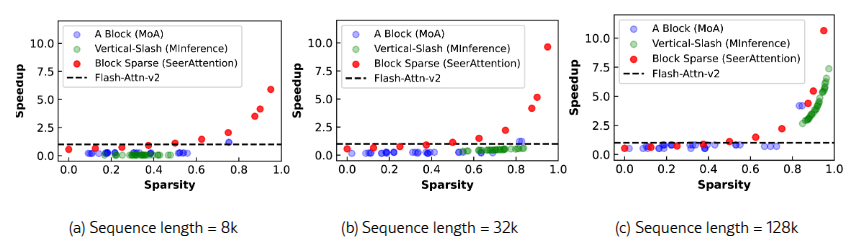
Рис 6. Ускорение инференсного ядра SeerAttention с блочно-разреженной версией FlashAttention.
Общее ускорение
Для оценки общего ускорения метода измерили среднее время предварительного заполнения, или время до первого токена (TTFT), используя модель Llama-3.1-8B-Instruct. Следуя экспериментальной настройке, использованной в MoA, также записали среднюю статистику по разреженности для каждого метода. Результаты показывают, что SeerAttention стабильно достигает более низкой задержки по сравнению с MInference, даже при более низких коэффициентах разреженности. Что касается MoA, то для поиска различных разреженных конфигураций при изменяющихся ограничениях разреженности требуется исчерпывающий поиск, что занимает много времени. Поэтому сравнивали SeerAttention только с его стандартной конфигурацией.
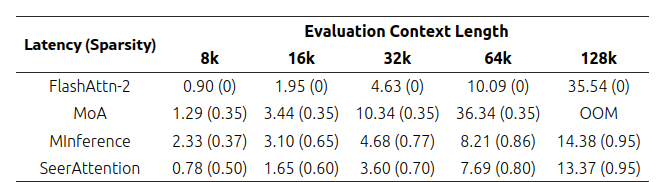
Табл. 4. Результаты Time to First Token (TTFT) (в секундах).
Анализ и исключающие исследования (Ablation study)
Визуализация обученных карт внимания.
Модуль AttnGate автоматически обучает различные разреженные шаблоны без предварительных знаний или эвристик. Рисунок 7 показывает несколько примеров выводов от AttnGate, включая (a) "A-форма", (b) "Вертикальный", (c) "Косая" с пустыми вертикальными пространствами, (d) блочную разреженность вдоль диагонали и (e) случайные шаблоны. Эти шаблоны не только охватывают, но и выходят за пределы тех, что были замечены в предыдущих работах, таких как MoA и MInference, демонстрируя универсальность методов, основанных на обучении.
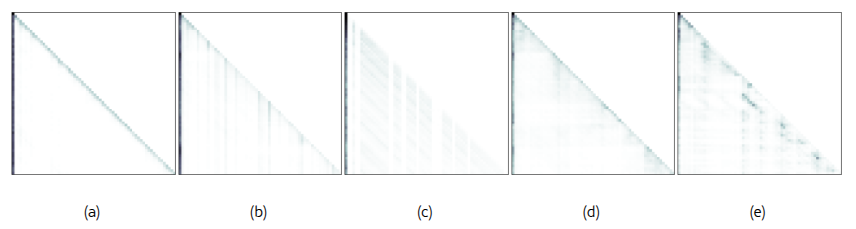
Рис. 7. Визуализация выводов AttnGate.
Анализ FlashAttention с ядром обучения Max-Pooling.
Оценивается кастомизированное ядро FlashAttention с картой внимания maxpooling для масштабируемого обучения SeerAttention, в сравнении с наивной ручной реализацией внимания на PyTorch и FlashAttention-2. Как показано на рисунке 8(b), ядро PyTorch выходит из памяти (OOM), когда длина последовательности превышает 4k, в то время как кастомизированное ядро использует похожее пиковое потребление памяти по сравнению с FlashAttention-2. Что касается задержки, поскольку PyTorch сталкивается с OOM для последовательностей длиннее 8k, операции внимания для каждой головы попадают в цикл для оценки задержки на уровне ядер. Рисунок 8(b) показывает, что накладные расходы на задержку, вызванные дополнительной операцией пулинга, минимальны по сравнению с FlashAttention-2, в то время как реализация на PyTorch страдает от значительного замедления.
