SWE-bench - Могут ли языковые модели решить реальные проблемы GitHub?
Перевод на основе https://arxiv.org/abs/2310.06770 от 11 ноября 2024.
Развитие языковых моделей опережает нашу способность эффективно их оценивать, но для их дальнейшего прогресса крайне важно изучать границы их возможностей. Мы считаем, что реальная разработка программного обеспечения — это богатая, устойчивая и сложная тестовая площадка для оценки нового поколения языковых моделей. С этой целью мы представляем SWE-bench — платформу для оценки, включающую 2294 задачи по программной инженерии, основанные на реальных проблемах из GitHub и соответствующих pull request'ах в 12 популярных Python-репозиториях.
Модели получают исходный код и описание проблемы, которую необходимо решить, и должны отредактировать код, чтобы устранить её. Решение задач в SWE-bench часто требует понимания и координации изменений в нескольких функциях, классах и даже файлах одновременно. Это требует от моделей взаимодействия с исполнительными средами, обработки чрезвычайно длинных контекстов и выполнения сложных рассуждений, выходящих далеко за рамки традиционных задач генерации кода.
Наши оценки показывают (на 11 ноября 2024), что даже передовые проприетарные модели и наша дообученная модель SWE-Llama способны решить только самые простые задачи. Лучшая модель, Claude 2, справляется лишь с 1,96% проблем. Прогресс в решении задач SWE-bench — это шаг к созданию более практичных, интеллектуальных и автономных языковых моделей.
Введение
Языковые модели (LLM) активно внедряются в коммерческие продукты, такие как чат-боты и помощники по программированию. Вместе с тем, существующие бенчмарки стали насыщенными (Kiela et al., 2021; Ott et al., 2022) и не отражают реальных возможностей и ограничений современных LLM. Возникает необходимость в сложных бенчмарках, которые точнее моделируют реальные применения LLM и помогают формировать их будущее развитие и использование (Srivastava et al., 2023).
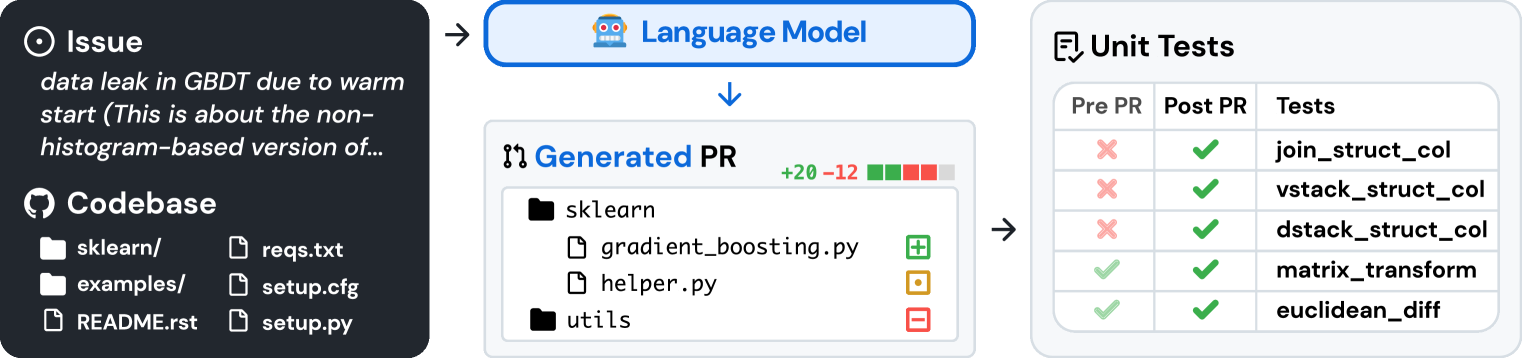
Рис. 1. SWE-bench формирует задачи на основе реальных Python-репозиториев, связывая проблемы из GitHub с решениями в виде принятых pull request'ов, которые проходят соответствующие тесты. Моделям предоставляется текст проблемы и снимок кода, и они генерируют патч, который оценивается с помощью реальных тестов.
Создание качественного бенчмарка — сложная задача: задачи должны быть достаточно трудными, чтобы современные модели не могли их легко решить, но при этом решения моделей должны легко проверяться (Martínez-Plumed et al., 2021). Задачи по программированию привлекательны, так как они ставят сложные проблемы перед LLM, а сгенерированные решения можно легко проверить, запустив юнит-тесты. Однако существующие бенчмарки, такие как HumanEval (Chen et al., 2021), в основном включают самодостаточные задачи, решаемые несколькими строками кода.
В реальном мире разработка программного обеспечения гораздо сложнее. Исправление ошибки может потребовать навигации по большому репозиторию, понимания взаимодействия функций в разных файлах или поиска мелкой ошибки в запутанном коде. Вдохновившись этим, мы представляем SWE-bench — бенчмарк, оценивающий LLM в реалистичных условиях разработки. Как показано на рисунке 1, модели должны решать задачи (обычно это отчёты об ошибках или запросы на добавление функционала), отправленные в популярные репозитории GitHub. Каждая задача требует генерации патча с изменениями для существующего кода. Исправленный код затем оценивается с помощью тестовой инфраструктуры репозитория.
SWE-bench имеет несколько преимуществ перед существующими бенчмарками для программирования:
- Реалистичная среда с использованием реальных проблем и решений, предложенных пользователями.
- Разнообразные задачи с уникальными проблемами из 12 репозиториев.
- Надёжная система оценки на основе выполнения тестов.
- Возможность непрерывного обновления бенчмарка новыми задачами с минимальным участием человека.
Мы оценили несколько современных ЛМ на SWE-bench и выяснили, что они не справляются со всеми задачами, кроме самых простых. Используя BM25 для поиска релевантной информации, модель Claude 2 смогла решить только 1,96% задач.
Помимо SWE-bench, мы также выпустили обучающий набор данных SWE-bench-train, который необходим для развития открытых моделей в этой сложной области. Набор включает 19 000 задач (не связанных с тестированием) из 37 репозиториев. На основе SWE-bench-train мы выпустили две дообученные модели — SWE-Llama 7b и 13b, основанные на модели CodeLlama (Rozière et al., 2023). Мы обнаружили, что в некоторых условиях SWE-Llama 13b конкурирует с Claude 2 и способна обрабатывать контексты длиной более 100 000 токенов.
Конструкция бенчмарка
GitHub — это богатый источник данных для разработки программного обеспечения, но репозитории, задачи и pull request'ы могут быть шумными, неструктурированными или плохо документированными. Чтобы найти качественные задачи в большом объёме, мы используем трёхэтапный процесс:

Рис. 2. SWE-bench формирует задачи на основе принятых pull request'ов, которые решают проблему, добавляют тесты и успешно устанавливаются.
Этап I: Выбор репозиториев и сбор данных
Мы начинаем со сбора pull request'ов (PR) из 12 популярных открытых Python-репозиториев на GitHub, что даёт около 90 000 PR. Мы фокусируемся на популярных репозиториях, так как они, как правило, лучше поддерживаются, имеют чёткие правила для участников и более полное покрытие тестами. Каждый PR связан с определённой версией кода, зафиксированной в базовом коммите.
Этап II: Фильтрация по атрибутам
Мы отбираем кандидатов в задачи, выбирая принятые PR, которые:
- Решают существующую задачу (issue) на GitHub.
- Вносят изменения в тестовые файлы репозитория, что указывает на добавление тестов для проверки решения проблемы.
Этап III: Фильтрация на основе выполнения
Для каждого кандидата мы:
- Применяем тесты из PR.
- Фиксируем результаты тестов до и после применения остальных изменений из PR.
- Исключаем задачи, в которых нет хотя бы одного теста, который изменил статус с "неудача" на "успех" (далее — fail-to-pass тесты).
- Также исключаем задачи, которые приводят к ошибкам установки или выполнения.
В результате трёхэтапной фильтрации из первоначальных 90 000 PR остаётся 2 294 задачи, которые составляют бенчмарк SWE-bench. Распределение задач по репозиториям представлено на Рисунке 3, а в Таблице 1 выделены ключевые характеристики задач SWE-bench. Отметим, что кодовые базы в задачах объёмные — тысячи файлов, а эталонные PR часто вносят изменения сразу в несколько файлов.
Подробности о процессе создания SWE-bench обсуждаются в Приложении A, а дополнительная статистика набора данных приведена в Приложении A.5.
