Анализ API v1/responses в OpenAI и VLLM - как генрировать ответы, вызывать функции, работать с Responses API
Responses API представляет собой новое поколение stateful-интерфейса от OpenAI, объединяющее лучшие возможности Chat Completions и Assistants API в единую унифицированную систему. Этот API был выпущен как часть стратегии упрощения workflow, связанных с использованием инструментов, выполнением кода и управлением состоянием.
Ключевые технические особенности:
-
Stateful архитектура: В отличие от традиционных stateless эндпоинтов (например,
/v1/chat/completions), Responses API поддерживает состояние между запросами, что критически важно для построения сложных агентов и многошаговых взаимодействий. -
Встроенная поддержка инструментов: Позволяет использовать встроенные инструменты OpenAI (такие как web search) без необходимости полного цикла запросов к сторонним сервисам — OpenAI запускает удаленные MCP-серверы непосредственно в своих дата-центрах, обеспечивая более быстрые round trips.
-
Структурированные выводы: API поддерживает строгую типизацию ответов через методы
generateObjectиstreamObject, которые принимают параметрschemaдля валидации выходных данных. -
Оптимизация для агентов: Responses API специально разработан для построения агент-ориентированных приложений, сочетая простоту Chat Completions с расширенными возможностями управления состоянием.
Это не просто новый эндпоинт, а фундаментальный сдвиг в подходе OpenAI к предоставлению ИИ-сервисов — Responses API позиционируется как основной интерфейс для взаимодействия с моделями.
VLLM и Responses API: реализация и отличия
VLLM, как высокопроизводительный фреймворк для inference, активно адаптирует новую спецификацию API:
-
Совместимость с OpenAI API: VLLM V1 реализует HTTP-сервер, совместимый с OpenAI Chat Completions API и Responses API, что позволяет использовать OpenAI SDK без значительных изменений в клиентском коде.
-
Критическая функциональность для масштабирования: Поддержка Responses API без использования хранилищ (stores) является критически важной для крупномасштабных развертываний VLLM, так как позволяет маршрутизировать последующие запросы на разные серверы.
-
Архитектурные изменения в V1: VLLM V1 включает полную перестройку ключевых компонентов, включая планировщик, менеджер KV-кэша, воркеры и API-сервер, что необходимо для поддержки stateful-сценариев Responses API.
-
Текущее состояние поддержки: Хотя изначально VLLM не поддерживал Responses API, сообщество активно работало над добавлением этой функциональности для синхронизации с последними изменениями OpenAI.
Технические различия и рекомендации для разработчиков
-
State management: В традиционном
/v1/chat/completionsсостояние должно управляться на стороне клиента, тогда как Responses API инкапсулирует состояние на сервере, что упрощает реализацию многошаговых workflow. -
Интеграция инструментов: Responses API позволяет регистрировать инструменты на стороне сервера, избегая необходимости обработки tool calls на клиенте, что снижает сложность клиентского кода.
-
Производительность: Для VLLM поддержка Responses API требует переработки архитектуры обработки запросов, так как stateful-природа API противоречит традиционному stateless-подходу inference-серверов.
-
Миграция: При переходе с
/v1/chat/completionsна Responses API разработчикам следует учитывать, что новый API требует иного подхода к обработке потоковых ответов и управлению сессиями.
Responses API представляет собой эволюционный шаг в сторону более сложных ИИ-приложений, где модели выступают не просто как текстовые генераторы, а как полноценные агенты с состоянием и инструментами. Для VLLM поддержка этого API критически важна, так как позволяет фреймворку оставаться совместимым с современными паттернами разработки ИИ-приложений, сохраняя при этом высокую производительность и масштабируемость. Разработчикам, использующим VLLM, рекомендуется изучить новую документацию по Responses API и адаптировать свои приложения для использования stateful-возможностей, что откроет доступ к более сложным сценариям взаимодействия с LLM.
Обзор OpenAI на свою реализацию v1/responses API
На основе https://platform.openai.com/docs/guides/migrate-to-responses
По словам OpenAI: Responses API — это новый базовый API, развитие Chat Completions, которое добавляет простоту и мощные агентные примитивы в ваши интеграции. Хотя Chat Completions по-прежнему поддерживается, Responses рекомендуется для всех новых проектов.
- Встроенные инструменты, такие как веб-поиск, поиск по файлам, использование компьютера, интерпретатор кода и удаленные MCP.
- Бесшовные многошаговые взаимодействия, позволяющие использовать предыдущие ответы для повышения точности рассуждений.
- Нативная поддержка мультимодальности для текста и изображений.
Responses API имеет несколько преимуществ по сравнению с Chat Completions:
- Лучшая производительность: Использование моделей рассуждений, таких как GPT-5, с Responses даст лучшие результаты интеллекта модели по сравнению с Chat Completions. Внутренние оценки OpenAI показывают улучшение на 3% в SWE-bench при том же промпте и настройках.
- Агентность по умолчанию: Responses API — это агентный цикл, позволяющий модели вызывать несколько инструментов, таких как
web_search,image_generation,file_search,code_interpreter, удаленные MCP-серверы, а также ваши собственные пользовательские функции в рамках одного API-запроса. - Ниже затраты: Более низкие затраты благодаря улучшенному использованию кэша (улучшение на 40–80% по сравнению с Chat Completions во внутренних тестах).
- Состояние контекста: Используйте
store: true, чтобы сохранять состояние от запроса к запросу, сохраняя контекст рассуждений и инструментов между запросами. - Гибкие входные данные: Передавайте строку с входными данными или список сообщений; используйте инструкции для системного промпта.
- Зашифрованные рассуждения: Отключите сохранение состояния, сохраняя при этом преимущества расширенных рассуждений.
- Защита от будущих изменений: Готовность к будущим моделям.
Responses API — это надмножество Chat Completions API. Он имеет предсказуемую, событийно-ориентированную архитектуру, тогда как Chat Completions API непрерывно добавляет данные в поле content по мере генерации токенов, требуя от вас вручную отслеживать различия между состояниями. Многоэтапная логика диалога и рассуждений проще реализуется с помощью Responses API.