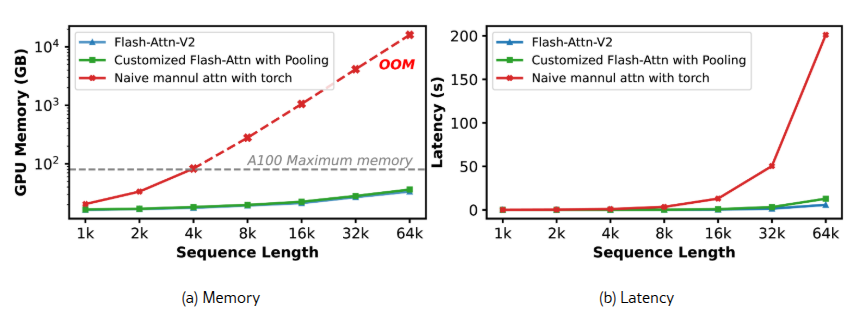
Рис 8. Память и латентность кастомизированного ядра FlashAttention с обучением max-pooling.
Абляция RoPE
В ходе экспериментов было установлено, что добавление дополнительного модуля RoPE в AttnGates, как показано на рисунке 2, значительно улучшает способность модели экстраполировать длину контекста при обучении AttnGates. Рисунок 9 показывает результаты с и без RoPE в AttnGate на PG19 с моделью Llama-3.1-8B, используя данные для обучения длиной 8k. AttnGate с RoPE демонстрирует очень стабильные результаты на больших длинах контекста, несмотря на то, что обучался только на данных длиной 8k.
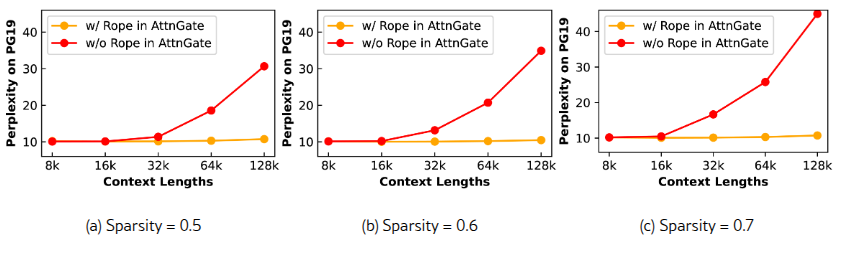
Рис. 9. Перплексия с RoPE и без в AttnGate.
Абляция Pooling
В AttnGates могут быть использованы различные методы пуллинга. Чтобы изучить лучшую конфигурацию, тестируются все возможные комбинации пуллинга в 𝐐 и 𝐊, выбирая из среднего, максимального и минимального пуллинга. Всего рассматривается 49 комбинаций. Каждая конфигурация обучается в постобучении с использованием модели Llama-3.1-8B на данных длиной 32k и тестируется на значение перплексии с использованием набора данных PG19 при длине контекста для оценки 128k. Рисунок 10 показывает 12 лучших конфигураций. Конфигурация с усреднением для 𝐐 и максимальным и минимальным пуллингом для 𝐊 показала лучшие результаты. Это может быть связано с наблюдениями в квантовании LLM, где 𝐊 часто имеет больше выбросов.

Рис. 10. Перплексия SeerAttention с различными методами пуллинга.
Заключение и направления для будущих исследований
В данной работе представлен SeerAttention — новая механика внимания, которая учит и использует внутреннюю разреженность во внимании для улучшения работы с длинными контекстами в LLM. Эксперименты показали, что SeerAttention не только превосходит предыдущие подходы в сценариях постобучения, но и демонстрирует отличные результаты в дообучении с длинными контекстами, сохраняя точность почти без потерь, даже при высоких уровнях разреженности.
Для будущих исследований существует несколько перспективных направлений для улучшения и расширения возможностей SeerAttention. Одним из ключевых направлений является улучшение методов обучения SeerAttention, например, использование SeerAttention для продолженного предобучения с длинными контекстами с большим количеством тренировочных токенов для достижения более высокой разреженности без потери точности. Другим важным направлением является применение SeerAttention на стадии генерации в LLM. Хотя данная работа в основном фокусируется на фазе предварительного заполнения, остается открытым вопрос, может ли изученная разреженность внимания аналогично улучшить эффективность и точность процесса инференса.