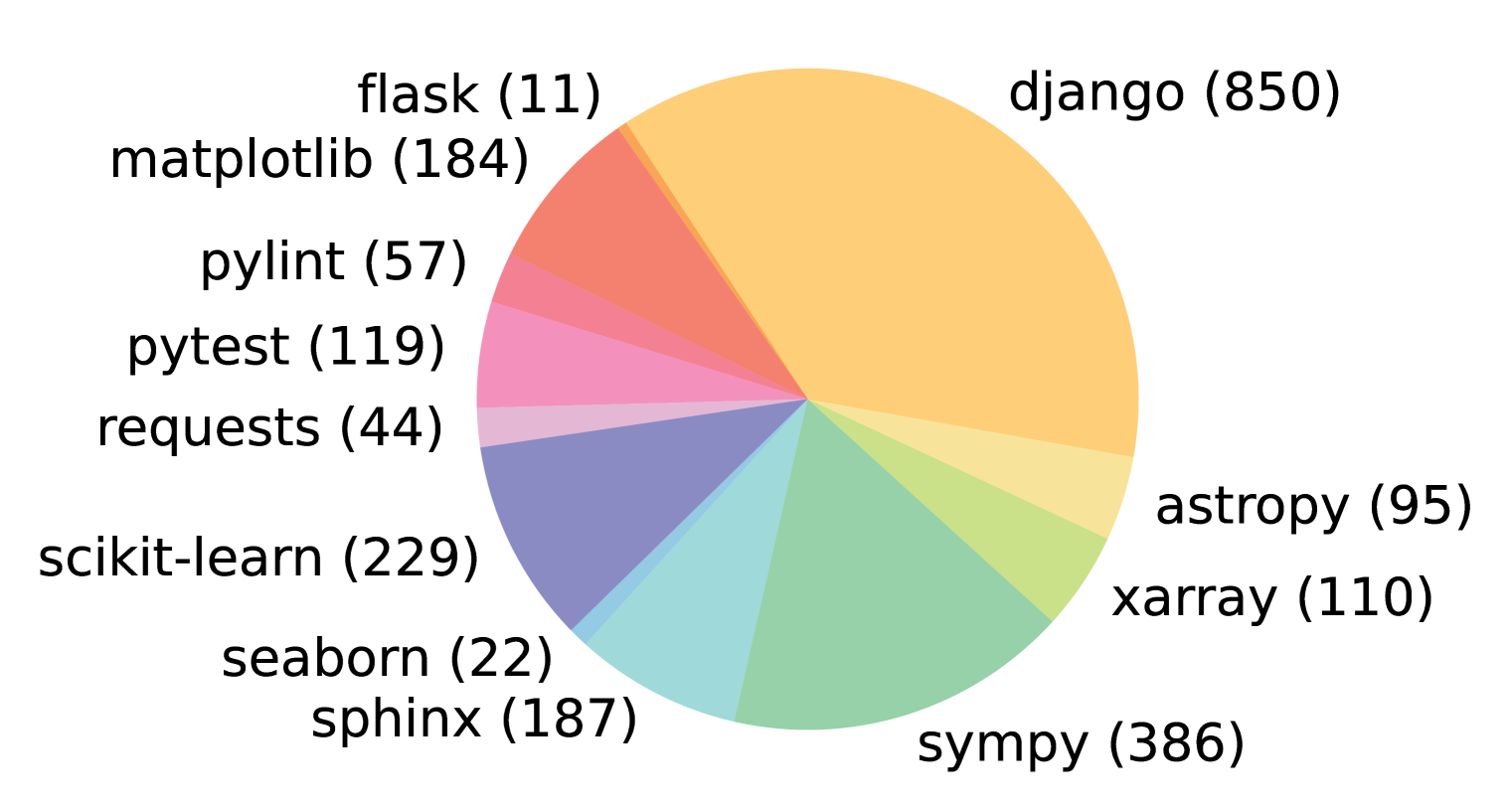
Рис. 3. Распределение задач SWE-bench (в скобках) по 12 открытым репозиториям GitHub, каждый из которых содержит исходный код популярного и часто скачиваемого пакета PyPI.
Формулировка задачи
Входные данные для модели.
Модели предоставляется текстовое описание задачи (issue) и полная кодовая база. Задача модели — внести изменения в кодовую базу, чтобы решить проблему. На практике изменения представляются в виде патчей — файлов, которые указывают, какие строки в коде необходимо изменить для решения задачи.
Метрики оценки.
Для оценки предложенного решения мы применяем сгенерированный патч к кодовой базе с помощью утилиты patch из Unix, а затем запускаем связанные с задачей юнит-тесты и системные тесты. Если патч применяется успешно и все тесты проходят, мы считаем, что предложенное решение успешно решило задачу. Основная метрика бенчмарка — процент успешно решённых задач. Дополнительные технические детали приведены в Приложении A.4.
Лирическое отступление об утилите Patch - ее силе и возможностях
Утилита patch в Unix-подобных системах — это мощный инструмент для применения изменений к файлам на основе дифф-файлов (diff files). Она позволяет обновлять исходный код, конфигурационные файлы и другие текстовые документы, не перезаписывая их целиком, а применяя только различия.
Зачем нужна patch?
patch используется, чтобы:
- Применять исправления (патчи) к исходному коду.
- Обновлять файлы без необходимости замены их целиком.
- Распространять изменения в виде небольших текстовых файлов (например, в open-source проектах).
- Автоматизировать процесс внесения изменений (в CI/CD, сборках и т.п.).
Она особенно популярна в мире open-source, где разработчики отправляют патчи по электронной почте или через системы управления версиями.
patch работает в паре с утилитой diff. Сначала вы используете diff, чтобы создать файл с описанием изменений между двумя версиями файла. Затем patch применяет эти изменения к исходному файлу.
Связка diff → patch
-
Есть два файла:
- original.txt — старая версия
- modified.txt — новая версия
-
Создаём патч:
diff original.txt modified.txt > changes.patch -
Применяем патч:
patch original.txt < changes.patchПосле этого
original.txtстанет идентичнымmodified.txt.
Форматы патчей
patch поддерживает несколько форматов вывода diff, но чаще всего используются:
- Обычный diff (normal) — простой, но не всегда однозначный.
- Контекстный diff (
-c) — показывает контекст вокруг изменений. - Unified diff (
-u) — самый популярный, компактный и читаемый.
Пример: Unified diff
diff -u original.txt modified.txt > patch.diffСодержимое patch.diff может выглядеть так:
--- original.txt 2025-04-05 10:00:00.000000000 +0300
+++ modified.txt 2025-04-05 10:05:00.000000000 +0300
@@ -1,5 +1,5 @@
Привет, мир!
Это старый файл.
-Строка удалена.
+Строка добавлена.
Ещё одна строка.
Конец.Разбор:
---— старый файл+++— новый файл@@ -1,5 +1,5 @@— указывает, какие строки изменяются:-1,5— начиная со строки 1, 5 строк из старого файла+1,5— начиная со строки 1, 5 строк в новом файле
- Строки с
-— удалены - Строки с
+— добавлены
Как применяется патч?
Команда:
patch original.txt < patch.diffили
patch -i patch.diff original.txtpatch:
- Читает заголовок (
---,+++) - Находит соответствующий файл (или использует имя из заголовка)
- Ищет контекст вокруг изменений (строки без
+/-) - Проверяет, совпадает ли контекст в текущем файле
- Если да — применяет изменения
- Если нет — может попытаться "приблизительно" найти место (с фуззингом)
Если всё прошло успешно:
patching file original.txtПример 1: Простое изменение строки
Файл hello.txt (оригинал):
Hello, world!
This is version 1.
Goodbye!Файл hello_new.txt (новый):
Hello, world!
This is version 2.
Goodbye!Создаём патч:
diff -u hello.txt hello_new.txt > update.patchСодержимое update.patch:
--- hello.txt 2025-04-05 11:00:00.000000000 +0300
+++ hello_new.txt 2025-04-05 11:01:00.000000000 +0300
@@ -1,3 +1,3 @@
Hello, world!
-This is version 1.
+This is version 2.
Goodbye!Применяем:
patch hello.txt < update.patchТеперь hello.txt содержит "version 2".