Responses API четко генерирует семантические события, детально описывающие, что изменилось (например, конкретные текстовые добавления), что позволяет писать интеграции, ориентированные на конкретные события (например, изменения текста), упрощая интеграцию и улучшая безопасность типов.
| Возможности | Chat Completions API | Responses API |
|---|---|---|
| Генерация текста | ✅ | ✅ |
| Аудио | ❌ | Скоро |
| Vision | ✅ | ✅ |
| Структурированные выходные данные (Structured Outputs) | ✅ | ✅ |
| Вызов функций (Function calling) | ✅ | ✅ |
| Веб-поиск | ❌ | ✅ |
| Поиск по файлам | ❌ | ✅ |
| Использование компьютера | ❌ | ✅ |
| Интерпретатор кода | ❌ | ✅ |
| MCP | ❌ | ✅ |
| Генерация изображений | ❌ | ✅ |
| Суммаризация рассуждений (Reasoning summaries) | ❌ | ✅ |
Оба API позволяют легко генерировать вывод из моделей. Входные данные и результат вызова Chat Completions — это массив Messages, тогда как Responses API использует Items. Item — это объединение многих типов, представляющее диапазон возможных действий модели. Сообщение — это тип Item, как и function_call или function_call_output. В отличие от Chat Completions Message, где многие аспекты объединены в один объект, Items различаются между собой и лучше представляют базовую единицу контекста модели.
Кроме того, Chat Completions может возвращать несколько параллельных генераций в виде choices с использованием параметра n. В Responses этот параметр удален, оставлена только одна генерация.
Chat Completions API
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-5",
messages=[
{
"role": "user",
"content": "Напишите сказку на ночь об единороге в одно предложение."
}
]
)
print(completion.choices[0].message.content)Responses API
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
input="Напишите сказку на ночь об единороге в одно предложение."
)
print(response.output_text)Когда вы получаете ответ от Responses API, поля немного отличаются. Вместо сообщения вы получаете типизированный объект ответа со своим id. Ответы хранятся по умолчанию. Chat Completions также хранятся по умолчанию для новых аккаунтов. Чтобы отключить хранение при использовании любого API, установите store: false.
Объекты, которые вы получаете от этих API, будут немного отличаться. В Chat Completions вы получаете массив choices, каждый из которых содержит сообщение. В Responses вы получаете массив Items, помеченных как output.
Ответ Chat Completions API
{
"id": "chatcmpl-C9EDpkjH60VPPIB86j2zIhiR8kWiC",
"object": "chat.completion",
"created": 1756315657,
"model": "gpt-5-2025-08-07",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Под одеялом звездного света сонный единорог прокрадывался через лунные луга, собирая сны, как росу, чтобы спрятать их под своей серебристой гривой до утра.",
"refusal": null,
"annotations": []
},
"finish_reason": "stop"
}
],
...
}Ответ Responses API
{
"id": "resp_68af4030592c81938ec0a5fbab4a3e9f05438e46b5f69a3b",
"object": "response",
"created_at": 1756315696,
"model": "gpt-5-2025-08-07",
"output": [
{
"id": "rs_68af4030baa48193b0b43b4c2a176a1a05438e46b5f69a3b",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "msg_68af40337e58819392e935fb404414d005438e46b5f69a3b",
"type": "message",
"status": "completed",
"content": [
{
"type": "output_text",
"annotations": [],
"logprobs": [],
"text": "Под лунным одеялом сонный единорог бродил по тихим лугам, касаясь цветов своим светящимся рогом, чтобы они вздыхали нежные колыбельные, которые нежно уносили каждого мечтателя в сон."
}
],
"role": "assistant"
}
],
...
}Дополнительные различия
- Ответы хранятся по умолчанию. Chat Completions также хранятся по умолчанию для новых аккаунтов. Чтобы отключить хранение в любом API, установите
store: false. - Модели рассуждений имеют более богатые возможности с Responses API с улучшенным использованием инструментов.
- Формат Structured Outputs API отличается. Вместо
response_formatиспользуйтеtext.formatв Responses. Подробнее в руководстве по Structured Outputs. - Формат API для вызова функций отличается как для конфигурации функции в запросе, так и для вызовов функций, отправляемых обратно в ответе. См. полное отличие в руководстве по вызову функций.
- В Responses SDK есть вспомогательный метод
output_text, которого нет в Chat Completions SDK. - В Chat Completions состояние диалога необходимо управлять вручную. Responses API совместим с Conversations API для постоянных диалогов или позволяет передавать
previous_response_idдля легкого связывания ответов.
Есть два незначительных, но важных отличия в определении функций между Chat Completions и Responses:
- В Chat Completions функции определяются с использованием внешнего тегированного полиморфизма, тогда как в Responses они тегируются внутренне.
- В Chat Completions функции по умолчанию нестрогие, тогда как в Responses API функции по умолчанию строгие.
Пример функции в Responses API справа функционально эквивалентен примеру в Chat Completions слева.
Chat Completions API
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Определить погоду в моем местоположении",
"strict": true,
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
},
},
"additionalProperties": false,
"required": [
"location",
"unit"
]
}
}
}Responses API
{
"type": "function",
"name": "get_weather",
"description": "Определить погоду в моем местоположении",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
},
},
"additionalProperties": false,
"required": [
"location",
"unit"
]
}
}В Responses вызовы инструментов и их результат исполнения — это два различных типа Items, коррелируемых с помощью call_id.
В Responses API определение структурированных выходных данных переместилось из response_format в text.format:
Structured Outputs в ChatCompletions
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5",
messages=[
{
"role": "user",
"content": "Jane, 54 years old",
}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "person",
"strict": True,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1
},
"age": {
"type": "number",
"minimum": 0,
"maximum": 130
}
},
"required": [
"name",
"age"
],
"additionalProperties": False
}
}
},
verbosity="medium",
reasoning_effort="medium"
)Structured Outputs в Responses
response = client.responses.create(
model="gpt-5",
input="Jane, 54 years old",
text={
"format": {
"type": "json_schema",
"name": "person",
"strict": True,
"schema": {
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 1
},
"age": {
"type": "number",
"minimum": 0,
"maximum": 130
}
},
"required": [
"name",
"age"
],
"additionalProperties": False
}
}
}
)Если в вашем приложении есть случаи использования, которые выиграют от нативных инструментов OpenAI, вы можете обновить вызовы инструментов для использования инструментов OpenAI "из коробки".
С Chat Completions вы не можете использовать нативные инструменты OpenAI и должны писать свои собственные.
Инструмент веб-поиска с Chat Completions
import requests
def web_search(query):
r = requests.get(f"https://api.example.com/search?q={query}")
return r.json().get("results", [])
completion = client.chat.completions.create(
model="gpt-5",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who is the current president of France?"}
],
functions=[
{
"name": "web_search",
"description": "Search the web for information",
"parameters": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"]
}
}
]
)Инструмент веб-поиска с Responses
answer = client.responses.create(
model="gpt-5",
input="Who is the current president of France?",
tools=[{"type": "web_search_preview"}]
)
print(answer.output_text)Responses API — это надмножество Chat Completions API. Chat Completions API также будет продолжать поддерживаться. Таким образом, вы можете постепенно внедрять Responses API по желанию. Вы можете перенести пользовательские потоки, которые выиграют от улучшенных моделей рассуждений, на Responses API, сохраняя другие потоки на Chat Completions API, пока не будете готовы к полной миграции.