Упоминаемые работы
Zhangir Azerbayev, Edward Ayers, and Bartosz Piotrowski.Proof-pile: A dataset for long-form theorem proving.https://github.com/zhangir-azerbayev/proof-pile. Bai et al. (2023)
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li.Longbench: A bilingual, multitask benchmark for long context understanding.arXiv preprint arXiv:2308.14508, 2023.
Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever.Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019.
Computer (2023) Together Computer.Redpajama: an open dataset for training large language models, 2023.URL https://github.com/togethercomputer/RedPajama-Data.
Dao (2023) Tri Dao.Flashattention-2: Faster attention with better parallelism and work partitioning.2023.URL https://arxiv.org/abs/2307.08691.
Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré.Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al.The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024.
Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer.Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022.
Fu et al. (2024) Tianyu Fu, Haofeng Huang, Xuefei Ning, Genghan Zhang, Boju Chen, Tianqi Wu, Hongyi Wang, Zixiao Huang, Shiyao Li, Shengen Yan, et al.Moa: Mixture of sparse attention for automatic large language model compression.arXiv preprint arXiv:2406.14909, 2024.
Gu & Dao (2023) Albert Gu and Tri Dao.Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023. Han et al. (2023) Insu Han, Rajesh Jayaram, Amin Karbasi, Vahab Mirrokni, David P Woodruff, and Amir Zandieh.Hyperattention: Long-context attention in near-linear time.arXiv preprint arXiv:2310.05869, 2023.
Jiang et al. (2023) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al.Mistral 7b.arXiv preprint arXiv:2310.06825, 2023.
Jiang et al. (2024) Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al.Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.arXiv preprint arXiv:2407.02490, 2024.
Katharopoulos et al. (2020) Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret.Transformers are rnns: Fast autoregressive transformers with linear attention.In International conference on machine learning, pp. 5156–5165. PMLR, 2020.
Kitaev et al. (2020) Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya.Reformer: The efficient transformer.arXiv preprint arXiv:2001.04451, 2020.
Lee et al. (2024) Heejun Lee, Geon Park, Youngwan Lee, Jina Kim, Wonyoung Jeong, Myeongjae Jeon, and Sung Ju Hwang.Hip attention: Sparse sub-quadratic attention with hierarchical attention pruning.arXiv preprint arXiv:2406.09827, 2024.
Liu et al. (2021) Liu Liu, Zheng Qu, Zhaodong Chen, Yufei Ding, and Yuan Xie.Transformer acceleration with dynamic sparse attention.arXiv preprint arXiv:2110.11299, 2021.
Peng et al. (2023) Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, et al.Rwkv: Reinventing rnns for the transformer era.arXiv preprint arXiv:2305.13048, 2023.
Peng et al. (2024) Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole.YaRN: Efficient context window extension of large language models.In The Twelfth International Conference on Learning Representations, 2024.URL https://openreview.net/forum?id=wHBfxhZu1u.
Rae et al. (2019) Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap.Compressive transformers for long-range sequence modelling.arXiv preprint arXiv:1911.05507, 2019.
Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He.Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters.In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, pp. 3505–3506, New York, NY, USA, 2020. Association for Computing Machinery.ISBN 9781450379984.doi: 10.1145/3394486.3406703.URL https://doi.org/10.1145/3394486.3406703.
Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean.Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017.
Su et al. (2024) Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu.Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024.
Sun et al. (2023) Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei.Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023.
Tillet et al. (2019) Philippe Tillet, Hsiang-Tsung Kung, and David Cox.Triton: an intermediate language and compiler for tiled neural network computations.In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pp. 10–19, 2019.
Vaswani (2017) A Vaswani.Attention is all you need.Advances in Neural Information Processing Systems, 2017. Wang et al. (2021) Hanrui Wang, Zhekai Zhang, and Song Han.Spatten: Efficient sparse attention architecture with cascade token and head pruning.In 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pp. 97–110. IEEE, 2021.
Zaheer et al. (2020) Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al.Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020.
Zhu et al. (2024) Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, et al.Near-lossless acceleration of long context llm inference with adaptive structured sparse attention.arXiv preprint arXiv:2406.15486, 2024.
Приложение A

Customized FlashAttention with Max-pooling Kernel