Пример 2: Добавление и удаление строк
Файл list.txt:
яблоко
банан
грушаНовый вариант list_new.txt:
яблоко
ананас
бананПатч:
diff -u list.txt list_new.txt > fruit.patchРезультат:
--- list.txt 2025-04-05 11:05:00.000000000 +0300
+++ list_new.txt 2025-04-05 11:06:00.000000000 +0300
@@ -1,3 +1,3 @@
яблоко
+ананас
банан
-грушаПрименение:
patch list.txt < fruit.patchТеперь list.txt:
яблоко
ананас
бананПример 3: Работа с несколькими файлами (рекурсивно)
Часто патчи создаются для целых директорий:
diff -ru old_project/ new_project/ > project_update.patchПрименение:
cd old_project
patch -p1 < ../project_update.patchФлаг -p1 удаляет первый уровень пути из имён файлов (например, убирает old_project/ из --- old_project/file.c). Это важно при работе с патчами из git diff или diff -r.
Полезные опции patch
| Опция | Назначение |
|---|---|
-p<n> |
Удаляет n компонентов пути из имён файлов (полезно при работе с подкаталогами) |
-i file |
Указать файл с патчем (вместо stdin) |
-o file |
Вывести результат в файл, не меняя оригинал |
-R |
Отменить патч (reverse patch) |
-N |
Не применять патч, если он уже был применён |
-s |
Тихий режим (no output) |
--dry-run |
Протестировать, не применяя изменений |
-f |
Принудительное применение (без вопросов) |
Пример: тестовый прогон
patch --dry-run -p1 < changes.patchПокажет, что будет изменено, но не применит.
Пример: отмена патча
patch -R < changes.patchВернёт файлы в исходное состояние.
Ограничения
- Только текстовые файлы —
patchработает с текстом. Бинарные файлы он не обрабатывает (хотя можно использоватьdiff -cс ними, но это ненадёжно). - Контекст важен — если файл изменился, и контекст не совпадает,
patchможет отказаться применять изменения или применить с "фуззингом". - Конфликты — если изменения пересекаются,
patchсоздаст файлы с суффиксом.rej(например,file.txt.rej) — это строки, которые не удалось применить. - Имена файлов в патче — нужно следить за путями. Флаг
-pпомогает адаптировать путь.
Пример: работа с git и patch
Git может генерировать патчи:
git diff > fix.patchПрименить в другой ветке:
patch -p1 < fix.patchИли через git:
git apply fix.patch(но patch — более универсален, т.к. и работает вне git)
Когда использовать patch?
- Когда нужно распространить небольшое исправление.
- В автоматизированных сборках.
- При отладке или тестировании изменений.
- В open-source: отправка патчей по email (например, в ядро Linux).
- Интеграция изменений без использования git/svn.
patch — это мощный инструмент Unix, позволяющий эффективно управлять изменениями в текстовых файлах. Он работает в паре с diff, применяет изменения построчно, используя контекст для надёжности.
Особенности SWE-bench
Традиционные бенчмарки в области обработки естественного языка (NLP) обычно включают короткие входные и выходные последовательности и основаны на несколько "искусственных" задачах, созданных специально для оценки. В отличие от них, SWE-bench основан на реальных задачах, что придаёт набору данных уникальные свойства, которые мы обсудим ниже.
Реальные задачи программной инженерии. Каждая задача в SWE-bench состоит из крупной и сложной кодовой базы и описания актуальной проблемы. Решение задач SWE-bench требует демонстрации сложных навыков и знаний, которыми обладают опытные инженеры-программисты, но которые редко оцениваются в традиционных бенчмарках генерации кода.
Постоянное обновление. Наш процесс сбора данных легко применим к любому Python-репозиторию на GitHub и требует минимального участия человека. Таким образом, мы можем расширять SWE-bench, добавляя новые задачи, и оценивать модели на проблемах, созданных после их даты обучения. Это гарантирует, что решения не были включены в обучающий корпус моделей.
Длинные и разнообразные входные данные. Описания задач обычно длинные и детализированные (в среднем 195 слов), а кодовые базы содержат тысячи файлов. Решение задач SWE-bench требует выявления относительно небольшого количества строк, которые необходимо изменить, среди огромного объёма контекста.
Надёжная оценка. Для каждой задачи существует хотя бы один тест, который меняет статус с "неудача" на "успех" (fail-to-pass), и 40% задач имеют как минимум два таких теста. Эти тесты проверяют, справилась ли модель с решением проблемы. Кроме того, в среднем запускается 51 дополнительный тест, чтобы убедиться, что предыдущая функциональность сохранена.
Редактирование кода в разных контекстах. В отличие от предыдущих бенчмарков, которые ограничивают область редактирования отдельной функцией или классом (например, Chen et al., 2021; Cassano et al., 2022) или предлагают заполнить пропуски (например, Lu et al., 2021; Fried et al., 2023), SWE-bench не даёт таких явных указаний. Вместо генерации короткого фрагмента кода, наш бенчмарк требует от моделей вносить изменения в нескольких местах крупной кодовой базы. Эталонные решения в SWE-bench в среднем редактируют 1,7 файла, 3,0 функции и 32,8 строки (добавленных или удалённых).
Широкий спектр возможных решений. Задача редактирования кода на уровне репозитория может служить общей платформой для сравнения различных подходов — от моделей с долгим контекстом и поисковых систем до агентов, способных рассуждать и действовать в коде. SWE-bench также предоставляет свободу для творчества: модели могут генерировать новые решения, которые могут отличаться от эталонных PR.
| Mean | Max | ||
| Issue Text | Length (Words) | 195.1 | 4477 |
| Codebase | # Files (non-test) | 3,010 | 5,890 |
| # Lines (non-test) | 438K | 886K | |
| Gold Patch | # Lines edited | 32.8 | 5888 |
| # Files edited | 1.7 | 31 | |
| # Func. edited | 3 | 36 | |
| Tests | # Fail to Pass | 9.1 | 1633 |
| # Total | 120.8 | 9459 |
Таблица 1. Средние и максимальные значения, характеризующие различные атрибуты экземпляра задачи SWE-bench. Статистика представляет собой микросредние значения, рассчитанные без группировки по репозиториям.
SWE-bench Lite
Оценка языковых моделей (LM) на SWE-bench может занимать много времени и, в зависимости от модели, требовать значительных вычислительных ресурсов или кредитов API. Учитывая, что начальные результаты производительности, представленные в Разделе 5, довольно низкие, сложность SWE-bench делает его полезным для долгосрочной оценки прогресса LM, но потенциально пугающим для начальных систем, которые пытаются добиться прогресса в краткосрочной перспективе.
Чтобы стимулировать использование SWE-bench, мы создали облегчённую версию — SWE-bench Lite, — которая включает 300 задач, отобранных из основного набора. Эти задачи более самодостаточны и сосредоточены на оценке исправлений функциональных ошибок. SWE-bench Lite охватывает 11 из 12 оригинальных репозиториев, сохраняя схожее разнообразие и распределение задач между ними, как и в исходном наборе. Полные детали отбора и фильтрации для версии Lite приведены в Приложении A.7.
SWE-Llama: Тонкая настройка CodeLlama для SWE-bench
Важно оценивать производительность открытых моделей на SWE-bench наряду с проприетарными. На момент написания только модели CodeLlama (Rozière и др., 2023) способны обрабатывать очень длинные контексты, необходимые для этой задачи. Однако мы наблюдаем, что стандартные варианты CodeLlama не могут следовать детальным инструкциям по генерации правок кода на уровне репозитория и часто выдают шаблонные ответы или нерелевантный код.
Чтобы лучше оценить возможности этих моделей, мы провели контролируемую тонкую настройку - дообучение SFT для моделей CodeLlama-Python с 7 и 13 миллиардами параметров. Получившиеся модели стали специализированными редакторами репозиториев, способными работать на потребительском оборудовании и решать задачи из GitHub.
Обучающие данные
Мы следуем процедуре сбора данных и собираем 19 000 пар "проблема-PR" из дополнительных 37 популярных репозиториев Python-пакетов. В отличие от раздела 2.1, мы не требуем, чтобы pull request содержали изменения в тестах. Это позволяет создать значительно больший обучающий набор для контролируемой тонкой настройки. Чтобы исключить риск загрязнения данных, репозитории из обучающего набора не пересекаются с теми, что используются в тестовом бенчмарке.
Детали обучения
На основе инструкций, текста проблемы из GitHub и соответствующих файлов кода в качестве промпта мы донастраиваем SWE-Llama, чтобы она генерировала исправление (так называемый "золотой патч"), решающее данную проблему. Для экономии памяти мы донастраиваем только веса подслоя внимания с использованием LoRA (Hu и др., 2022) и исключаем последовательности с более чем 30 000 токенов, сокращая эффективный размер обучающего корпуса до 10 000 примеров. Подробности приведены в Приложении B.