В качестве лучшей практики мы рекомендуем всем пользователям мигрировать на Responses API, чтобы воспользоваться последними функциями и улучшениями от OpenAI.
На основе отзывов разработчиков от бета-версии Assistants API OpenAI внедрили ключевые улучшения в Responses API, чтобы сделать его более гибким, быстрым и простым в использовании. Responses API представляет будущее направление для создания агентов на OpenAI.
Теперь в Responses API есть объекты, похожие на Assistant и Thread. Подробнее в руководстве по миграции. Начиная с 26 августа 2025 года, OpenAI прекращают поддержку Assistants API, с датой полного отключения 26 августа 2026 года.
Работа с текстом в responses API на примере API OpenAI
С помощью API OpenAI вы можете использовать большую языковую модель для генерации текста на основе запроса, как это делается в ChatGPT. Модели могут генерировать практически любой вид текстового ответа — например, код, математические уравнения, структурированные данные в формате JSON или прозаические тексты, похожие на человеческие. Вот простой пример с использованием API Responses, нашего рекомендуемого API для всех новых проектов.
Генерация текста из простого запроса
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"input": "Напишите сказку на ночь об единороге в одно предложение."
}'Массив контента, сгенерированного моделью, находится в свойстве output ответа. В этом простом примере у нас есть один элемент output, который выглядит так:
[
{
"id": "msg_67b73f697ba4819183a15cc17d011509",
"type": "message",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "Под мягким сиянием луны единорог Луна танцевала по полям мерцающей звездной пыли, оставляя за собой следы снов для каждого спящего ребенка.",
"annotations": []
}
]
}
]Массив output часто содержит более одного элемента! Он может включать вызовы инструментов, данные о токенах рассуждений, сгенерированных моделями рассуждений, и другие элементы. Небезопасно предполагать, что текстовый вывод модели находится в output[0].content[0].text.
Некоторые из официальных SDK включают свойство output_text в ответах модели для удобства, которое агрегирует все текстовые выводы модели в одну строку. Это может быть полезно в качестве сокращения для доступа к текстовому выводу модели.
Помимо обычного текста, вы также можете заставить модель возвращать структурированные данные в формате JSON — эта функция называется Structured Outputs.
Вы можете предоставлять инструкции модели с разными уровнями приоритета, используя параметр API instructions вместе с ролями сообщений.
Параметр instructions дает модели инструкции высокого уровня о том, как она должна вести себя при генерации ответа, включая тон, цели и примеры правильных ответов. Любые инструкции, предоставленные таким образом, будут иметь приоритет над промптом в параметре input.
Генерация текста с инструкциями
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"reasoning": {"effort": "low"},
"instructions": "Говори как пират.",
"input": "Являются ли точки с запятой необязательными в JavaScript?"
}'Пример выше примерно эквивалентен использованию следующих сообщений в массиве input:
Генерация текста с сообщениями, использующими разные роли
curl "https://api.openai.com/v1/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"reasoning": {"effort": "low"},
"input": [
{
"role": "developer",
"content": "Говори как пират."
},
{
"role": "user",
"content": "Являются ли точки с запятой необязательными в JavaScript?"
}
]
}'Обратите внимание, что параметр instructions применяется только к текущему запросу генерации ответа. Если вы управляете состоянием диалога с помощью параметра previous_response_id, инструкции, использованные на предыдущих шагах, не будут присутствовать в контексте.
Спецификация модели OpenAI описывает, как модели присваивают разные уровни приоритета сообщениям с разными ролями.
Роли
- Сообщения с ролью developer — это инструкции, предоставленные разработчиком приложения, которые имеют приоритет перед сообщениями пользователя.
- Сообщения с ролью user — это инструкции, предоставленные конечным пользователем, которые имеют приоритет ниже, чем сообщения разработчика.
- Сообщения, сгенерированные моделью, имеют роль assistant.
Многошаговый диалог может состоять из нескольких сообщений таких типов, а также других типов контента, предоставляемых как вами, так и моделью.
Можно думать о сообщениях developer и user как о функции и её аргументах в языке программирования:
- Сообщения developer предоставляют правила системы и бизнес-логику, как определение функции.
- Сообщения user предоставляют входные данные и конфигурацию, к которым применяются инструкции из сообщений developer, как аргументы функции.
Многоразовые промпты
В панели управления OpenAI вы можете разрабатывать многоразовые промпты, которые можно использовать в API-запросах, вместо того чтобы указывать содержимое промптов в коде. Таким образом, вы можете легче создавать и оценивать свои промпты, а также развертывать улучшенные версии промптов без изменения кода интеграции.
Как это работает:
- Создайте многоразовый промпт в панели управления с заполнителями, такими как {{customer_name}}.
- Используйте промпт в вашем API-запросе с параметром prompt. Объект параметра prompt имеет три свойства, которые можно настроить:
- id — уникальный идентификатор вашего промпта, заданный в панели управления
- version — конкретная версия вашего промпта (по умолчанию используется "текущая" версия, указанная в панели управления)
- variables — карта значений для подстановки переменных в вашем промпте. Значения для подстановки могут быть строками или другими типами сообщений ввода Response, такими как input_image или input_file.
Генерация текста с шаблоном промпта
curl https://api.openai.com/v1/responses \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
-d '{
"model": "gpt-5",
"prompt": {
"id": "pmpt_abc123",
"version": "2",
"variables": {
"customer_name": "Jane Doe",
"product": "40oz juice box"
}
}
}'Вызов функций (Function calling) на примере Responses API OpenAI
Вызов функций (также известный как вызов инструментов, Function Calling, Tool Calling) предоставляет мощный и гибкий способ для моделей взаимодействовать с внешними системами и получать доступ к данным за пределами их обучающих данных. Мы покажем, как использовать функциональные инструменты (определяемые JSON-схемой) и пользовательские инструменты, которые работают с текстовыми входами и выходами в свободной форме.
Инструменты — функциональность, которую мы предоставляем модели
Функция или инструмент абстрактно обозначает часть функциональности, о которой мы сообщаем модели, что она может её использовать. Когда модель генерирует ответ на запрос, она может решить, что ей нужны данные или функциональность, предоставляемая инструментом, чтобы решить поставленную задачу.
Вы можете предоставить модели доступ к инструментам, которые:
- Получают сегодняшнюю погоду для местоположения
- Получают данные аккаунта для заданного идентификатора пользователя
- Оформляют возврат средств за потерянный заказ
- Или что-либо еще, что вы хотите, чтобы модель могла знать или делать при ответе на запрос.