Дизайн экспериментов
В этом разделе объясняется, как формируются входные данные для оценки SWE-bench. Кроме того, рассматриваются модели, которые оцениваются в данной работе.
Подход на основе поиска
Экземпляры SWE-bench предоставляют описание проблемы и кодовую базу в качестве входных данных для модели. Хотя описания проблем обычно короткие (в среднем 195 слов, как показано в Таблице 1), кодовые базы состоят из гораздо большего количества токенов (в среднем 438 000 строк), чем может поместиться в окно контекста языковой модели. Тогда возникает вопрос: как именно выбрать релевантный контекст для предоставления модели?
Чтобы решить эту проблему для наших базовых моделей, мы используем универсальную систему поиска для выбора файлов, которые будут вставлены в контекст. В частности, мы оцениваем модели в двух режимах релевантного контекста:
- разреженный поиск (sparse retrieval)
- решение Оракула (oracle retrieval).
Разреженный поиск
Методы плотного поиска (dense retrieval) плохо подходят для нашей задачи из-за очень длинных ключей и запросов, а также необычной задачи поиска кодовых документов с использованием естественно-языковых запросов. Поэтому мы используем BM25 (Robertson и др., 2009) для поиска релевантных файлов, которые будут предоставлены в качестве контекста для каждого экземпляра задачи. Мы экспериментируем с тремя различными максимальными пределами контекста и просто извлекаем столько файлов, сколько помещается в указанный лимит. Мы оцениваем каждую модель на всех лимитах, которые помещаются в её окно контекста, и сообщаем о лучших результатах. Наблюдения показывают, что модели показывают наилучшие результаты при самом коротком окне контекста, как показано в Таблице 3.
Решение Оракула
Для аналитических целей мы также рассматриваем сценарий, в котором мы "извлекаем" файлы, отредактированные эталонным патчем, который решил проблему на GitHub. Этот сценарий "оракула" менее реалистичен, так как инженер, работающий над решением проблемы, заранее может не знать, какие файлы необходимо изменить. Кроме того, этот сценарий не обязательно является исчерпывающим, поскольку отредактированные файлы могут не включать весь необходимый контекст для понимания того, как программное обеспечение будет вести себя при взаимодействии с невидимыми частями кода.
Мы сравниваем результаты поиска BM25 с результатами сценария "оракул"-поиска, как показано в Таблице 3. Мы наблюдаем, что примерно в 40% случаев BM25 извлекает надмножество файлов "оракула" для лимита контекста в 27 000 токенов. Однако почти в половине случаев с лимитом в 27 000 токенов он не извлекает ни одного файла из контекста "оракула".
Формат входных данных
После того как файлы извлечены с использованием одного из двух описанных выше методов, мы формируем входные данные для модели, состоящие из:
- инструкций по задаче,
- текста проблемы,
- извлечённых файлов и документации,
- примера файла с патчем и подсказки для генерации файла с патчем.
Примеры экземпляров и дополнительные детали этого формата приведены в Приложении D.
Модели
Из-за необходимости обработки длинных последовательностей на данный момент для SWE-bench подходят лишь несколько моделей. Таким образом, мы оцениваем ChatGPT-3.5 (gpt-3.5-turbo-16k-0613), GPT-4 (gpt-4-32k-0613), Claude 2 и SWE-Llama с их лимитами контекста, показанными в Таблице 4.
| Модель | 13k | 27k | 50k |
|---|---|---|---|
| Claude 2 | 1.96 | 1.87 | 1.22 |
| SWE-Llama 7b | 0.70 | 0.31 | 0.00 |
| SWE-Llama 13b | 0.70 | 0.48 | 0.00 |
Таблица 2. Model resolve rates (% решенных задач) с поиском BM25 при различной максимальной длине контекста.
| Показатель | 13k | 27k | 50k |
|---|---|---|---|
| Средняя | 29.58 | 44.41 | 51.06 |
| Все | 26.09 | 39.83 | 45.90 |
| Любой | 34.77 | 51.27 | 58.38 |
Таблица 3. Recall BM25 относительно файлов Оракула для различных максимальных длин контекста.
| Модель | Макс. токенов | % экземпляров |
|---|---|---|
| ChatGPT-3.5 | 16385 | 58.1% |
| GPT-4 | 32768 | 84.1% |
| Claude 2 | 100000 | 96.4% |
| SWE-Llama | ≥100000 | ≥94.8% |
Таблица 4. Мы сравниваем различные длины контекста и долю охваченного параметра поиска «оракула». Таким образом, модели с более короткой длиной контекста изначально находятся в невыгодном положении. Обратите внимание, что описание длины токенов — это относительно нестандартная мера (например, последовательности, токенизированные с помощью Llama, в среднем на 42% длиннее эквивалентной последовательности, токенизированной с помощью GPT-4).
Результаты
Мы представляем результаты для моделей с использованием различных механизмов поиска и стилей формирования запросов, а затем предоставляем анализ и выводы о производительности моделей и сложности задач. Сводные данные о производительности моделей с использованием BM25-поиска приведены в Таблице 5. В целом модели испытывают значительные трудности с решением проблем. Лучшая модель, Claude 2, способна решить лишь 1,96% задач.
Чтобы проанализировать важность механизма поиска для общих результатов системы, мы представляем результаты с использованием "идеального" поиска в Таблице 18 (см. Приложение). Там модель Claude 2 решает 4,8% задач с использованием "идеального" поиска. Далее мы более подробно анализируем важность контекста в обсуждении ниже.
| SWE-bench | SWE-bench Lite | |||
|---|---|---|---|---|
| Model | % Resolved | % Apply | % Resolved | % Apply |
| Claude 3 Opus | 3.79 | 46.56 | 4.33 | 51.67 |
| Claude 2 | 1.97 | 43.07 | 3.00 | 33.00 |
| ChatGPT-3.5 | 0.17 | 26.33 | 0.33 | 10.00 |
| GPT-4-turbo | 1.31 | 26.90 | 2.67 | 29.67 |
| SWE-Llama 7b | 0.70 | 51.74 | 1.33 | 38.00 |
| SWE-Llama 13b | 0.70 | 53.62 | 1.00 | 38.00 |
Таблица 5. Сравнение моделей между собой с использованием BM25-поиска, как описано в Разделе 4.
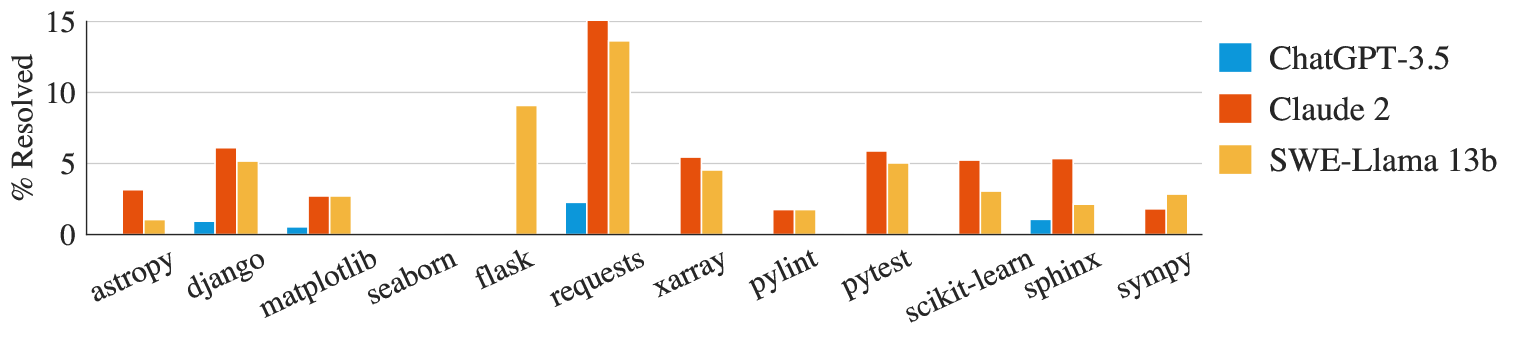
Рис. 4. Resolution rate (% решенных задач) для трех моделей в 12 репозиториях, представленных в SWE-bench в настройке поиска «Oracle».
Сложность задач различается в зависимости от репозиториев.
При анализе производительности по репозиториям все модели демонстрируют схожие тенденции, как показано на рисунке 4. Несмотря на это, задачи, решаемые каждой моделью, не обязательно значительно пересекаются. Например, в "идеальных" условиях Claude 2 и SWE-Llama 13b показывают сопоставимые результаты, решая 110 и 91 задачу соответственно. Однако Claude 2 справляется только с 42% задач, которые решает SWE-Llama.
Это также может быть связано с наличием изображений в задачах, которые могут быть встроены в разметку с помощью ссылок на изображения (например, ). В некоторых репозиториях естественным образом больше задач содержит изображения: например, 32% задач в matplotlib и 10% в seaborn содержат встроенные изображения, тогда как в среднем этот показатель составляет всего 2%. Решение таких задач может требовать мультимодальных языковых моделей или использования внешних инструментов для обработки изображений.
Сложность коррелирует с длиной контекста.
Чат-модели могут быть предобучены на длинных последовательностях кода, но обычно их просят генерировать короткие фрагменты кода с ограниченным контекстом для формулировки вопроса. Как показано на рисунке 5, с увеличением общей длины контекста производительность Claude 2 значительно снижается — аналогичное поведение наблюдается и у других моделей. В наших экспериментах модели получают много кода, который может не иметь прямого отношения к решению задачи, и им часто сложно локализовать проблемный код, требующий исправления. Этот результат подтверждает другие исследования, показывающие, что модели отвлекаются на дополнительный контекст и могут быть чувствительны к относительному расположению целевых последовательностей (Liu et al., 2023b). Даже при увеличении максимального размера контекста для BM25, что повышает полноту поиска относительно "идеальных" файлов, производительность падает, как показано в таблице 3, поскольку модели неэффективно локализуют проблемный код.
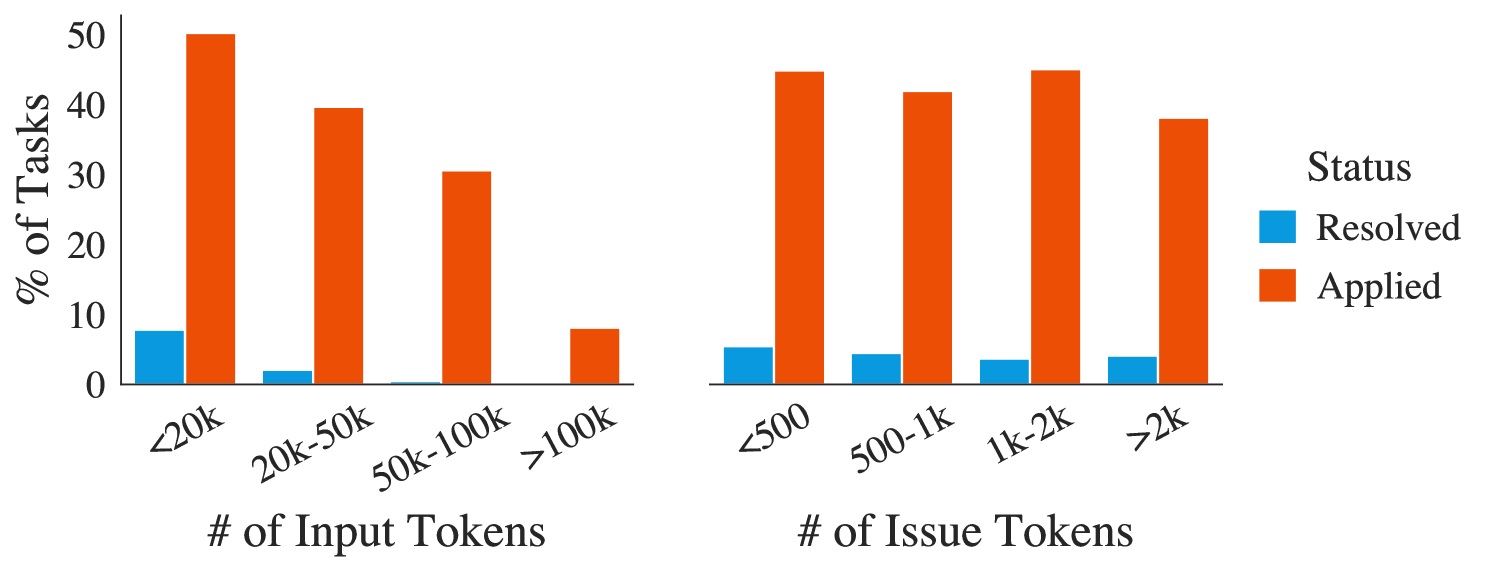
Рис. 5. SWE Bench - Мы сравниваем производительность Claude 2 на задачах, разделенных по общей длине входных данных и только по длине задачи.
| Model | “Oracle”-collapsed | |
|---|---|---|
| Resolved | Applied | |
| Claude 3 Opus | 9.39 | 48.00 |
| Claude 2 | 5.93 | 68.18 |
| GPT-4 | 3.40 | 48.65 |
| ChatGPT-3.5 | 1.09 | 40.93 |
Таблица 6. Мы показываем результаты для параметра извлечения, свернутого с помощью поиска на решении Оракула, который использует файлы Oracle, но сворачивает код, который не был напрямую изменен строками PR ±15 строк.
Дальнейшее исследование этого вопроса показывает результаты абляционного анализа входных данных в условиях "идеального" контекста поиска — "oracle"-collapsed, где все найденные файлы свёрнуты, за исключением строк, действительно изменённых в истинном pull request (с буфером ±15 строк), как показано в таблице 5. В таких условиях наблюдается рост производительности: GPT-4 улучшает результат с 1,3% до 3,4%, а Claude 2 — с 4,8% до 5,9%.
Сложность не коррелирует с датой разрешения задачи.
В таблице 7 представлены результаты моделей в условиях "идеального" поиска, разделённые по дате создания pull request — до и после 2023 года. Мы обнаружили, что для большинства моделей разницы в производительности до и после этой даты практически нет, за исключением GPT-4. Этот результат можно считать обнадеживающим: он свидетельствует о том, что, несмотря на знакомство моделей с определённой версией кодовой базы репозитория, они вряд ли "списывают" решения, просто генерируя более новую версию репозитория.
| Модель | До 2023 | После 2023 |
|---|---|---|
| Claude 2 | 4.87 | 4.23 |
| ChatGPT-3.5 | 0.49 | 0.77 |
| GPT-4* | 1.96 | 0.00 |
| SWE-Llama 7b | 2.95 | 3.46 |
| SWE-Llama 13b | 3.98 | 3.85 |
Таблица 7. Мы сравниваем производительность на экземплярах задач до и после 2023 года в условиях поиска данных Oracle. Большинство моделей демонстрируют незначительную разницу в производительности. ∗В связи с бюджетными ограничениями GPT-4 оценивается на 25% случайной выборке задач SWE-bench, что может повлиять на оценку резальтата.
Тонко настроенные модели чувствительны к изменениям в распределении контекста.
Тонко настроенные модели SWE-Llama 7b и 13b показывают неожиданно низкую производительность при использовании контекста, полученного с помощью BM25. Поскольку эти модели были дообучены с использованием "идеального" контекста, мы предполагаем, что изменение распределения контекста затрудняет их надёжную работу. Например, SWE-Llama обучалась редактировать каждый файл, включённый в контекст, тогда как в условиях BM25 многие файлы, предоставленные в контексте, не предполагается изменять.
Генерация патчей проще, чем генерация целых файлов.
Модели часто обучаются на стандартных файлах с кодом и, вероятно, редко сталкиваются с файлами патчей. Мы обычно формулируем задачу так, чтобы модели генерировали файлы патчей, а не пересоздавали весь файл с предложенными изменениями, поскольку файлы патчей, как правило, являются более эффективным представлением изменений в файле. Как показано в таблице 5, мы наблюдаем, что модели по-прежнему испытывают трудности с генерацией правильно оформленных файлов патчей. Поэтому мы экспериментировали с просьбой к моделям вместо этого пересоздавать целые файлы с предложенными изменениями для решения задачи. В этом случае мы обнаружили, что модели обычно справляются с этой задачей хуже, чем при генерации файлов патчей: например, Claude 2 показывает результат 2,2% по сравнению с 4,8% в основной таблице для "идеального" поиска. Даже при контроле длины экземпляров, генерация изменений для более короткой половины задач по количеству входных токенов даёт 3,9% по сравнению с 7,8% при генерации патчей для модели Claude 2.
Языковые модели склонны генерировать более короткие и простые правки.