Когда мы делаем API-запрос к модели с запросом, мы можем включить список инструментов, которые модель может использовать. Например, если мы хотим, чтобы модель могла отвечать на вопросы о текущей погоде где-либо в мире, мы можем предоставить ей доступ к инструменту get_weather, который принимает location в качестве аргумента.
Вызов функции или вызов инструмента — это особый вид ответа, который мы можем получить от модели, если она анализирует запрос и затем определяет, что для выполнения инструкций в запросе ей необходимо вызвать один из инструментов, которые мы предоставили.
Если модель получает запрос вроде "какая погода в Париже?" в API-запросе, она может ответить на этот запрос вызовом инструмента get_weather с аргументом location со значением Paris.
Выходные данные вызова функции или выходные данные вызова инструмента — это ответ, который генерирует инструмент, используя входные данные из вызова инструмента моделью. Выходные данные вызова инструмента могут быть структурированным JSON или обычным текстом, и они должны содержать ссылку на конкретный вызов инструмента моделью (ссылка по call_id в примерах).
Чтобы завершить наш пример с погодой:
- У модели есть доступ к инструменту
get_weather, который принимаетlocationв качестве аргумента. - В ответ на запрос вроде "какая погода в Париже?" модель возвращает вызов инструмента, который содержит аргумент
locationсо значениемParis. - Наш выход вызова инструмента может быть JSON-структурой вроде
{"temperature": "25", "unit": "C"}, указывающей на текущую температуру 25 градусов.
Затем мы отправляем обратно модели определение инструмента, исходный запрос, вызов инструмента моделью и выходные данные вызова инструмента, чтобы наконец получить текстовый ответ вроде:
Сегодня в Париже погода 25°C.Функции vs. инструменты
- Функция — это конкретный вид инструмента, определяемый JSON-схемой. Определение функции позволяет модели передавать данные в ваше приложение, где ваш код может получить доступ к данным или выполнить действия, предложенные моделью.
- Помимо функциональных инструментов, существуют custom tools, которые работают с текстовыми входами и выходами в свободной форме.
- Также существуют встроенные инструменты, которые являются частью платформы OpenAI. Эти инструменты позволяют модели искать в интернете, выполнять код, получать доступ к функциональности MCP-сервера и многое другое.
Поток вызова инструментов
Вызов инструментов — это многоэтапный диалог между вашим приложением и моделью через API OpenAI. Поток вызова инструментов состоит из пяти основных шагов:
- Сделать запрос к модели с описанием задачи и описанием инструментов, которые она может вызвать
- Получить вызов инструмента от модели
- Выполнить код на стороне приложения с входными данными из вызова инструмента
- Сделать второй запрос к модели с выходными данными инструмента (результатом исполнения инструмента)
- Получить окончательный ответ от модели (или задачу на следующий вызовов инструментов)
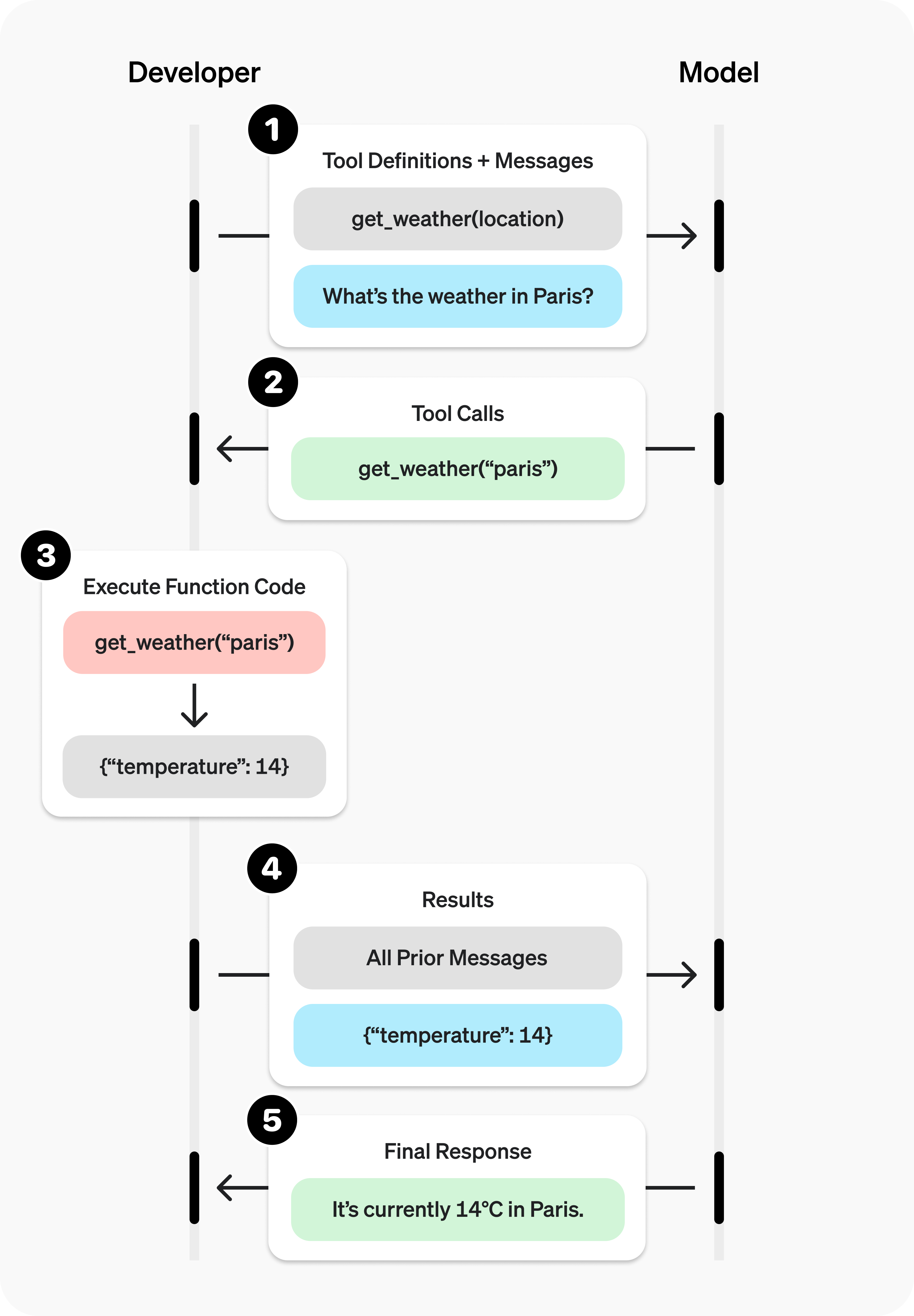
Рис. 1. Схема шагов вызова функций
Пример инструмента
Давайте рассмотрим полный поток вызова инструмента для функции get_horoscope, которая получает ежедневный гороскоп для астрологического знака.