Сгенерированные моделями файлы патчей, как правило, добавляют и удаляют меньше строк, чем соответствующие эталонные патчи. Как показано в таблице 8, по сравнению со средним эталонным патчем, правильно применённые сгенерированные модели патчи имеют менее половины общей длины (74,5 против 30,1 строк) эталонных файлов патчей и редко редактируют более одного файла.
| Model | Total Lines | Added | Removed | Functions | Files |
|---|---|---|---|---|---|
| Claude 2 | 19.6 | 4.2 | 1.9 | 1.1 | 1.0 |
| Gold | 44.1 | 12.0 | 5.8 | 2.1 | 1.2 |
| ChatGPT-3.5 | 30.1 | 3.8 | 2.7 | 1.6 | 1.0 |
| Gold | 39.6 | 9.5 | 6.1 | 1.9 | 1.2 |
| GPT-4 | 20.9 | 4.4 | 1.5 | 1.0 | 1.0 |
| Gold | 33.6 | 8.4 | 3.8 | 1.9 | 1.1 |
| SWE-Llama 13b | 17.6 | 1.6 | 1.2 | 1.2 | 1.1 |
| Gold | 37.8 | 10.0 | 4.4 | 1.9 | 1.1 |
| SWE-Llama 7b | 16.7 | 1.3 | 1.2 | 1.2 | 1.1 |
| Gold | 40.2 | 11.3 | 4.9 | 1.9 | 1.1 |
| Avg Gold | 39.1 | 10.2 | 5.0 | 1.9 | 1.1 |
| All Gold | 74.5 | 22.3 | 10.5 | 3.0 | 1.7 |
Таблица 8: Среднее количество изменений в патчах, сгенерированных моделью в настройке поиска «oracle» среди успешно применённых патчей. Для экземпляров задач, специфичных для каждой модели, мы рассчитываем одинаковую статистику по золотым патчам. В столбце «Avg Gold» показана макроусреднённая статистика по соответствующим золотым патчам каждой модели. В столбце «All Gold» показана статистика для всех золотых патчей без учёта производительности модели.
Качественный анализ генераций SWE-Llama
Мы выбрали 11 генераций от SWE-Llama и Claude 2, чтобы лучше понять качество выполнения задач и сгенерированных исправлений в условиях "оракульского" поиска. Здесь мы обсуждаем пример из SWE-Llama и наши общие выводы, а подробные анализы других примеров приведены в Приложении F.
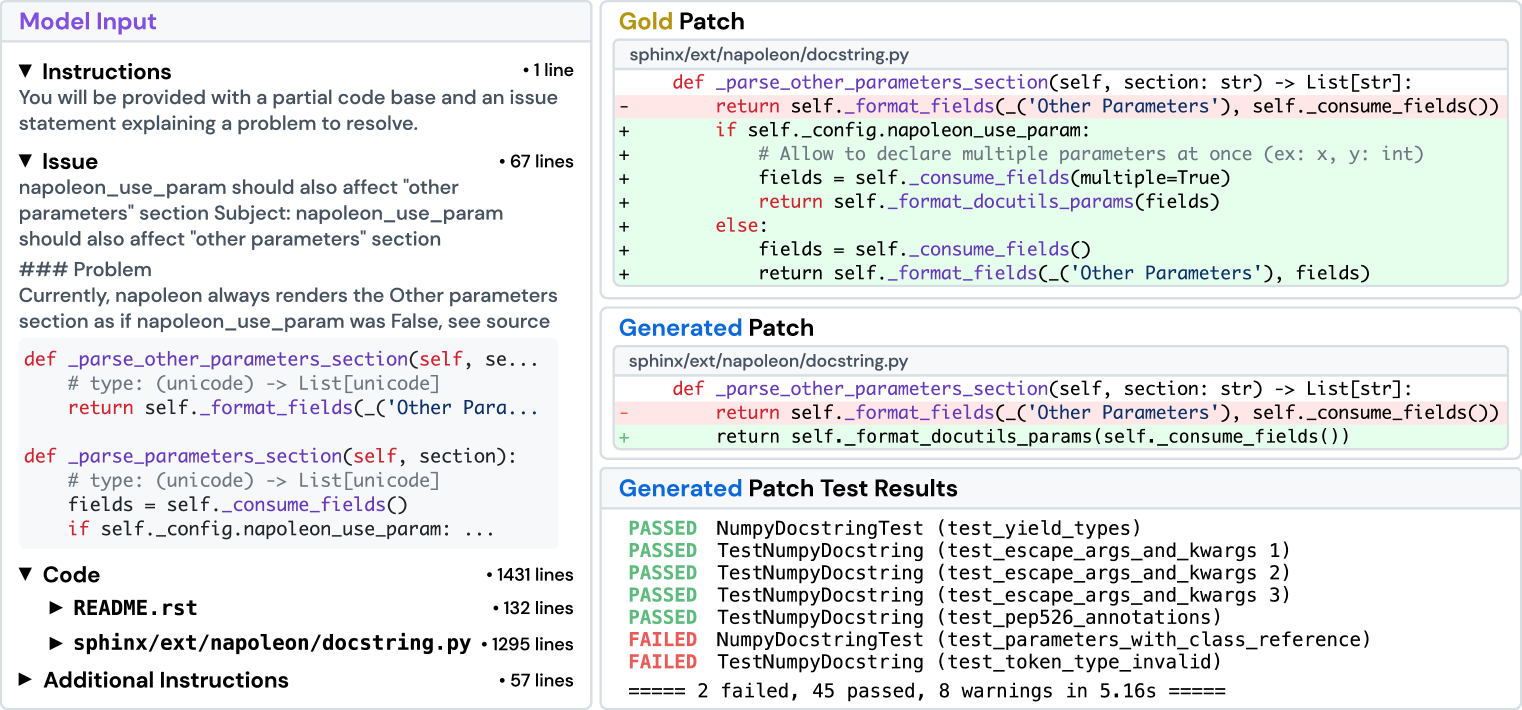
Рис. 6. SWE-Llama. Показан пример форматированного экземпляра задачи, предсказания модели и логов тестового фреймворка. В исправлениях красным выделены удаления, зелёным — добавления.
Рассмотрим экземпляр задачи sphinx-doc__sphinx-8713 из генератора документации Sphinx, представленный на Рисунке 6. В задаче указано, что расширение napoleon в Sphinx неправильно форматирует ключевое слово документации "Other Parameters", когда параметр конфигурации napoleon.use_param установлен в значение True. Текст задачи также содержит подробный фрагмент кода, где предположительно находится проблемный исходный код, примеры кода для воспроизведения ошибки и дополнительную информацию о версиях пакетов. В данном случае модель не смогла полностью решить задачу и не прошла некоторые тесты, которые успешно выполняются с золотым решением.
В условиях "оракульского" поиска входные данные модели включают текст задачи, инструкции, полное содержимое файлов, изменённых золотым исправлением, а также пример формата diff, в котором ожидается ответ. Общий объём входных данных модели составляет 1558 строк контекста или 20882 токена. При сравнении золотого исправления и исправления модели обнаруживается очевидная ошибка. Хотя модель редактирует правильную функцию — _parse_other_parameters_section на строке 684 в файле sphinx/ext/napoleon/docstring.py, она изменяет её так, будто параметр napoleon.use_param всегда равен True, вместо того чтобы сначала проверять настройку конфигурации и копировать поведение функции _parse_parameters_section, как это делает золотое исправление. В тестах test_parameters_with_class_reference напрямую сравнивается документация, сгенерированная с конфигурацией, где napoleon_use_param установлен в False, что сразу выявляет ошибку модели.
Сравнивая результаты по всем рассмотренным примерам, можно выделить несколько заметных тенденций в поведении моделей. Модели склонны писать примитивный код на Python и не используют существующие сторонние библиотеки или остальную часть кодовой базы для своих решений. Генерации моделей также отражают "жадный" подход к решению задачи, без учёта стиля кода или логических ограничений, которые могут быть заложены в кодовой базе (например, использование относительных импортов вместо абсолютных). В то же время многие золотые исправления вносят структурные улучшения, охватывающие гораздо более широкий контекст кодовой базы; такие правки не только решают текущую проблему, но и предотвращают потенциальные ошибки в будущем.
Связанные работы
Оценка языковых моделей (ЛМ).