Код на python
from openai import OpenAI
import json
client = OpenAI()
# 1. Определяем список вызываемых инструментов для модели
tools = [
{
"type": "function",
"name": "get_horoscope",
"description": "Получить сегодняшний гороскоп для астрологического знака.",
"parameters": {
"type": "object",
"properties": {
"sign": {
"type": "string",
"description": "Астрологический знак, например, Телец или Водолей",
},
},
"required": ["sign"],
},
},
]
def get_horoscope(sign):
return f"{sign}: Во вторник вы подружитесь с детенышем выдры."
# Создаем список входных данных, который будем дополнять со временем
input_list = [
{"role": "user", "content": "Какой у меня гороскоп? Я Водолей."}
]
# 2. Запрашиваем модель с определенными инструментами
response = client.responses.create(
model="gpt-5",
tools=tools,
input=input_list,
)
# Сохраняем выходные данные вызовов функций для последующих запросов
input_list += response.output
for item in response.output:
if item.type == "function_call":
if item.name == "get_horoscope":
# 3. Выполняем логику функции для get_horoscope
horoscope = get_horoscope(json.loads(item.arguments)["sign"])
# 4. Предоставляем результаты вызова функции модели
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps({
"horoscope": horoscope
})
})
print("Финальный ввод:")
print(input_list)
response = client.responses.create(
model="gpt-5",
instructions="Отвечайте только гороскопом, сгенерированным инструментом.",
tools=tools,
input=input_list,
)
# 5. Модель должна дать ответ!
print("Финальный вывод:")
print(response.model_dump_json(indent=2))
print("\n" + response.output_text)Код на JavaScript
import OpenAI from "openai";
const openai = new OpenAI();
// 1. Определяем список вызываемых инструментов для модели
const tools = [
{
type: "function",
name: "get_horoscope",
description: "Получить сегодняшний гороскоп для астрологического знака.",
parameters: {
type: "object",
properties: {
sign: {
type: "string",
description: "Астрологический знак, например, Телец или Водолей",
},
},
required: ["sign"],
},
},
];
function getHoroscope(sign) {
return `${sign}: Во вторник вы подружитесь с детенышем выдры.`;
}
// Создаем список входных данных, который будем дополнять со временем
let input = [
{ role: "user", content: "Какой у меня гороскоп? Я Водолей." },
];
// 2. Запрашиваем модель с определенными инструментами
let response = await openai.responses.create({
model: "gpt-5",
tools,
input,
});
response.output.forEach((item) => {
if (item.type === "function_call") {
if (item.name === "get_horoscope") {
// 3. Выполняем логику функции для get_horoscope
const horoscope = getHoroscope(JSON.parse(item.arguments).sign);
// 4. Предоставляем результаты вызова функции модели
input.push({
type: "function_call_output",
call_id: item.call_id,
output: JSON.stringify({
horoscope
})
});
}
}
});
console.log("Финальный ввод:");
console.log(JSON.stringify(input, null, 2));
response = await openai.responses.create({
model: "gpt-5",
instructions: "Отвечайте только гороскопом, сгенерированным инструментом.",
tools,
input,
});
// 5. Модель должна дать ответ!
console.log("Финальный вывод:");
console.log(JSON.stringify(response.output, null, 2));Примечание: Для моделей рассуждений, таких как GPT-5 или o4-mini, любые элементы рассуждений, возвращаемые в ответах модели с вызовами инструментов, также должны быть переданы обратно с выходными данными вызовов инструментов.
Определение функций
Функции могут быть заданы в параметре tools каждого API-запроса. Функция определяется своей схемой, которая сообщает модели, что она делает и какие входные аргументы ожидает. Определение функции имеет следующие свойства:
| Поле | Описание |
|---|---|
| type | Должно быть всегда function |
| name | Имя функции (например, get_weather) |
| description | Подробности о том, когда и как использовать функцию |
| parameters | JSON-схема, определяющая входные аргументы функции |
| strict | Следует ли применять строгий режим для вызова функции |
Пример определения функции для get_weather
{
"type": "function",
"name": "get_weather",
"description": "Получает текущую погоду для заданного местоположения.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Город и страна, например, Богота, Колумбия"
},
"units": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Единицы измерения температуры, в которых будет возвращена температура."
}
},
"required": ["location", "units"],
"additionalProperties": false
},
"strict": true
}Поскольку parameters определяются JSON-схемой, вы можете использовать многие её богатые возможности, такие как типы свойств, перечисления, описания, вложенные объекты и рекурсивные объекты.
Хорошие практики для определения функций
-
Пишите четкие и подробные названия функций, описания параметров и инструкции.
- Явно описывайте назначение функции и каждого параметра (и его формат), а также что представляет собой выходной результат.
- Используйте системный промпт, чтобы описать, когда (и когда не) использовать каждую функцию. Обычно говорите модели точно, что делать.
- Включайте примеры и крайние случаи, особенно для исправления повторяющихся ошибок. (Добавление примеров может ухудшить производительность для моделей рассуждений.)
-
Применяйте лучшие практики программной инженерии.
- Делайте функции очевидными и интуитивно понятными. (принцип наименьшего удивления)
- Используйте перечисления и структуру объектов, чтобы сделать невозможными недопустимые состояния. (например,
toggle_light(on: bool, off: bool)допускает недопустимые вызовы) - Пройдите тест на стажера. Может ли стажер/человек правильно использовать функцию, имея только то, что вы дали модели? (Если нет, какие вопросы они вам задают? Добавьте ответы в промпт.)
-
Разгрузите модель и используйте код, где это возможно.
- Не заставляйте модель заполнять аргументы, которые вы уже знаете. Например, если у вас уже есть
order_idна основе предыдущего меню, не делайте параметрorder_id— вместо этого, не используйте параметрыsubmit_refund()и передавайтеorder_idс помощью кода. - Объединяйте функции, которые всегда вызываются последовательно. Например, если вы всегда вызываете
mark_location()послеquery_location(), просто переместите логику пометки в вызов функции запроса.
- Не заставляйте модель заполнять аргументы, которые вы уже знаете. Например, если у вас уже есть
-
Сохраняйте количество функций небольшим для повышения точности.
- Оценивайте свою производительность с разным количеством функций.
- Стремитесь к количеству функций менее 20 за один раз, хотя это всего лишь мягкая рекомендация.
-
Используйте ресурсы OpenAI.
- Генерируйте и итерируйте схемы функций в Playground.