Несколько недавних работ по оценке ЛМ предлагают либо набор взаимно различных задач, охватывающих несколько доменов (Hendrycks et al., 2021; Liang et al., 2022; Srivastava et al., 2023), либо обращаются к веб-среде как к интерактивной платформе с задачами, требующими нескольких шагов для решения (Yao et al., 2022; Zhou et al., 2023; Deng et al., 2023; Liu et al., 2023d). У такого "попурри"-подхода есть несколько недостатков. Во-первых, каждая задача, как правило, фокусируется на одном или нескольких навыках, что приводит к слишком простым вызовам, ограничивающим модель узкой ролью и не дающим ей возможности проявить свою универсальность или потенциально новые способности (Srivastava et al., 2023). В результате, показатели модели на таких конгломератах задач могут не давать глубоких, практически полезных выводов о её возможностях и способах их улучшения (Schlangen, 2019; Martínez-Plumed et al., 2021; Bowman & Dahl, 2021). SWE-bench решает эти проблемы: наша работа демонстрирует, что он значительно сложнее, предоставляет широкий спектр возможностей для улучшения ЛМ при решении этой задачи и легко обновляется со временем новыми экземплярами задач, каждый из которых вносит новые, тонкие и практические вызовы.
Бенчмарки генерации кода.
HumanEval (Chen et al., 2021) является текущим стандартом в долговременных исследованиях по синтезу кода на основе естественно-языковых описаний (Yu et al., 2018; Austin et al., 2021; Hendrycks et al., 2021; Li et al., 2022a; Zan et al., 2023). За последний год последующие бенчмарки стремились расширить HumanEval за счёт добавления поддержки различных языков (Cassano et al., 2022; Athiwaratkun et al., 2023; Orlanski et al., 2023), вариаций в объёме редактирования (Yu et al., 2023; Du et al., 2023), аналогичных, но новых задач на завершение кода (Muennighoff et al., 2023), а также более глубокого тестирования (Liu et al., 2023a). Параллельно отдельные работы стремились внедрить новые парадигмы программирования (Yin et al., 2022; Yang et al., 2023) или разрабатывать задачи, специфичные для библиотек (Lai et al., 2022; Zan et al., 2022). Вместо того чтобы разбивать задачи на изолированные наборы данных и упрощать их, процедура сбора SWE-bench трансформирует исходный код с минимальной постобработкой, сохраняя гораздо более широкий спектр вызовов, основанных на реальных задачах программной инженерии, выходящих за рамки закрытого завершения кода, таких как генерация патчей, рассуждение в длинных контекстах, навигация по структуре кодовой базы и учёт зависимостей между модулями.
Машинное обучение для программной инженерии.
Чтобы преодолеть ограничения традиционных методов анализа программ, которые могут не масштабироваться или не учитывать естественный язык, одно из направлений современных исследований в области программной инженерии — использование нейронных сетей, включая ЛМ, для автоматизации реальных процессов разработки программного обеспечения (Maniatis et al., 2023; Zheng et al., 2023; Hou et al., 2023). Примеры применения включают автоматизацию генерации коммитов (Jung, 2021; Liu et al., 2023c), ревью пулл-реквестов (Yang et al., 2016; Li et al., 2022b; Tufano et al., 2021), локализацию багов (Kim et al., 2019; Chakraborty et al., 2018), тестирование (Kang et al., 2023; Xia et al., 2023; Wang et al., 2023) и исправление программ (Gupta et al., 2017; Allamanis et al., 2017; Monperrus, 2018; Jiang et al., 2018; Goues et al., 2019; Gao et al., 2022; Dinh et al., 2023; Motwani & Brun, 2023). Наиболее актуальны для SWE-bench работы, направленные на применение ЛМ для автоматического исправления программ (Xia & Zhang, 2022; 2023; Fan et al., 2023; Sobania et al., 2023) и руководства редактированием кода с использованием коммитов (Chakraborty & Ray, 2021; Zhang et al., 2022; Fakhoury et al., 2023). Однако ни один из существующих наборов данных (Just et al., 2014; Karampatsis & Sutton, 2019) не предоставляет контекст кода в таком масштабе, как SWE-bench. Более того, SWE-bench легко расширяется на новые языки программирования и репозитории, предоставляя значительно более реалистичную и сложную площадку для экспериментов по улучшению ЛМ с помощью инструментов и практик программной инженерии.
Ограничения и перспективы.
Экземпляры задач SWE-bench написаны на Python; мы надеемся применить процедуру сбора экземпляров задач SWE-bench для расширения его охвата на другие языки программирования и домены. Во-вторых, наши эксперименты направлены на установление базового уровня самых простых и прямых подходов к этой задаче; мы не намерены ограничивать будущие методологии тем же типом подходов и приветствуем дальнейшие исследования различных методов (например, агентных подходов, ЛМ с инструментальным дополнением).
Наконец, хотя в этой работе оценка моделей основана на тестировании выполнения кода, полное доверие только этому методу недостаточно для гарантии надёжности генераций моделей, так как мы обнаружили, что автоматически сгенерированный код от ЛМ часто бывает менее полным, не эффективным или плохо читабельным по сравнению с решениями, написанными человеком.
Сложность реальных процессов разработки программного обеспечения выходит далеко за рамки простого завершения кода. Опираясь на открытый коллаборативный конвейер, SWE-bench создаёт достоверное отражение реальных сред программирования. Эта более реалистичная среда стимулирует творческие решения, которые могут сразу применяться в разработке программного обеспечения с открытым исходным кодом. Мы надеемся, что этот бенчмарк и наши другие вкладки станут ценными активами для будущего развития ЛМ, делая их более практичными, интеллектуальными и автономными.
SWE-bench полностью собран из публичных репозиториев с лицензиями, разрешающими использование программного обеспечения. В рамках нашей подачи мы загрузили весь исходный код в виде архива, который должным образом анонимизирован.
Список источников
- Allamanis et al. (2017) Miltiadis Allamanis, Marc Brockschmidt, and Mahmoud Khademi. Learning to represent programs with graphs. arXiv preprint arXiv:1711.00740, 2017.
- Athiwaratkun et al. (2023) Ben Athiwaratkun, Sanjay Krishna Gouda, Zijian Wang, Xiaopeng Li, and Yuchen Tian et. al. Multi-lingual evaluation of code generation models, 2023.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021.
- Bowman & Dahl (2021) Samuel R. Bowman and George E. Dahl. What will it take to fix benchmarking in natural language understanding?, 2021.
- Cassano et al. (2022) Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. Multipl-e: A scalable and extensible approach to benchmarking neural code generation, 2022.
- Chakraborty & Ray (2021) Saikat Chakraborty and Baishakhi Ray. On multi-modal learning of editing source code, 2021.
- Chakraborty et al. (2018) Saikat Chakraborty, Yujian Li, Matt Irvine, Ripon Saha, and Baishakhi Ray. Entropy guided spectrum based bug localization using statistical language model. arXiv preprint arXiv:1802.06947, 2018.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, and Jared Kaplan et. al. Evaluating large language models trained on code, 2021.
- Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- Deng et al. (2023) Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web, 2023.
- Dinh et al. (2023) Tuan Dinh, Jinman Zhao, Samson Tan, Renato Negrinho, Leonard Lausen, Sheng Zha, and George Karypis. Large language models of code fail at completing code with potential bugs. arXiv preprint arXiv:2306.03438, 2023.
- Du et al. (2023) Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. Classeval: A manually-crafted benchmark for evaluating llms on class-level code generation, 2023.
- Fakhoury et al. (2023) Sarah Fakhoury, Saikat Chakraborty, Madan Musuvathi, and Shuvendu K. Lahiri. Towards generating functionally correct code edits from natural language issue descriptions, 2023.
- Fan et al. (2023) Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. Automated repair of programs from large language models, 2023.
- Fried et al. (2023) Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen tau Yih, Luke Zettlemoyer, and Mike Lewis. Incoder: A generative model for code infilling and synthesis, 2023.
- Gao et al. (2022) Xiang Gao, Yannic Noller, and Abhik Roychoudhury. Program repair, 2022.
- Goues et al. (2019) Claire Le Goues, Michael Pradel, and Abhik Roychoudhury. Automated program repair. Communications of the ACM, 62(12):56–65, 2019.
- Gros et al. (2023) David Gros, Prem Devanbu, and Zhou Yu. Ai safety subproblems for software engineering researchers, 2023.
- Gupta et al. (2017) Rahul Gupta, Soham Pal, Aditya Kanade, and Shirish Shevade. Deepfix: Fixing common c language errors by deep learning. In Proceedings of the aaai conference on artificial intelligence, volume 31, 2017.
- Halstead (1977) Maurice H. Halstead. Elements of Software Science (Operating and programming systems series). Elsevier Science Inc., USA, 1977. ISBN 0444002057.