- Рассмотрите возможность тонкой настройки для повышения точности вызова функций для большого количества функций или сложных задач. (сборник рецептов)
Под капотом функции внедряются в системное сообщение в синтаксисе, на котором обучалась модель. Это означает, что функции учитываются в пределах контекстного лимита модели и тарифицируются как входные токены. Если вы сталкиваетесь с ограничениями по токенам, мы рекомендуем ограничить количество функций или длину описаний, которые вы предоставляете для параметров функций.
Обработка вызовов функций
Когда модель вызывает функцию, вы должны выполнить её и вернуть результат. Поскольку ответы модели могут включать ноль, одну или несколько вызовов, лучшей практикой является предположение, что их несколько.
Массив output ответа содержит запись с type, имеющим значение function_call. Каждая запись содержит call_id (используемый позже для отправки результата функции), name и JSON-кодированные arguments.
Пример ответа с несколькими вызовами функций
[
{
"id": "fc_12345xyz",
"call_id": "call_12345xyz",
"type": "function_call",
"name": "get_weather",
"arguments": "{\"location\":\"Paris, France\"}"
},
{
"id": "fc_67890abc",
"call_id": "call_67890abc",
"type": "function_call",
"name": "get_weather",
"arguments": "{\"location\":\"Bogotá, Colombia\"}"
},
{
"id": "fc_99999def",
"call_id": "call_99999def",
"type": "function_call",
"name": "send_email",
"arguments": "{\"to\":\"bob@email.com\",\"body\":\"Hi bob\"}"
}
]Выполнение вызовов функций и добавление результатов
На Python
for tool_call in response.output:
if tool_call.type != "function_call":
continue
name = tool_call.name
args = json.loads(tool_call.arguments)
result = call_function(name, args)
input_messages.append({
"type": "function_call_output",
"call_id": tool_call.call_id,
"output": str(result)
})На JavaScript
for (const toolCall of response.output) {
if (toolCall.type !== "function_call") {
continue;
}
const name = toolCall.name;
const args = JSON.parse(toolCall.arguments);
const result = callFunction(name, args);
input.push({
type: "function_call_output",
call_id: toolCall.call_id,
output: result.toString()
});
}В приведенном выше примере у нас есть гипотетическая функция call_function для маршрутизации каждого вызова. Вот возможная реализация:
Выполнение вызовов функций и добавление результатов
def call_function(name, args):
if name == "get_weather":
return get_weather(**args)
if name == "send_email":
return send_email(**args)Форматирование результатов
Результат должен быть строкой, но формат зависит от вас (JSON, коды ошибок, обычный текст и т. д.). Модель будет интерпретировать эту строку по мере необходимости.
Если ваша функция не имеет возвращаемого значения (например, send_email), просто верните строку, чтобы указать на успех или неудачу. (например, "success")
После добавления результатов в ваш input, вы можете отправить их обратно модели, чтобы получить окончательный ответ.
Отправка результатов обратно модели
response = client.responses.create(
model="gpt-4.1",
input=input_messages,
tools=tools,
)Финальный ответ
"В Париже около 15°C, в Боготе 18°C, и я отправил это письмо Бобу."Дополнительные конфигурации
Выбор инструмента
По умолчанию модель сама определяет, когда и сколько инструментов использовать. Вы можете принудительно задать конкретное поведение с помощью параметра tool_choice.
- Авто: (По умолчанию) Вызвать ноль, одну или несколько функций.
tool_choice: "auto" - Обязательно: Вызвать одну или несколько функций.
tool_choice: "required" - Принудительная функция: Вызвать ровно одну конкретную функцию.
tool_choice: {"type": "function", "name": "get_weather"} - Разрешенные инструменты: Ограничить вызовы инструментов, которые может сделать модель, подмножеством инструментов, доступных модели.
Когда использовать allowed_tools
Возможно, вы захотите настроить список allowed_tools, если хотите сделать доступным только подмножество инструментов для запросов модели, но не изменять список инструментов, которые вы передаете, чтобы максимизировать экономию от кэширования промптов.
"tool_choice": {
"type": "allowed_tools",
"mode": "auto",
"tools": [
{ "type": "function", "name": "get_weather" },
{ "type": "mcp", "server_label": "deepwiki" },
{ "type": "image_generation" }
]
}Вы также можете установить tool_choice в "none", чтобы имитировать поведение передачи без функций.
Параллельный вызов функций
Параллельный вызов функций невозможен при использовании встроенных инструментов.
Модель может выбрать вызов нескольких функций за один ход. Вы можете предотвратить это, установив parallel_tool_calls в false, что гарантирует вызов ровно нуля или одной функции.
Строгий режим
Установка strict в true гарантирует, что вызовы функций надежно соответствуют схеме функции, а не являются попыткой "сделать всё возможное". Мы рекомендуем всегда включать строгий режим.
Под капотом строгий режим работает за счет использования функции Structured Outputs и поэтому вводит несколько требований:
additionalPropertiesдолжно быть установлено вfalseдля каждого объекта вparameters.- Все поля в
propertiesдолжны быть помечены какrequired.
Вы можете обозначить необязательные поля, добавив null в качестве варианта type (см. пример ниже).
Строгий режим включен
{
"type": "function",
"name": "get_weather",
"description": "Получает текущую погоду для заданного местоположения.",
"strict": true,
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Город и страна, например, Богота, Колумбия"
},
"units": {
"type": ["string", "null"],
"enum": ["celsius", "fahrenheit"],
"description": "Единицы измерения температуры, в которых будет возвращена температура."
}
},
"required": ["location", "units"],
"additionalProperties": false
}
}Строгий режим отключен
{
"type": "function",
"name": "get_weather",
"description": "Получает текущую погоду для заданного местоположения.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Город и страна, например, Богота, Колумбия"
},
"units": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "Единицы измерения температуры, в которых будет возвращена температура."
}
},
"required": ["location"],
}
}Потоковая передача
Потоковая передача может использоваться для отображения прогресса, показывая, какая функция вызывается по мере заполнения её аргументов, и даже отображая аргументы в реальном времени.
Потоковая передача вызовов функций очень похожа на потоковую передачу обычных ответов: вы устанавливаете stream в true и получаете разные объекты event.
Потоковая передача вызовов функций
from openai import OpenAI
client = OpenAI()
tools = [{
"type": "function",
"name": "get_weather",
"description": "Получить текущую температуру для заданного местоположения.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Город и страна, например, Богота, Колумбия"
}
},
"required": [
"location"
],
"additionalProperties": False
}
}]
stream = client.responses.create(
model="gpt-4.1",
input=[{"role": "user", "content": "Какая погода сегодня в Париже?"}],
tools=tools,
stream=True
)
for event in stream:
print(event)События вывода
{"type":"response.output_item.added","response_id":"resp_1234xyz","output_index":0,"item":{"type":"function_call","id":"fc_1234xyz","call_id":"call_1234xyz","name":"get_weather","arguments":""}}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":"{\""}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":"location"}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":"\":\""}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":"Paris"}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":","}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":" France"}
{"type":"response.function_call_arguments.delta","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"delta":"\"}"}
{"type":"response.function_call_arguments.done","response_id":"resp_1234xyz","item_id":"fc_1234xyz","output_index":0,"arguments":"{\"location\":\"Paris, France\"}"}
{"type":"response.output_item.done","response_id":"resp_1234xyz","output_index":0,"item":{"type":"function_call","id":"fc_1234xyz","call_id":"call_1234xyz","name":"get_weather","arguments":"{\"location\":\"Paris, France\"}"}}Вместо того чтобы агрегировать фрагменты в одну строку content, вы агрегируете фрагменты в закодированный JSON-объект arguments.
Когда модель вызывает одну или несколько функций, генерируется событие типа response.output_item.added для каждого вызова функции, содержащее следующие поля:
| Поле | Описание |
|---|---|
| response_id | Идентификатор ответа, к которому относится вызов функции |
| output_index | Индекс элемента вывода в ответе. Представляет отдельные вызовы функций. |
| item | Элемент вызова функции в процессе, который включает имя, аргументы и id |
Затем вы получите серию событий типа response.function_call_arguments.delta, которые будут содержать delta поля arguments. Эти события содержат следующие поля:
| Поле | Описание |
|---|---|
| response_id | Идентификатор ответа, к которому относится вызов функции |
| item_id | Идентификатор элемента вызова функции, к которому относится дельта |
| output_index | Индекс элемента вывода в ответе. Представляет отдельные вызовы функций. |
| delta | Дельта поля аргументов. |
Ниже приведен фрагмент кода, демонстрирующий, как агрегировать delta в финальный объект tool_call.
Накопление дельт вызовов инструментов
final_tool_calls = {}
for event in stream:
if event.type == 'response.output_item.added':
final_tool_calls[event.output_index] = event.item;
elif event.type == 'response.function_call_arguments.delta':
index = event.output_index
if final_tool_calls[index]:
final_tool_calls[index].arguments += event.deltaНакопленный final_tool_calls[0]
{
"type": "function_call",
"id": "fc_1234xyz",
"call_id": "call_2345abc",
"name": "get_weather",
"arguments": "{\"location\":\"Paris, France\"}"
}Когда модель завершает вызов функций, генерируется событие типа response.function_call_arguments.done. Это событие содержит весь вызов функции, включая следующие поля:
| Поле | Описание |
|---|---|
| response_id | Идентификатор ответа, к которому относится вызов функции |
| output_index | Индекс элемента вывода в ответе. Представляет отдельные вызовы функций. |
| item | Элемент вызова функции, который включает имя, аргументы и id |
Кастомные инструменты (Custom Tools)
Кастомные инструменты работают почти так же, как инструменты на основе JSON-схемы. Но вместо того, чтобы предоставлять модели явные инструкции о том, какой ввод требуется вашему инструменту, модель может передать произвольную строку обратно вашему инструменту в качестве ввода. Это полезно, чтобы избежать ненужной обертки ответа в JSON или применить пользовательскую грамматику к ответу (подробнее об этом ниже).
Следующий пример кода показывает создание кастомного инструмента, который ожидает получить строку текста, содержащую код Python, в качестве ответа.
Пример вызова кастомного инструмента
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5",
input="Используй инструмент code_exec, чтобы вывести hello world в консоль.",
tools=[
{
"type": "custom",
"name": "code_exec",
"description": "Выполняет произвольный код Python.",
}
]
)
print(response.output)Как и раньше, массив output будет содержать вызов инструмента, сгенерированный моделью. Только на этот раз входные данные вызова инструмента передаются в виде обычного текста.
[
{
"id": "rs_6890e972fa7c819ca8bc561526b989170694874912ae0ea6",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "ctc_6890e975e86c819c9338825b3e1994810694874912ae0ea6",
"type": "custom_tool_call",
"status": "completed",
"call_id": "call_aGiFQkRWSWAIsMQ19fKqxUgb",
"input": "print(\"hello world\")",
"name": "code_exec"
}
]Контекстно-свободные грамматики
Контекстно-свободная грамматика (CFG) — это набор правил, определяющих, как генерировать допустимый текст в заданном формате. Для пользовательских инструментов вы можете предоставить CFG, которая будет ограничивать текстовый ввод модели для кастомного инструмента.
Вы можете предоставить пользовательскую CFG, используя параметр grammar при настройке пользовательского инструмента. В настоящее время мы поддерживаем два синтаксиса CFG при определении грамматик: lark и regex.
Пример контекстно-свободной грамматики Lark
from openai import OpenAI
client = OpenAI()
grammar = """
start: expr
expr: term (SP ADD SP term)* -> add
| term
term: factor (SP MUL SP factor)* -> mul
| factor
factor: INT
SP: " "
ADD: "+"
MUL: "*"
%import common.INT
"""
response = client.responses.create(
model="gpt-5",
input="Используй инструмент math_exp, чтобы сложить четыре и четыре.",
tools=[
{
"type": "custom",
"name": "math_exp",
"description": "Создает допустимые математические выражения",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": grammar,
},
}
]
)
print(response.output)Выходные данные инструмента должны соответствовать CFG Lark, которую вы определили:
[
{
"id": "rs_6890ed2b6374819dbbff5353e6664ef103f4db9848be4829",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "ctc_6890ed2f32e8819daa62bef772b8c15503f4db9848be4829",
"type": "custom_tool_call",
"status": "completed",
"call_id": "call_pmlLjmvG33KJdyVdC4MVdk5N",
"input": "4 + 4",
"name": "math_exp"
}
]Грамматики определяются с использованием варианта Lark. Выборка модели ограничивается с помощью LLGuidance. Некоторые функции Lark не поддерживаются:
- Просмотры вперед и назад в регулярных выражениях лексического анализатора
- Ленивые модификаторы (
*?,+?,??) в регулярных выражениях лексического анализатора - Приоритеты терминалов
- Шаблоны
- Импорты (кроме встроенного
%import common) %declare
Мы рекомендуем использовать Lark IDE для экспериментов с пользовательскими грамматиками.
Старайтесь сделать вашу грамматику максимально простой. API OpenAI может вернуть ошибку, если грамматика слишком сложная, поэтому убедитесь, что ваша желаемая грамматика совместима, прежде чем использовать её в API.