- Hendrycks et al. (2021) Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with apps, 2021.
- Hou et al. (2023) Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: A systematic literature review, 2023.
- Hu et al. (2022) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Jacobs et al. (2023) Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models, 2023.
- Jiang et al. (2018) Jiajun Jiang, Yingfei Xiong, Hongyu Zhang, Qing Gao, and Xiangqun Chen. Shaping program repair space with existing patches and similar code. In Proceedings of the 27th ACM SIGSOFT international symposium on software testing and analysis, pp. 298–309, 2018.
- Jung (2021) Tae-Hwan Jung. Commitbert: Commit message generation using pre-trained programming language model, 2021.
- Just et al. (2014) René Just, Darioush Jalali, and Michael D. Ernst. Defects4J: A Database of existing faults to enable controlled testing studies for Java programs. In ISSTA 2014, Proceedings of the 2014 International Symposium on Software Testing and Analysis, pp. 437–440, San Jose, CA, USA, July 2014. Tool demo.
- Kang et al. (2023) Sungmin Kang, Juyeon Yoon, and Shin Yoo. Large language models are few-shot testers: Exploring llm-based general bug reproduction, 2023.
- Karampatsis & Sutton (2019) Rafael-Michael Karampatsis and Charles Sutton. How often do single-statement bugs occur? the manysstubs4j dataset. 2020 IEEE/ACM 17th International Conference on Mining Software Repositories (MSR), pp. 573–577, 2019. URL https://api.semanticscholar.org/CorpusID:173188438.
- Kiela et al. (2021) Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, and Zhengxuan Wu et. al. Dynabench: Rethinking benchmarking in nlp, 2021.
- Kim et al. (2019) Yunho Kim, Seokhyeon Mun, Shin Yoo, and Moonzoo Kim. Precise learn-to-rank fault localization using dynamic and static features of target programs. ACM Transactions on Software Engineering and Methodology (TOSEM), 28(4):1–34, 2019.
- Lai et al. (2022) Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Scott Wen tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation, 2022.
- Li et al. (2022a) Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, and Ré mi Leblond et. al. Competition-level code generation with AlphaCode. Science, 378(6624):1092–1097, dec 2022a. doi: 10.1126/science.abq1158. URL https://doi.org/10.1126%2Fscience.abq1158.
- Li et al. (2022b) Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, and Neel Sundaresan. Automating code review activities by large-scale pre-training, 2022b.
- Liang et al. (2022) Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, and Michihiro Yasunaga et. al. Holistic evaluation of language models, 2022.
- Liu et al. (2023a) Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210, 2023a.
- Liu et al. (2023b) Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023b. arXiv:2307.03172.
- Liu et al. (2023c) Shangqing Liu, Yanzhou Li, Xiaofei Xie, and Yang Liu. Commitbart: A large pre-trained model for github commits, 2023c.
- Liu et al. (2023d) Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, and Hanyu Lai et. al. Agentbench: Evaluating llms as agents, 2023d.
- Lu et al. (2021) Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, and Ambrosio Blanco et. al. Codexglue: A machine learning benchmark dataset for code understanding and generation. CoRR, abs/2102.04664, 2021.
- Maniatis et al. (2023) Petros Maniatis, Daniel Tarlow, and Google DeepMind. Large sequence models for software development activities, 2023. URL https://blog.research.google/2023/05/large-sequence-models-for-software.html.
- Martínez-Plumed et al. (2021) Fernando Martínez-Plumed, Pablo Barredo, Seán Ó hÉigeartaigh, and José Hernández-Orallo. Research community dynamics behind popular ai benchmarks. Nature Machine Intelligence, 3:581 – 589, 2021. URL https://api.semanticscholar.org/CorpusID:236610014.
- McCabe (1976) Thomas J. McCabe. A complexity measure. IEEE Transactions on Software Engineering, SE-2(4):308–320, 1976. doi: 10.1109/TSE.1976.233837.
- Monperrus (2018) Martin Monperrus. Automatic software repair. ACM Computing Surveys, 51(1):1–24, jan 2018. doi: 10.1145/3105906. URL https://doi.org/10.1145%2F3105906.
- Motwani & Brun (2023) Manish Motwani and Yuriy Brun. Better automatic program repair by using bug reports and tests together, 2023.
- Muennighoff et al. (2023) Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. Octopack: Instruction tuning code large language models, 2023.
- Orlanski et al. (2023) Gabriel Orlanski, Kefan Xiao, Xavier Garcia, Jeffrey Hui, Joshua Howland, Jonathan Malmaud, Jacob Austin, Rishabh Singh, and Michele Catasta. Measuring the impact of programming language distribution, 2023.
- Ott et al. (2022) Simon Ott, Adriano Barbosa-Silva, Kathrin Blagec, Janina Brauner, and Matthias Samwald. Mapping global dynamics of benchmark creation and saturation in artificial intelligence. Nature Communications, 13, 2022. URL https://api.semanticscholar.org/CorpusID:247318891.
- Robertson et al. (2009) Stephen Robertson, Hugo Zaragoza, et al. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389, 2009.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, and Xiaoqing Ellen Tan et. al. Code llama: Open foundation models for code, 2023.
- Schlangen (2019) David Schlangen. Language tasks and language games: On methodology in current natural language processing research, 2019.
- Sobania et al. (2023) Dominik Sobania, Martin Briesch, Carol Hanna, and Justyna Petke. An analysis of the automatic bug fixing performance of chatgpt, 2023.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, and Abu Awal Md Shoeb et. al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, 2023.
- Tufano et al. (2021) Rosalia Tufano, Luca Pascarella, Michele Tufano, Denys Poshyvanyk, and Gabriele Bavota. Towards automating code review activities, 2021.
- Wang et al. (2023) Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. Software testing with large language model: Survey, landscape, and vision, 2023.
- Xia & Zhang (2022) Chunqiu Steven Xia and Lingming Zhang. Less training, more repairing please: revisiting automated program repair via zero-shot learning. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pp. 959–971, 2022.
- Xia & Zhang (2023) Chunqiu Steven Xia and Lingming Zhang. Conversational automated program repair, 2023.
- Xia et al. (2023) Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. Universal fuzzing via large language models. arXiv preprint arXiv:2308.04748, 2023.
- Yang et al. (2023) John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. Intercode: Standardizing and benchmarking interactive coding with execution feedback, 2023.
- Yang et al. (2016) Xin Yang, Raula Gaikovina Kula, Norihiro Yoshida, and Hajimu Iida. Mining the modern code review repositories: A dataset of people, process and product. In Proceedings of the 13th International Conference on Mining Software Repositories, pp. 460–463, 2016.
- Yao et al. (2022) Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents, 2022.
- Yin et al. (2022) Pengcheng Yin, Wen-Ding Li, Kefan Xiao, Abhishek Rao, Yeming Wen, Kensen Shi, Joshua Howland, Paige Bailey, Michele Catasta, Henryk Michalewski, Alex Polozov, and Charles Sutton. Natural language to code generation in interactive data science notebooks, 2022.
- Yu et al. (2023) Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Tao Xie, and Qianxiang Wang. Codereval: A benchmark of pragmatic code generation with generative pre-trained models, 2023.
- Yu et al. (2018) Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-SQL task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 3911–3921, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1425. URL https://aclanthology.org/D18-1425.
- Zan et al. (2022) Daoguang Zan, Bei Chen, Dejian Yang, Zeqi Lin, Minsu Kim, Bei Guan, Yongji Wang, Weizhu Chen, and Jian-Guang Lou. Cert: Continual pre-training on sketches for library-oriented code generation, 2022.
- Zan et al. (2023) Daoguang Zan, Bei Chen, Fengji Zhang, Dianjie Lu, Bingchao Wu, Bei Guan, Yongji Wang, and Jian-Guang Lou. Large language models meet nl2code: A survey, 2023.
- Zhang et al. (2022) Jiyang Zhang, Sheena Panthaplackel, Pengyu Nie, Junyi Jessy Li, and Milos Gligoric. Coditt5: Pretraining for source code and natural language editing, 2022.
- Zheng et al. (2023) Zibin Zheng, Kaiwen Ning, Jiachi Chen, Yanlin Wang, Wenqing Chen, Lianghong Guo, and Weicheng Wang. Towards an understanding of large language models in software engineering tasks. arXiv preprint arXiv:2308.11396, 2023.
- Zhou et al. (2023) Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2023.
Детали сбора данных и приожения смотрите в оригинальной статье в разделах приложений (Appendix).