Грамматики Lark могут быть сложными для совершенствования. Хотя простые грамматики работают наиболее надежно, сложные грамматики часто требуют итераций по самому определению грамматики, промпту и описанию инструмента, чтобы убедиться, что модель не выходит за пределы распределения.
Правильные и неправильные шаблоны
Правильно (одиночный, ограниченный терминал):
start: SENTENCE
SENTENCE: /[A-Za-z, ]*(the hero|a dragon|an old man|the princess)[A-Za-z, ]*(fought|saved|found|lost)[A-Za-z, ]*(a treasure|the kingdom|a secret|his way)[A-Za-z, ]*\./Не делайте так (разделение по правилам/терминалам). Это попытка позволить правилам разделять свободный текст между терминалами. Лексический анализатор жадно сопоставит части свободного текста, и вы потеряете контроль:
start: sentence
sentence: /[A-Za-z, ]+/ subject /[A-Za-z, ]+/ verb /[A-Za-z, ]+/ object /[A-Za-z, ]+/Терминалы в нижнем регистре не влияют на то, как терминалы вырезаются из ввода — только определения терминалов. Когда вам нужен "свободный текст между якорями", сделайте его одним гигантским терминалом regex, чтобы лексический анализатор сопоставил его ровно один раз с той структурой, которую вы намеревались.
Терминалы vs. правила
Lark использует терминалы для токенов лексического анализатора (по соглашению, ЗАГЛАВНЫЕ) и правила для продукций синтаксического анализатора (по соглашению, строчные). Наиболее практичный способ оставаться в поддерживаемом подмножестве и избегать сюрпризов — держать вашу грамматику простой и явной, а также использовать терминалы и правила с четким разделением обязанностей.
Синтаксис регулярных выражений, используемый терминалами, — это синтаксис Rust regex crate, а не Python re модуль.
Ключевые идеи и лучшие практики
Лексический анализатор работает перед синтаксическим анализатором
Терминалы сопоставляются лексическим анализатором (жадно / побеждает самое длинное совпадение) до применения логики правил CFG. Если вы попытаетесь "формировать" терминал, разделяя его на несколько правил, лексический анализатор не может руководствоваться этими правилами — только регулярными выражениями терминалов.
Предпочитайте один терминал, когда вы вырезаете текст из свободных фрагментов
Если вам нужно распознать шаблон, встроенный в произвольный текст (например, естественный язык с "чем угодно" между якорями), выразите это как один терминал. Не пытайтесь чередовать терминалы свободного текста с правилами синтаксического анализатора; жадный лексический анализатор не будет уважать ваши намеченные границы, и очень вероятно, что модель выйдет за пределы распределения.
Используйте правила для композиции дискретных токенов
Правила идеальны, когда вы комбинируете четко разграниченные терминалы (числа, ключевые слова, знаки препинания) в более крупные структуры. Они не подходят для ограничения "вещей между" двумя терминалами.
Держите терминалы простыми, ограниченными и самодостаточными
Отдавайте предпочтение явным классам символов и ограниченным квантификаторам ({0,10}, а не неограниченному * везде). Если вам нужен "любой текст до точки", предпочтите что-то вроде /[^.\n]{0,10}*\./, а не /.+\./, чтобы избежать неконтролируемого роста.
Используйте правила для комбинирования токенов, а не для управления внутренностями regex
Хороший пример использования правил:
start: expr
NUMBER: /[0-9]+/
PLUS: "+"
MINUS: "-"
expr: term (("+"|"-") term)*
term: NUMBERОбрабатывайте пробелы явно
Не полагайтесь на открытые директивы %ignore. Использование неограниченных директив игнорирования может привести к тому, что грамматика станет слишком сложной и/или модель выйдет за пределы распределения. Предпочитайте вставлять явные терминалы везде, где разрешены пробелы.
Устранение неполадок
- Если API отклоняет грамматику из-за её сложности, упростите правила и терминалы и удалите неограниченные
%ignore. - Если пользовательские инструменты вызываются с неожиданными токенами, убедитесь, что терминалы не перекрываются; проверьте жадный лексический анализатор.
- Когда модель "выходит за пределы распределения" (проявляется как чрезмерно длинные или повторяющиеся выходные данные, синтаксически правильные, но семантически неправильные):
- Ужесточите грамматику.
- Итерируйте промпт (добавьте примеры few-shot) и описание инструмента (объясните грамматику и дайте инструкции модели следовать ей и соответствовать ей).
- Экспериментируйте с более высоким уровнем усилий рассуждений (например, увеличьте с medium до high).
Regex CFG
Пример контекстно-свободной грамматики Regex
from openai import OpenAI
client = OpenAI()
grammar = r"^(?P<month>January|February|March|April|May|June|July|August|September|October|November|December)\s+(?P<day>\d{1,2})(?:st|nd|rd|th)?\s+(?P<year>\d{4})\s+at\s+(?P<hour>0?[1-9]|1[0-2])(?P<ampm>AM|PM)$"
response = client.responses.create(
model="gpt-5",
input="Используй инструмент timestamp, чтобы сохранить метку времени для 7 августа 2025 года в 10:00.",
tools=[
{
"type": "custom",
"name": "timestamp",
"description": "Сохраняет метку времени в формате дата + время в 24-часовом формате.",
"format": {
"type": "grammar",
"syntax": "regex",
"definition": grammar,
},
}
]
)
print(response.output)Выходные данные инструмента должны соответствовать Regex CFG, которую вы определили:
[
{
"id": "rs_6894f7a3dd4c81a1823a723a00bfa8710d7962f622d1c260",
"type": "reasoning",
"content": [],
"summary": []
},
{
"id": "ctc_6894f7ad7fb881a1bffa1f377393b1a40d7962f622d1c260",
"type": "custom_tool_call",
"status": "completed",
"call_id": "call_8m4XCnYvEmFlzHgDHbaOCFlK",
"input": "August 7th 2025 at 10AM",
"name": "timestamp"
}
]Как и в случае с синтаксисом Lark, регулярные выражения используют синтаксис Rust regex crate, а не модуль Python re модуль.
Некоторые функции Regex не поддерживаются:
- Просмотры вперед и назад
- Ленивые модификаторы (
*?,+?,??)
Ключевые идеи и лучшие практики
Шаблон должен быть в одной строке
Если вам нужно сопоставить символ новой строки во входных данных, используйте экранированную последовательность \n. Не используйте многострочный режим, который позволяет шаблонам занимать несколько строк.
Предоставляйте регулярное выражение в виде обычной строки шаблона
Не заключайте шаблон в //.
УФФ! Если вы дочитали этот раздел про грамматики, то вы матерый волк. Удачи вам в написании ваших заклинаний и в заклинании LLM!